






 本文介绍如何利用浏览器的开发者工具简化网页抓取流程,重点讲解了使用XPath选择器提取特定元素的方法,以及如何通过Network工具分析动态加载内容的请求。
本文介绍如何利用浏览器的开发者工具简化网页抓取流程,重点讲解了使用XPath选择器提取特定元素的方法,以及如何通过Network工具分析动态加载内容的请求。
Using your browser’s Developer Tools for scraping
这是怎样使用你的浏览器开发者工具简化抓取过程的通用教程,现在所有的浏览器都有了Developer Tools 这里以火狐为例,但适用于其他的。
这个指南引用了 quotes.toscrape.com.来介绍使用浏览器开发者工具的基本工具
Caveats with inspecting the live browser DOM
由于开发者工具工作在实时浏览器DOM上,实际上在你检查时会发现页面资源不是最初的HTML,这是应用了一些浏览器清理并执行了javascript代码之后经过修改得到的。
Therefore, you should keep in mind the following things:
- 禁用javascript在检查DOM树来寻找scrapy使用的XPaths(在开发者工具设置中点击禁用)
- 不要使用完整的XPath路径,使用相对路径和更加清楚的属性(就像id class width等)或任何识别特征像 contains(@href,‘image’)
- 除非你真的直到你在干嘛,否则不要在你的xpath表达式中包含<tbody> 元素。
Inspecting a website
目前,开发者工具中最方便的功能就是检查器功能,可以让你检查任何网站的基础HTML代码,为了演示,我们查看 quotes.toscrape.com-site
在网站中我们总共有10个特别的名言标签来自不同作者,也是十个顶层标签。我们想要提取这个页面上的所有查询标签,不用任何关于作者的信息,标签等。
除了看所有的资源代码,我们可以在一个quote标签上邮件选择检查元素(inspect element), 这就会打开查询器。这这里你可以看见:
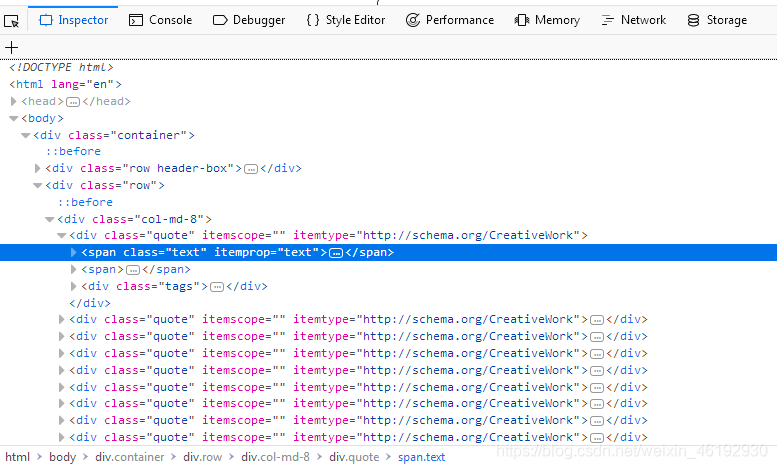
我们感兴趣的是这些。
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">(...)</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
如果你直接悬停在第一个div标签上就会出现高亮,同时网站页面中对应的部分也会显示高亮,所有你找到了对应的部分, 但还没有找到quote 的文本。
查询器的有点就是可以自动扩展和折叠网页的部分和标签,来提高可读性。你可以扩展和折叠标签通过点击在其前面的箭头或直接双击标签。如果我们展开span标签就会发现我们找的名言文本,查找器可以让我们复制选择元素的xpaths路径。
First open the Scrapy shell at http://quotes.toscrape.com/ in a terminal:
$ scrapy shell "http://quotes.toscrape.com/"
返回浏览器,右击span标签选择 copy > XPath 并粘贴到scrapy shell 中。
>>> response.xpath('/html/body/div/div[2]/div[1]/div[1]/span[1]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”']
使用text() 在最后可以使用基本选择器提取第一个名言。但是这个xpath不是很清楚,他是从html开始沿源代码所需的路径进行。所有我们看一下是否精炼一下xpath.
