







 本文介绍了如何在GD32F470系列芯片的开发中自定义协议,包括帧头、命令位、数据长度和校验位的定义,以及如何处理不同类型的校验方法。还探讨了数据解析和环形队列在实际应用中的角色,确保数据传输的正确性和完整性。
本文介绍了如何在GD32F470系列芯片的开发中自定义协议,包括帧头、命令位、数据长度和校验位的定义,以及如何处理不同类型的校验方法。还探讨了数据解析和环形队列在实际应用中的角色,确保数据传输的正确性和完整性。
温馨提醒:
由于我最害怕的就是接触各种新协议,尤其是对各种协议和解析协议数据简直就是职业生涯的噩梦,但工作中不免和不同的协议打交道。本着要啃就啃最难的,大不了放弃的心态。所以我学习了如何自定义制定自己的协议,如果你学会自己自定义协议后,那以后无论什么新协议对你来说都不再困难,也不再恐惧。但本文纯属个人学习经验分享,如介意,请千万不要食用。
芯片选型
Ciga Device — GD32F470系列
协议定义
什么是协议?不要把协议想的那么困难,协议有简单的,也有复杂的。最易懂的解释就是,我们约定好数据是什么格式,大家都按照这个规则来收发数据,这个规则就是协议。
举个例子,最简单的协议数据我们甚至可以用一个字符串来表示,类似于“led:1”,咱们约定好,发送端发送对应的LED数字,用冒号隔开,冒号后面是数字几,就点亮第几盏灯;那接收端收到数据后也用这个格式来解析出数据,再点亮数字对应的第几盏灯。
但在集成电路开发中,我们的寄存器资源是非常珍贵的,它不像手机内存动不动就几个G,有的芯片的内存可能只有几KB。再加上在电路与计算机底层中,0和1能让它们计算得更快。所以我们通常用位来存储数据,我们也用位和字节来制定协议。千万不要小看一个字节,一个字节有8个BIT,可以表示256种数据。试想一下,如果我们按照字符串“led:1”来传输数据,这需要5个字节,但如果我们约定用BIT来传输,1个BIT就够了,甚至不到1字节,是不是传输效率大大滴增加?计算效率大大滴提升?
大多数硬件协议定义通常都是有套路的,下面我们来详细康康。
硬件协议通用套路
帧头+命令+数据长度位+数据位+校验位+帧尾。(通常用字节进行传输)
| 帧头 | 命令位 | 数据长度 | 数据位 | 校验位 | 帧尾 | |
|---|---|---|---|---|---|---|
| 字节数 | 1 | 1 | 1 | n | 1 | 1 |
| 默认值 | 0x7a | 待定 | 待定 | 待定 | 待定 | 0x7b |
- 帧头:可以是任意数据,代表着从这里我要开始传输数据啦;
- 命令位:表示命令的类型;(比如1是调节PWM的;0是调节PID)
- 数据长度:通常用来说明传输的数据位有多少字节,经常用于校验数据传输中是否有数据丢失或其他异常情况;
- 校验位:也是用来确定我们的数据传输是否正确而不是其他方伪造或存在丢失情况;
- 帧尾:可以是任意数据,代表着我的数据传完啦、结束啦;
此时我们有个需求:上位机要传输PID的调试数据,数据位中有4个数据,通道ID(1个字节),P、I、D都是浮点类型数据(每个4字节),我们可以像下面这样定义:
| 帧头 | 命令位 | 数据长度 | 数据位 | 校验位 | 帧尾 | ||||
| idx | P | I | D | ||||||
| 字节数 | 1 | 1 | 1 | 1 | 4 | 4 | 4 | 1 | 1 |
| 默认值 | 0x7a | 0x01 | 待定 | 待定 | 0x7b | ||||
- idx:1个字节,int类型, 表示配置哪一组PID
- P: 4个字节,float类型。P值
- I: 4个字节,float类型。I值
- D: 4个字节,float类型。D值
协议生成
协议生成其实就是按照我们上面制定的那些规则拼装出规则数据再发出去。是的,你没看错,就是把数据按规则拼装出来,再发出去,就这么简单。
这里不得不插入一下校验位是咋肥事,否则没法发送校验码。(当然我们也可以不发送校验码,或者把校验码位固定发送成0x00也不是不行哈!只要解析的时候也按照这个套路来那就么得问题)
校验位
数据在传输过程中,可能会存在数据出错的情况。为了保证数据传输的正确性,因此会采取一些方法来判断数据是否正确,或者在数据出错的时候及时发现进行改正。常用的几种数据校验方式有奇偶校验、CRC校验、LRC校验、格雷码校验、和校验、异或校验等。
我们只说说异或校验、和校验、奇偶校验,其他的我也不会哈,请自行问AI吧!
