







 文章详细展示了如何利用Pyspark在MovieLens数据集中执行SQL查询,计算用户和电影的平均分,并解决特定的数据分析需求。
文章详细展示了如何利用Pyspark在MovieLens数据集中执行SQL查询,计算用户和电影的平均分,并解决特定的数据分析需求。
数据来源:
MovieLens数据集
MovieLens数据集包含多个用户对多部电影的评级数据,也包括电影元数据信息和用户属性信息。下载地址http://files.grouplens.org/datasets/movielens/
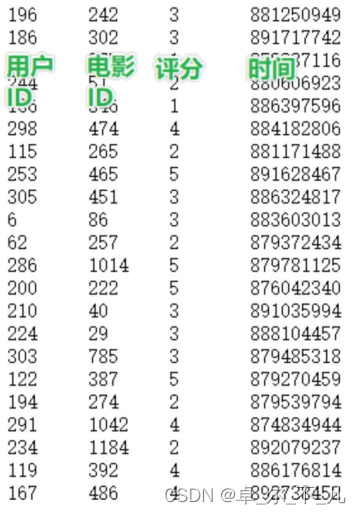
需求
1.查询用户平均分2.查询电影平均分
3.查询大于平均分的电影的数量
4.查询高分电影中(>3)打分次数最多的用户,并求出此人打的平均分5.查询每个用户的平均打分,最低打分,最高打分
6.查询被评分超过100次的电影,的平均分排名TOP10
代码
#coding:utf-8
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StringType, IntegerType
import pandas as pd
from pyspark.sql import functions as F
if __name__ == '__main__':
spark=SparkSession.builder.appName("movie_demo").master("local[*]").getOrCrea 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