如果再次检查检查器,我们会发现在外面扩展的div标签的直接下方有九个相同的div标签,每个都有和第一个相同的属性。如果我们扩展其中的一个,我们会发现与我们第一个quote标签有相同的结果:两个span 一个div标签。我们可以扩展每个带有class=text 的span 标签,并查看每个名言。
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">
“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
</span>
<span>(...)</span>
<div class="tags">(...)</div>
</div>
有了这些知识我们就可以优化我们的xpaht ,我们使用简单的选择所有带有class='text’的span 标签,使用 has-class-extension:
>>> response.xpath('//span[has-class("text")]/text()').getall()
['“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”',
'“It is our choices, Harry, that show what we truly are, far more than our abilities.”',
'“There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”',
...]
一个简单清楚的xpath可以从页面中提取所有的名言。我们可以构建一个循环在第一个XPath上来增加最后div标签的数量,但是没有必要更加复杂,并且使用has-clas(‘text’)简单的构建一个xpath 就可以提取一排中所有的名言了
还有很多其他有用的功能,像在源代码中搜素或直接滚到选择的元素,演示一个例子:
我们想找到页面底部的Next。在选择器右上方的搜查栏中输入Next ,你会得到两个几个,第一个是li标签有class=next,第二个是一个a 标签。右击a标签选择 scroll into view,滚动到。如果你悬挑到这个标签,你会看到底部高亮。从这里我们可以简单的创建一个连接提取器来跟进分页。这这样简单的网站上,可能不用视觉上的查找,到那时 scroll into view 在复杂页面上很有帮助的。
注意搜查栏还可以用来搜素和检测css选择器。例如你要搜素span.text来找所有的名言文本。这会精确的搜素带有class='text’的span 标签,而不是全文搜素。
The Network-tool
再抓取时你可能会遇到动态加载的页面,页面的一些部分通过多请求动态加载。虽然很棘手,但是开发者工具中的Network-tool 工具可以解决这个任务。为了演示这个作用,以quotes.toscrape.com/scroll.为例。
这个页面与基本的quotes.toscrape.com一样,除了上面提到的Next按钮,页面自动加载新的名言当你滚动到底部时时,你可以到前面按并直接使用不同的xpath,但是我们可以使用scrapy shell 中其他更有用的命令来检查。
$ scrapy shell "quotes.toscrape.com/scroll"
(...)
>>> view(response)
游览器会被打开,有一个关键的不同是,没看见名言,只看见了Loading…的字样。

view(response) 命令让我们查看我们shell的响应或后来爬虫从服务器中收到的响应。这里我们看到基本的模块加载了,包括题目,登录按钮和页脚,但是名言没了,这告诉我们名言是通过其他请求来加载的,而不是quotes.toscrape/scroll
如果你检查Network选项,你可能会看见两个条目,第一件事是点击Persist logs启用持久记录日志。如果这个选项禁用,每次你导航到另一个页面日志就会自动清除。禁用这个是推荐的,因为我们可以控制何时清除日志。
如果你重新加载页面,你会看见日志中填充了六个新的请求。
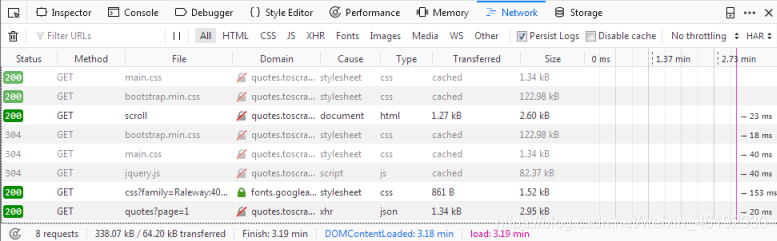
这里我们可以看见再重新加载页面时生成的每个请求并且可以检查每个请求和他的响应,因此找到名言来自那。
首先点击名为scroll的请求。在右边你可以检查这个请求。在Headers中,你会发现关于这个请求的详情,例如url,method IP-address等。我们可以直接点击Response.