- 奇校验(ODD):校验位被设置为确保数据位中1的总数为奇数。例如,数据位中的“1”总数为奇数,校验位被设置为低电平(拉低为0),否则设置为高电平。故而,如果接收方统计发现“1”总数为偶数,且校验是低电平,则校验失败,否则成功。
- 偶校验(Even): 校验位被设置为确保数据位中1的总数为偶数。例如,数据位中的“1”总数为偶数,校验位被设置为低电平(拉低为0),否则设置为高电平。故而,如果接收方统计发现“1”总数为奇数,且校验是低电平,则校验失败,否则成功。
- 异或校验:帧头、命令位、数据长度、所有的数据位全部异或后=校验位的值;(常见的XOR8校验算法就是全部异或后,取低8位的值)
- 和校验:帧头+命令位+数据长度+所有的数据位=校验位的值;(常见的ADD8校验算法就是全部进行与运算后,取低8位的值。像CRC16就是保留后2个字节)
协议构建与发送
// 发送数据结构体
typedef struct {
float channels[8];
uint8_t cmd; // 区分这是什么类型的数据
uint8_t len;
} bt_tx_data_t;
/*
使用Hex格式通讯协议
包格式: 帧头 命令码 数据长度 自定义数据 校验码 帧尾
0x7A 0xFF 0x0D 0x00 0x1F854541 0x1F854541 0x1F854541 0xE1 0x7B
校验码:XOR8, ADD8, CRC16
7A FF 0D 00 CF F7 71 41 6F 12 83 3A 8F C2 F5 3C C0 7B
-----------------------------------
7A 01 0D FF 00 00 70 41 6F 12 83 3A 8F C2 F5 3C F8 7B
*/
// 定义帧头字节
#define TX_FRAME_HEAD 0x7A
//定义帧尾字节
#define TX_FRAME_TAIL 0x7B
static void send_bt_protocol(bt_tx_data_t *data){
// 计算包内总长度
uint8_t frame_len = 5+(4*data->len);
//动态申请内存
uint8_t * frame_pack = malloc(frame_len);
//帧头
uint8_t index =0;
frame_pack[index++] = TX_FRAME_HEAD
//命令码
frame_pack[index++] =data->cmd;
//数据长度
frame_pack[index++] =data->len;
//填充自定义数据
uint8_t bytes[4];
//遍历数据,
for (int i=0;i<data->len;i++){
//将每个float转化成bytes
floatToBytes(data->channels[i],bytes);
frame_pack[index++]=bytes[0];
frame_pack[index++]=bytes[1];
frame_pack[index++]=bytes[2];
frame_pack[index++]=bytes[3];
}
//填充校验码
uint8_t checksum = xor8(frame_pack,index);
//填充帧尾
frame_pack[index++]=checksum;
//把数据发出去
USART1_send_data(frame_pack,frame_len);
//释放动态申请内存
free(frame_pack);
}校验与转换工具
/* Protocol.c */
#include "Protocol.h"
// ADD校验计算函数
uint8_t add8(uint8_t *data, uint32_t size) {
uint8_t checksum = 0;
for (uint32_t i = 0; i < size; i++) {
checksum += data[i];
}
return checksum & 0xFF;
}
// 异或校验计算函数
uint8_t xor8(uint8_t *data, uint32_t size) {
uint8_t checksum = 0;
for (uint32_t i = 0; i < size; i++) {
