







Python四大数据结构整理
列表
列表的特点
1.列表元素按顺序有序排放
2.索引映射唯一一个数据
3.列表可以存储重复数据
4.任意数据类型可以混存
5.根据需要动态分配和回收内存
列表本身的基础造作操作
1. 创建列表
- 使用方括号
lst1=['hello','world',98] #创建列表 lst = [] #创建空列表 - 使用内置函数list
lst2=list(['hello','world',98,'hello'])
2. 列表的查询
- 获取列表中指定元素的索引
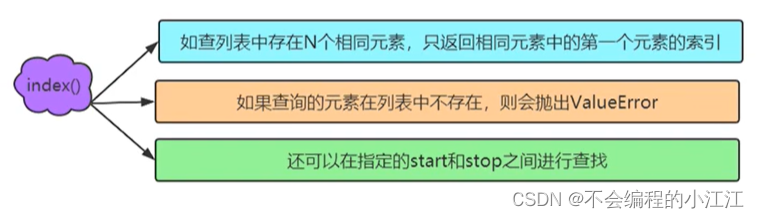
print(lst2.index('hello')) #返回第一个索引 print(lst2.index('hello',0,4)) #在 0-3内索引 - 获取类表中的单个元素
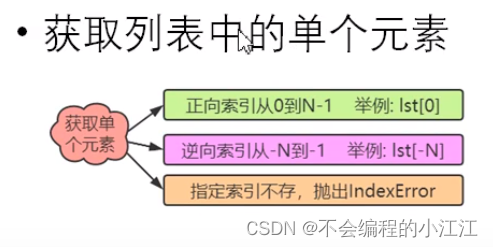
3. 判断指定元素在列表中是否存在
元素 in 列表名元素 not in 列表名
☆ 4. 列表元素的遍历
for 迭代变量 in 列表名 :lst=[10,20,'hello','world'] for item in lst: print(item)
☆ 5. 列表的切片
- 获取列表中多个元素-切片
语法:列表名[start : stop : step ]
| Q | A |
|---|---|
| 切片的结果 | 原类表片段的拷贝,新列表的 id 会变 |
| 切片的范围 | [start ,stop) |
| step 默认为 1 | 简写为 [start: stop: ] |
| step 为正数 | 第一个省略默认从头开始切,第二个省略默认切到尾 |
| step 为负数 | 第一个省略默认从最后一个元素开始,第二个省略默认切到头 |
lst=[10,20,30,40,50,60,70,80]
print('原列表:',lst)
# start=1 stop=6 step=1 步长默认为1
print("原列表id:",id(lst))
lst2=lst[1:6:2] # start=1 stop=6 step=2
print("新列表id:",id(lst2))
print(lst2)
lst2=lst[::2] # step = 2 ,首位均默认
print(lst2)
lst2=lst[4::-2] # start= 4,切到头,step = -2,逆序切
print(lst2)
列表的增删改查
1.列表元素的增加
| 方法/其他 | 描述 |
|---|---|
☆ append() | 在列表末尾添加一个元素 ,id不变 |
extend() | 在列表末尾至少添加一个元素 ,id不变 |
insert() | 在列表任意位置添加一个元素 ,id不变 |
切片 | 在列表任意位置至少添加一个元素, id 不变 |
lst=[10,20,30,40,50,60,70,80]
lst2=['hello','world']
print(lst)
# 常用
lst.append(90) # 列表末尾添加一个元素
print(lst)
lst.extend(lst2) # 列表末尾至少添加一个元素
print(lst)
lst.insert(1,90) # 列表任意位置添加一个元素
print(lst)
# 列表任意位置至少添加一个元素
lst3=[True,False,234]
lst[1:6]=lst3
print(lst)
# 切片 将3后续改为lst3
lst[3:]=lst3
print(lst)
2.列表元素的删除
| 方法/其他 | 描述 |
|---|---|
remove() | ☆一次删除一个元素 根据value删除 |
| 元素重复则只移第一个 | |
| 元素不存在则报异常 | |
pop() | ☆根据索引删除一个元素 |
| 元素不存在则报异常 | |
| 如果不指定参数,移除最后一个元素 | |
| 切片 | 一次至少删除一个元素,id变不变看切法 |
clear() | 清空列表 |
del | 删除列表 |
lst=[10,20,30,40,50,60,30]
lst.remove(30)
print(lst)
lst.pop(1)
print(lst)
lst.pop() #如果不指定参数,将删除最后一个元素
print(lst)
print('id=',id(lst))
#[10, 40, 50, 60]
# 切片删除
#这样切,id不变
lst[1:3]=[]
#这样切,id变
#lst = lst[1:3]=[]
print(lst)
