






 文章详细描述了如何通过定义音频路径和prompt,结合预训练的AutoTokenizer处理音频和文本,将它们转化为模型可接受的输入。重点涉及tokenizer编码、音频特征处理和模型输入的构建过程,以及可能存在的优化问题。
文章详细描述了如何通过定义音频路径和prompt,结合预训练的AutoTokenizer处理音频和文本,将它们转化为模型可接受的输入。重点涉及tokenizer编码、音频特征处理和模型输入的构建过程,以及可能存在的优化问题。
1、首先需要定义一个音频文件路径和一个特殊的prompt字符串,然后,在创建查询时,将音频路径和prompt字符串进行结合起来,并使用tokenizer对齐进行处理,接下来,将处理后的输入转换为pytorch张量,并将其送入到模型当中。
a、加载预训练AutoTokenizer模型:
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
b、将内容处理称模型能接受的输入形式,将raw_text += f"\n{im_start}user\n{query}{im_end}\n{im_start}assistant\n"这种形式的信息转换成模型可以理解的张量形式。
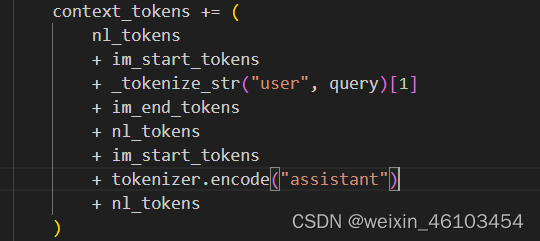
b_1:其中nl_token是经过tokenizer.encode将“\n”符变成对应的id,im_start_tokens代表的是开始token,im_end_tokens代表的是结束的token,通通过添加这些特殊标记,可以更好地控制模型生成文本的过程,并确保生成的结果符合预期。其中_tokenize_str()如下所示。

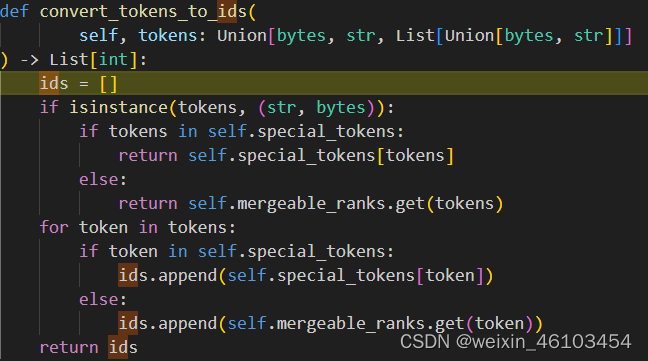
通过使用tokenizer.encode编码将内容以及role变成计算机可以理解的向量。主要流程实现如下图所示,先通过tokenizer.encode将system,user,assistant等内容转换成词库中的token,再将token通过convert_tokens_to_ids映射到对应的id。

在_tokenize_str()中的audio_info表示的是音频的梅尔普特征以及音频长度经过CNN转换之后的音频长度,以及加入了起始和结束标记加的音频长度。但是mel却没有经过cnn层,直接通过音频长度进行剪枝,这是我不能理解的地方,这样做减少了计算量,但可能带来的问题是音频帧的丢失,如果有大佬有答案可以在评论区下面讲解一下,真心求解,啊哈哈哈。还有一个问题是,再没进行一次process_audio的调用,就会导致音频的二次提取梅尔普特征的计算,在数据量较大的情况下可能会导致算力的浪费。
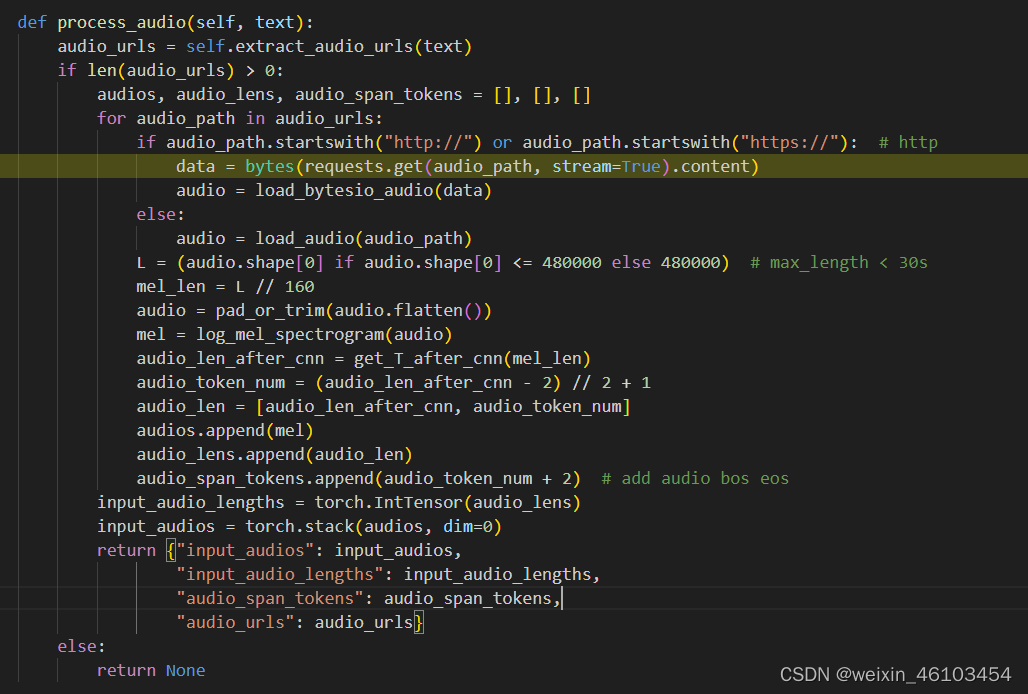
最后,数据的处理部分到此结束,最终输入到模型的process_audio获取到的音频相关的特征信息,以及通过context_tokens获取的与提示相关的内容信息。以上问题有解答的可以联系我哟,第一个解答成功的有奖品。















 428
428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