你应该在Preview窗格中看到呈现的HTML-代码,这就是在shell中的vies(response) 看到的。另外,日志中的请求种类是html,其他请求有css or js的类型,我们感兴趣的是个叫quotes?page=1 json类型的i请求。
如果我们点击这个请求,我们会看见请求的url是http://quotes.toscrape.com/api/quotes?page=1 并且它的响应对象是JSON对象包含了我们的需要的名言。右击这个请求打开 Open in new tab 来更明白的看看
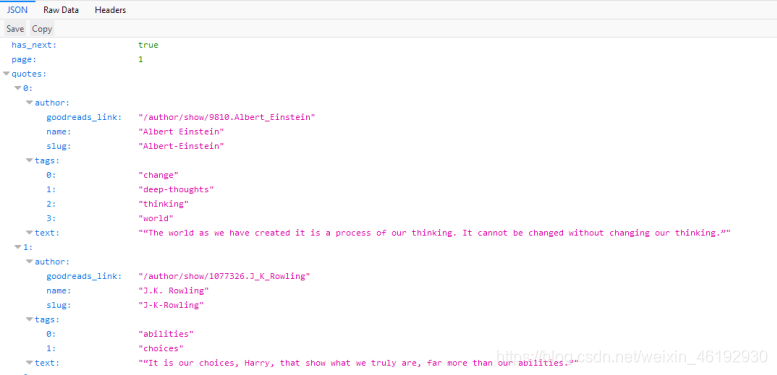
有了这个响应我们就可以简单的解析JSON对象并请求每个页面获得所有的名言。
import scrapy
import json
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
page = 1
start_urls = ['http://quotes.toscrape.com/api/quotes?page=1']
def parse(self, response):
data = json.loads(response.text)
for quote in data["quotes"]:
yield {"quote": quote["text"]}
if data["has_next"]:
self.page += 1
url = "http://quotes.toscrape.com/api/quotes?page={}".format(self.page)
yield scrapy.Request(url=url, callback=self.parse)
爬虫从第一个名言API的页面开始。对每个响应,我们解析response.text并分配给data,这是我们操作JSON对象像python的字典一样。我们历遍quotes并且打印quote[‘text’]。如果has_next元素是true(尝试加载quotes.toscrape.com/api/quotes?page=10在你的浏览器中或大于10的页面数字),我们增加页面属性并yield一个新的请求,插入增加的页面数字到url中。
对更复杂的网站,很难简单的仿制请求,这样可能需要增加headers or cookies来让它工作。在这些情况下,你可以使用cURL的格式来导出请求,通过在network tool中右击每个请求使用from_curl() 方法来生成一个等效的请求,
from scrapy import Request
request = Request.from_curl(
"curl 'http://quotes.toscrape.com/api/quotes?page=1' -H 'User-Agent: Mozil"
"la/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0' -H 'Acce"
"pt: */*' -H 'Accept-Language: ca,en-US;q=0.7,en;q=0.3' --compressed -H 'X"
"-Requested-With: XMLHttpRequest' -H 'Proxy-Authorization: Basic QFRLLTAzM"
"zEwZTAxLTk5MWUtNDFiNC1iZWRmLTJjNGI4M2ZiNDBmNDpAVEstMDMzMTBlMDEtOTkxZS00MW"
"I0LWJlZGYtMmM0YjgzZmI0MGY0' -H 'Connection: keep-alive' -H 'Referer: http"
"://quotes.toscrape.com/scroll' -H 'Cache-Control: max-age=0'")
或者如果你想知道重建请求需要的参数,你可以使用scrapy.utils.curl.curl_to_request_kwargs()函数获取等效参数的字典。
注意,将curl命令转换成scrapy请求,你可以使用curl2scrapy.
通过Network-tool的多次检查我们可以简单的复制页面滚动功能的动态请求。抓取动态页面可以非常吓人,页面可能会非常复制,但是说白了就是识别出正确的请求,然后复制到你的爬虫中。
https://docs.scrapy.org/en/latest/topics/developer-tools.html

















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









