







1、实习期间遇到文本处理的任务,需求倒是不难。正好有重新拾起python来解决这个问题,使用到标题的两个库,仅此做个记录。
主要任务就是文本中语言的分类,这个语言分类可以有很多语言种类混合。设计了两个测试用例:
text1 = """这是一段示例文本,这是一段示例文本,한국어, 중국어"""
text2 = "这是一段示例文本,这是一段示例文本,한국어, 중국어, 한국어, 중국어한국어, 중국어한국어, 중국어한국어, 중국어한국어, 중국어,Hello world,Hello worldHello worldHello worldHello world,这是一段示例文本这是一段示例文本,包含多种语言。"
明显可以看出text1涉及中文和韩文,text2涉及中文、韩文和英文。那么至少在分类的过程中要得出准确的分类数量。
2、代码编写
然后就是使用langid和langdetect进行文本处理,不过需要提前安装这两个库。
import langid
from langdetect import detect_langs
from collections import defaultdict
def translationByLangid(text):
sentences = [text]
for sentence in sentences:
line = sentence.strip()
res = langid.classify(line)
print(res)
def translationByLangdetect(text):
# 使用 langdetect 库来检测文本中的语言
detections = detect_langs(text)
# 使用 defaultdict 来统计各种语言出现的频率
language_counts = defaultdict(float) # 使用 float 类型来累加概率
# 将检测到的语言及其概率记录到 defaultdict 中
for detection in detections:
lang = detection.lang
prob = detection.prob
language_counts[lang] += prob # 使用概率来计数,因为每个检测到的语言可能有多个检测结果
# 按照频率降序排列
sorted_counts = sorted(language_counts.items(), key=lambda x: x[1], reverse=True)
return sorted_counts
if __name__ == '__main__':
text1 = """这是一段示例文本,这是一段示例文本,한국어, 중국어"""
text2 = "这是一段示例文本,这是一段示例文本,한국어, 중국어, 한국어, 중국어한국어, 중국어한국어, 중국어한국어, 중국어한국어, 중국어,Hello world,Hello worldHello worldHello worldHello world,这是一段示例文本这是一段示例文本,包含多种语言。"
print("langid方式###################################")
translationByLangid(text1)
translationByLangid(text2)
print("langdetect方式################################")
print(translationByLangdetect(text1))
print(translationByLangdetect(text2))代码的逻辑很简单,langid就是直接调用classify方法处理文本,langdetect中使用defaultdict进行各语言出现的频率。
3、运行结果
3.1、运行结果其实存在不确定性,可能是我的测试文本比较短的原因。以下3张图是我运行3次得出的结果。
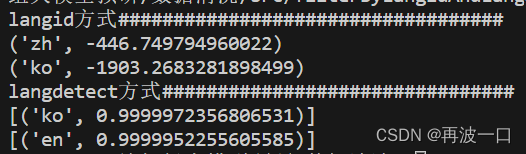
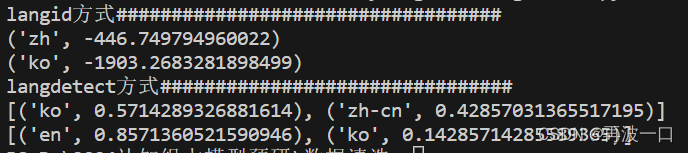

3.2、结果分析:
langid得出的结果是稳定的,但似乎没有出现该有的语言统计数量。有说法说langid是输出占比最大的语言,但是我还不知道是真是假。
langdetect输出就不稳定了,并且与langid所得结果似乎匹配不上。
3.3、可能对于混合数据的判别不大稳定,所以再添加了一个测试用例:
text3="这段话中含有很少的英文English,只要就是想测试语言频数差别很大的时候的判定结果是否稳定。"
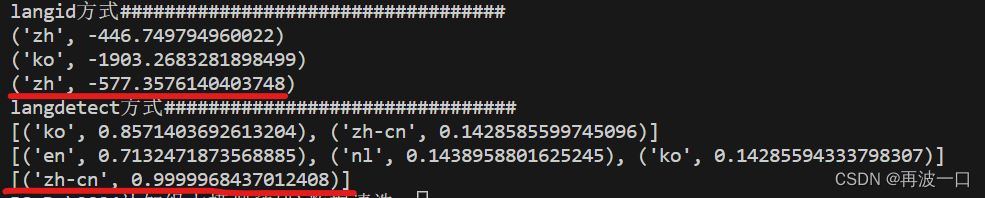
运行多次后的结果仍是对的。
4、遗留和总结
langid和langdetect有一定的作用空间,对于太混合的数据不大友好。
至于langid得出的置信度如何理解,还没弄明白为何负数还那么大,希望有懂哥讲解一下。
这次的分享就到这了,下次再见!

















 1783
1783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