checksum ^= data[i];
}
return checksum;
}
// 将float转换为字节数组
void floatToBytes(float f, uint8_t bytes[]) {
FloatBytes fb;
fb.floatValue = f;
for (int i = 0; i < 4; i++) {
bytes[i] = fb.bytesValue[i];
}
}
// 将字节数组转换为float
float bytesToFloat(uint8_t bytes[]) {
FloatBytes fb;
for (int i = 0; i < 4; i++) {
fb.bytesValue[i] = bytes[i];
}
return fb.floatValue;
}/* Protocol.h */
#ifndef __PROTOCOL_H__
#define __PROTOCOL_H__
#include "gd32f4xx.h"
// 联合体
typedef union {
float floatValue;
uint8_t bytesValue[4];
} FloatBytes;
uint8_t add8(uint8_t *data, uint32_t size);
uint8_t xor8(uint8_t *data, uint32_t size);
// 将float转换为字节数组
void floatToBytes(float f, uint8_t bytes[]);
// 将字节数组转换为float
float bytesToFloat(uint8_t bytes[]);
#endif协议解析
理想数据正常解析
这是理想状态,假设每次接收的数据都是完整的从帧头到帧尾。
void handle_with_protocol(bt_rx_data_t * buffer){
if(buffer->len<16) return;
uint8_t cmd_code = buffer->data[1];
uint8_t chn_code = buffer->data[3];
float kp = bytesToFloat(&buffer->data[4]);
float ki = bytesToFloat(&buffer->data[4+4]);
float kd = bytesToFloat(&buffer->data[4+4+4]);
}真实情况数据解析处理
真实的数据的传输经常会有连包、粘包、断包情况。此时需要先将接收到的数据存入环形队列中,再进行解析。
环形队列原理
循环队列 (Circular Queue) 是一种数据结构(或称环形队列、圆形队列)。它类似于普通队列,但是在循环队列中,当队列尾部到达数组的末尾时,它会从数组的开头重新开始。这种数据结构通常用于需要固定大小的队列,例如计算机内存中的缓冲区。循环队列可以通过数组或链表实现,它具有高效的入队和出队操作。
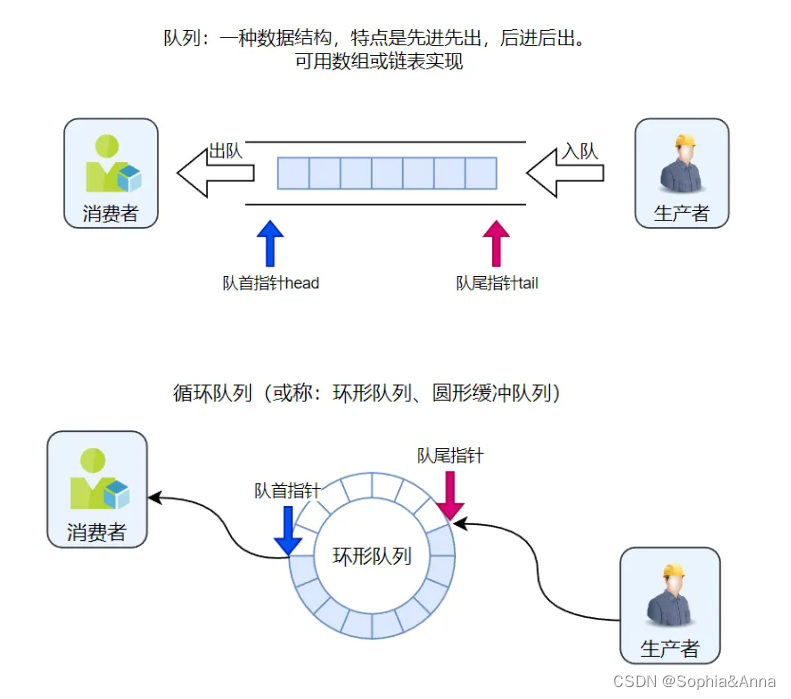
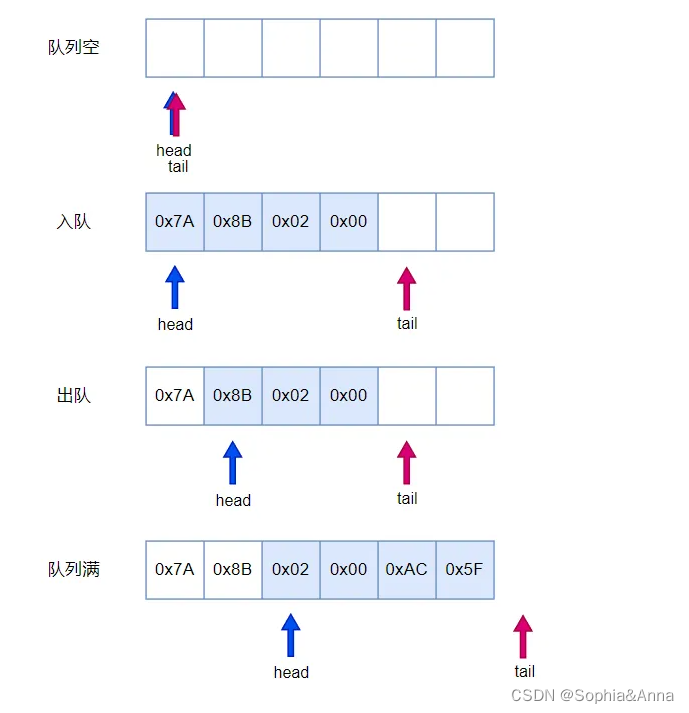
队列的几种状态
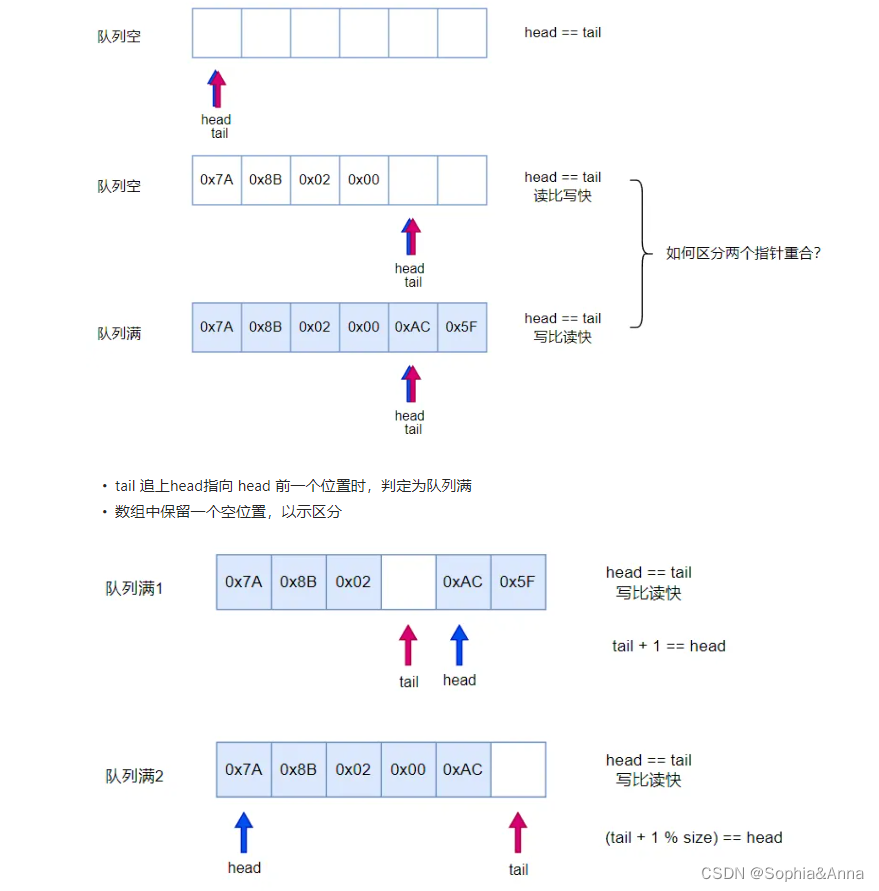
区分循环队列空和满
环形队列代码实现
头文件:circular_queue.h
#ifndef __CIRCULAR_QUEUE_H__
#define __CIRCULAR_QUEUE_H__
#include <stdint.h>
typedef struct {
uint32_t head; // 队头指针
uint32_t tail; // 队尾指针
uint32_t size; // 队列大小
uint8_t *buffer; // 队列缓冲区
} QueueType_t;
typedef enum {
QUEUE_OK = 0, // 成功
QUEUE_FULL, // 队列满
QUEUE_EMPTY, // 队列空
QUEUE_ERROR // 错误
} QueueStatus_t;
// 初始化
void queue_init(QueueType_t *queue, uint8_t *buffer, uint32_t buffer_size);
// 入队
