










《Web Scraper网页爬虫教程》 是我以谷歌浏览器插件Web Scraper为爬虫工具,理论与实战结合的教程。
如果大家有爬虫需求,欢迎大家公众号联系我,我可以免费帮忙爬取数据。
关于我的更多学习笔记,欢迎您关注“武汉AI算法研习”公众号,公众号浏览此系列教程视觉效果更佳!
Web Scraper真的是一个非常好用而简单的工具,完全把我们从代码中解放出来,但是知道这个工具的人还不是很多,遂写了这个教程文档。我利用实验室之余的空闲时间,自己制作的Web Scraper爬虫教程,第一次做这种类型的教程,很多地方可能不完善,大家阅读过程中有任何疑问和建议都可以给我留言,谢谢!
「Web Scraper安装所需软件」
谷歌浏览器、Web Scraper插件
谷歌浏览器可以通过百度进行下载安装
由于谷歌应用市场访问不了,我将下载好的Web Scraper插件上传到云文件,公众号发送“爬虫”获取Web Scraper插件链接下载。
「Web Scraper安装步骤」

步骤一:打开谷歌浏览器
点击右上侧自定义及控制=》更多工具=》扩展程序
或者直接地址栏输入:chrome://extensions/
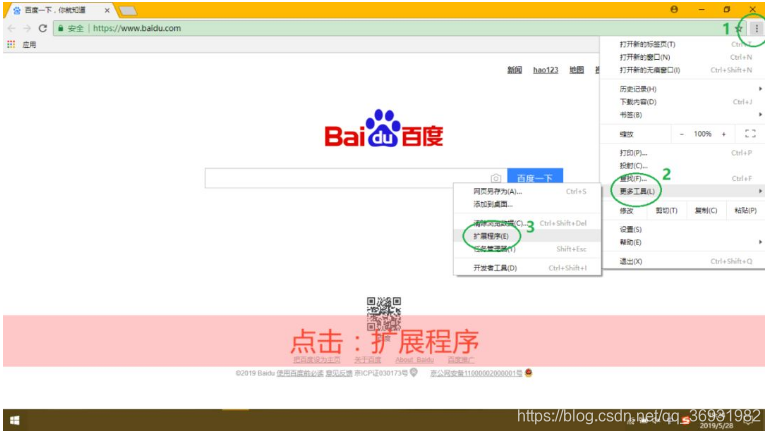
步骤二、拖动安装
拖动web scraper至页面空白处,之后点击“添加扩展程序”完成安装!
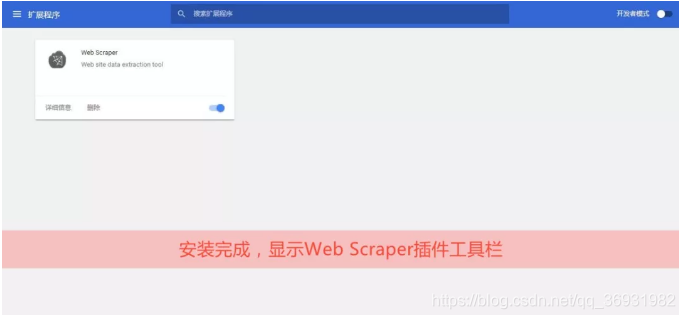
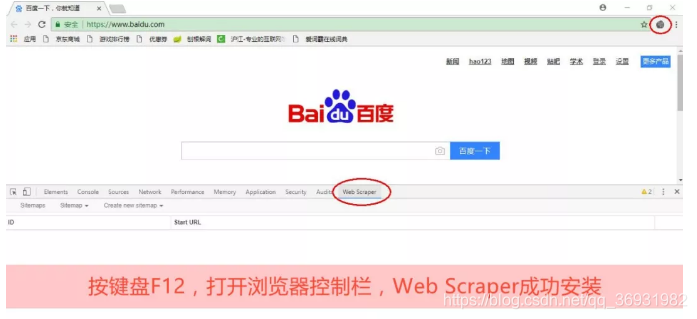
步骤三、F12打开插件
安装完成后,键盘F12调用控制台,显示已经安装好的Web Scraper
由于时间关系,我会逐渐更新整个Web Scraper教程
下节预告《【Web Scraper教程03】Web Scraper简单抓取微博评论》


















 1257
1257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









