







 本文介绍了冒泡排序和快速排序的基本原理。冒泡排序是通过两两比较来排序,时间复杂度为O(n^2),适合少量数据,而快速排序是冒泡排序的优化,采用基准数字划分,递归排序,平均时间复杂度为O(nlogn),适用于大量数据。在稳定性上,冒泡排序稳定,快速排序则不稳定。
本文介绍了冒泡排序和快速排序的基本原理。冒泡排序是通过两两比较来排序,时间复杂度为O(n^2),适合少量数据,而快速排序是冒泡排序的优化,采用基准数字划分,递归排序,平均时间复杂度为O(nlogn),适用于大量数据。在稳定性上,冒泡排序稳定,快速排序则不稳定。
一冒泡排序与快速排序的简介
1 冒泡排序
冒泡排序:
冒泡排序是两个相邻的数两两进行比较:
如下图所示
第一轮排序后找出来了最大的数,并将最大的数放在了最后:
第二轮排序后找出来了最大的数,并将最大的数放在了最后:
。
。
。
进行n-1次排序后确定了位置:
那么通过下图可以看出最后几轮并没有对数字进行位置移动但是还是进行了程序的运算,那么这样就浪费了程序的运算,及空间的浪费。
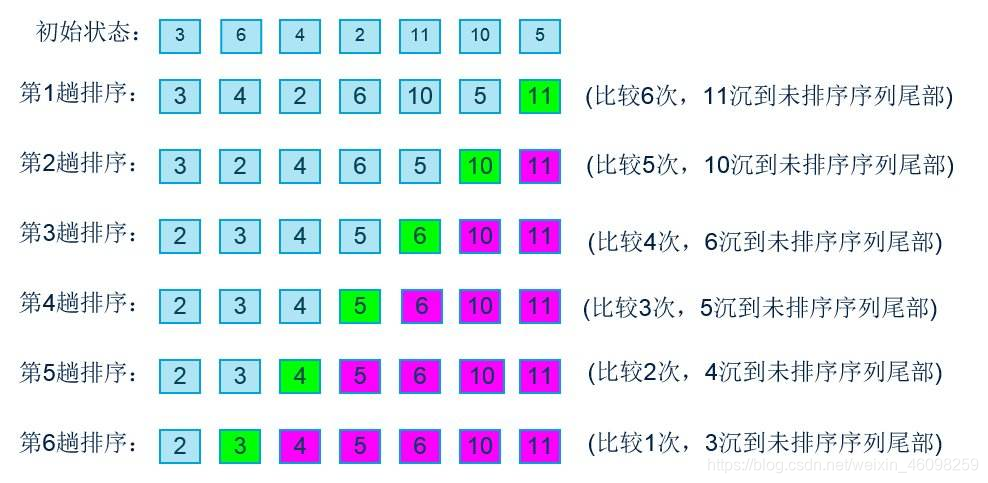
在这里插入代码:
arr = [3,6,4,2,11,10,5]
for i in range (0,len(arr)-1):
for j in range(0,len(arr)-i-1):
if arr[j]>arr[j+1]:
arr[j],arr[j+1]=arr[j+1],arr[j]
print(arr)
可看出是两两排序。
2 快速排序
快速排序
快速排序是对冒泡排序的优化
先找一个基准数字,及两个指针。
一个指针从左往右
一个指针从右往左
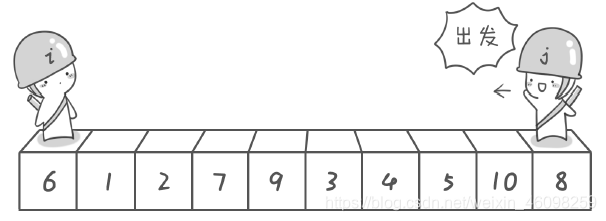
假定基准数字为中间的数字,那
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 9654
9654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