QueueStatus_t queue_push(QueueType_t *queue, uint8_t dat);
// 出队
QueueStatus_t queue_pop(QueueType_t *queue, uint8_t *p_dat);
// 压入一组数据
uint32_t queue_push_array(QueueType_t *queue, uint8_t *p_arr, uint32_t len);
// 出队一组数据
uint32_t queue_pop_array(QueueType_t *queue, uint8_t *p_arr, uint32_t len);
// 获取队列数据个数
uint32_t queue_data_count(QueueType_t *queue);
#endifC实现:circular_queue.c
#include "circular_queue.h"
/**
* @brief 初始化环形队列
* \param queue 队列结构体变量指针
* \param buffer 队列缓存区地址
* \param buffer_size 队列最大大小
*/
void queue_init(QueueType_t *queue, uint8_t *buffer, uint32_t buffer_size)
{
queue->head = 0;
queue->tail = 0;
queue->size = buffer_size;
queue->buffer = buffer;
}
/**
* @brief 数据入队(向队列尾部插入数据)
*
* \param queue 队列结构体变量指针
* \param dat 一个字节数据
* \return QueueStatus_t 入队结果 QUEUE_OK 成功
*/
QueueStatus_t queue_push(QueueType_t *queue, uint8_t dat)
{
// 计算下一个元素的索引
uint32_t next_index = (queue->tail + 1) % queue->size;
// 队列满(保留一个空位)
if (next_index == queue->head) {
return QUEUE_FULL;
}
// 写入数据
queue->buffer[queue->tail] = dat;
// 更新队尾指针
queue->tail = next_index;
return QUEUE_OK;
}
/**
* @brief 数据出队(从队首弹出数据)
*
* \param queue 队列结构体变量指针
* \param pdat 出队数据指针
* \return QueueStatus_t
*/
QueueStatus_t queue_pop(QueueType_t *queue, uint8_t *p_dat){
// 如果head与tail相等,说明队列为空
if (queue->head == queue->tail) {
return QUEUE_EMPTY;
}
// 取head的数据
*p_dat = queue->buffer[queue->head];
// 更新队头指针
queue->head = (queue->head + 1) % queue->size;
return QUEUE_OK;
}
/**
* @brief 获取队列数据个数
*
* \param queue 队列指针
* \return uint32_t 队列有效数据个数
*/
uint32_t queue_data_count(QueueType_t *queue){
if (queue->tail >= queue->head){
// 队尾指针在队头指针后边
return queue->tail - queue->head;
}
// 队尾指针在队头指针前边(转了一圈到了队头指针之前)
return queue->size + queue->tail - queue->head;
}
/**
* @brief 压入一组数据
*
* \param queue 队列结构体变量指针
* \param p_arr 待入队数组指针
* \param len 待入队数组长度
* \return uint32_t 实际写入的数据个数
*/
