一、概要
- 逻辑回归(Logistic regression,简称LR),一种分类算法,常用于二分类,也可用于多分类。
- 逻辑回归模型
二、主要知识点
- LR的最终目的是找到w的最佳取值,使得预测结果更准确。


sigmoid

- 函数图像如下:
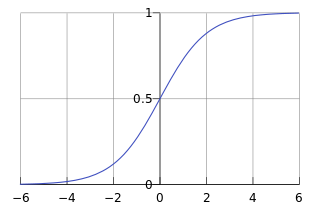
- sigmod将预测结果限定在[0-1]之间,正好可以作为该结果出现的概率
似然函数和损失函数
- LR中,w的取值是通过最大化似然函数或最小化损失函数得到的,常用梯度下降,牛顿法等。
参考链接
三、code实战
- 绘制散点图:plt.scatter()
import matplotlib.pyplot as plt
plt.scatter(x, y, s=None, c=None, marker=None, cmap=None,
norm=None, vmin=None, vmax=None, alpha=None,
linewidths=None, verts=None, edgecolors=None, *,
data=None, **kwargs)
- 参数说明:
x,y:实数或数组,所有散点的x,y值
s:实数或数组,点的面积
c:字符或数组,点的颜色,默认是蓝色‘b’
marker:点的形状样式,默认是’o’(圆点)
norm:将数据亮度转化到0-1之间,只有c是一个浮点数的数组的时候才使用。默认colors.Normalize
vmin,vmax:实数,norm存在时忽略。用来进行亮度数据的归一化
alpha实数,0-1之间
linewidths:实数或数组,点的长度
- 划分数据集:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(iris_features_part, iris_target_part, test_size = 0.2, random_state = 2020)
- 导入逻辑回归模型:
from sklearn.linear_model import LogisticRegression
## 定义 逻辑回归模型
clf = LogisticRegression(random_state=0, solver='lbfgs')
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=0, solver='lbfgs', tol=0.0001,
verbose=0, warm_start=False)
- 预测:
clf.predict()
## 在训练集和测试集上分布利用训练好的模型进行预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
- 精确度:
metrics.accuracy_score()
##训练集和测试集上的预测精度
from sklearn import metrics
print(metrics.accuracy_score(y_train,train_predict))
print(metrics.accuracy_score(y_test,test_predict))
四、总结
- 各种画图函数
- 逻辑回归模型具备可解释性,实现起来相对简单,是一个非常强大的分类器。























 659
659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