uint32_t queue_push_array(QueueType_t *queue, uint8_t *p_arr, uint32_t len){
uint32_t i;
for(i = 0; i < len; i++){
if (queue_push(queue, p_arr[i]) == QUEUE_FULL){
break;
}
}
return i;
}
/**
* @brief 出队一组数据
*
* \param queue 队列指针
* \param p_arr 待出队数组指针
* \param len 待出队数组长度
* \return QueueStatus_t
*/
uint32_t queue_pop_array(QueueType_t *queue, uint8_t *p_arr, uint32_t len){
uint32_t i;
for(i = 0; i < len; i++){
if (queue_pop(queue, &p_arr[i]) == QUEUE_EMPTY){
break;
}
}
return i;
}HEX数据解析
代码逻辑步骤
- 创建一个环形队列,将接收到的HEX数据缓存到环形队列中 (这一步在串口接收到数据后存到环形队列中)
- 创建一个临时数组,用来存放符合协议约定的一组正常数据
- 如果环形队列中接收到数据,则开始解析
- 循环判断环形队列中的数据是否为0X7A,如不是则找下一个
- 如有数据为0X7A,则读出长度数据,判断长度是否符合协议规定
- 判断帧尾是否与期待的一致
- 判断临时数组中的校验码是否与期望的一致
- 把有效数据(去掉帧头、校验位、校验位)发送给调用者
- 重置临时数组索引与数据个数(以便于找下一组数据)
代码实现
//重置索引
void reset_recv_info(){
g_recv_index=0;
g_recv_data_cnt=0;
}
#define DATA_PACKAGE_LEN_MAX 30
int g_recv_index=0; // 环形队列中取数据的索引
int g_recv_data_cnt=0; //这个有效数据包的长度
uint8_t read_buf[DATA_PACKAGE_LEN_MAX]={0};
void Protoclo_task(){
// 只要队列里面有数据,就解析数据
while(queue_data_count(&g_recv_queue)>0){
if(queue_pop(&g_recv_queue,&read_buf[g_recv_index])!=QUEUE_OK){
continue;
}
g_recv_index++;
//判断0位是否是0x7a
if(read_buf[0]!=)x7a){
reset_recv_info();
continue;
}
//记录数据长度,计算数据包长度
if(g_recv_index==3){
g_recv_data_cnt=read_buf[2];
//如果数据包超过最大长度,说明是无效数据
if(g_recv_data_cnt+5>DATA_PACKAGE_LEN_MAX){
reset_recv_info();
continue;
}
}
//判断数据个数是否符合目标,如数据不够,继续等
int pack_len = g_recv_data_cnt+5;
if(g_recv_data_cnt<pack_len ){
continue;
}
//如果缓存区长度符合目标,检查校验码和帧尾
if(read_buf[g_recv_data_cnt-1]!=0x7b){
reset_recv_info();
continue;
}
uint8_t expect_xor8 = xor8(read_buf,pack_len-2);
if(read_buf[pack_len -2]!=expect_xor8 ){
reset_recv_info();
continue;
}
//发送给调用者
send_data_to_called(read_buf+1,pack_len -3);
//重新解析
reset_recv_info();
}
}

















 4767
4767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