print('id=',id(lst))
# 清空列表
lst.clear()
print(lst)
#删除列表
del lst
3.列表元素的修改
- 为指定索引的元素赋予一个新值
- 为指定的切片赋予一个新值
lst=[10,20,30,40] lst[2]=100 print(lst) lst[1:3]=[300,400,500,600] print(lst)
4.列表元素的排序操作
-
1.调用sort()方法 不产生新的列表,在新的列表上面排序
lst=[20,40,98,54] print('排序前的列表:',lst,id(lst)) lst.sort() # 调用列表对象的sort方法,升序排序 print('排序后的列表:',lst,id(lst)) lst.sort(reverse=True) # reverse=True 降序 print(lst) lst.sort(reverse=False) # reverse=False 升序 print(lst) -
2.调用内置函数sorted, 会产生新的列表
print('--------------------调用内置函数sorted, 会产生新的列表--------------------------') lst=[20,40,98,54] print('排序前的列表:',lst,id(lst)) new_list=sorted(lst) # 默认 reverse=False 升序 new_list=sorted(lst,reverse=True) # reverse=True 降序 print(' sorted 排序后的列表:',new_list,id(new_list))
4.通过列表生成式创建新列表
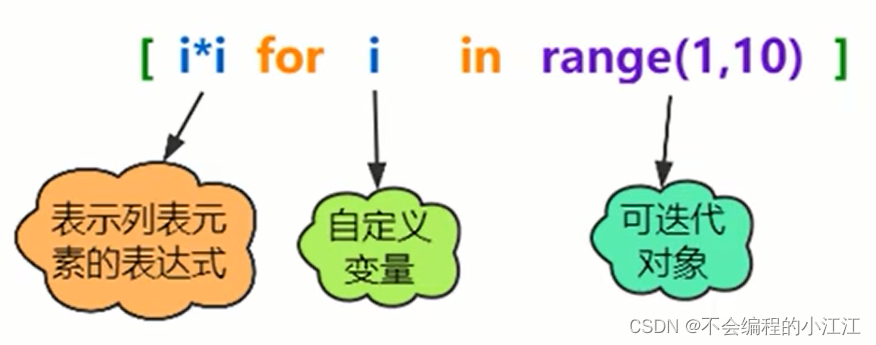
lst=[i*2 for i in range(1,6)] #只能生成有规则的列表
print(lst)
列表总结

字典
字典的创建
1.使用 { } 创建
2.内置函数dict()
3.字典生成式
#1.使用{}括号
score={'张三':100,'李四':98,'王五':75}
#2.使用内置函数dict()
stu=dict(name='jack',age=20)
#3.字典生成式
items=['Fruits','Books','Others']
prices=[96,78,85,100,90] #元素少的为基准
dic={item.upper():value for item,value in zip(items,prices) }
常用操作
- 获取value
- 字典名 [ key ]
- 字典名. get( key )
- 删key-value
del 字典名 [ key ] - 修改/新增
字典名 [ key ] = value - in / not in
获取字典视图
| 方法 | 功能 |
|---|---|
| keys() | 获取字典中的所有键 key |
| values() | 获取字典中的所有值 value |
| items() | 获取字典中的所有键值对 key, value |
score = {'张三':100,'李四':98,'王五':75}
keys = score.keys() #获取所有键
values = score.values() #获取所有值
items = score.items() #获取所有键值对 返回值为元组类型
lst = list(keys) #键转列表
lst = list(values) #值转列表
遍历字典
score={'张三':100,'李四':98,'王五':75}
for item in score:
print(item,score[item],score.get(item))
字典特点
- 字典的元素是无序的,根据键key来查找Value所在的位置
- 字典中元素的键不允许重复,值允许重复
- key必须是不可变对象
- 可根据需求动态伸缩
- 浪费较大的内存,是一种空间换时间的数据结构 中间有空余 但查找快
字典生成式
items = ['Fruits','Books','Others']
prices = [96,78,85,100,90] #元素少的为基准
dic = {item:price for item, price in zip(items, prices)}
元组与集合
元组的创建
t1 = ('Python','World',98) #常用
t2 = tuple(('python','world',98)) #强转
t3 = ('python',) #一个元素,逗号不可省略
元组的获取
print('---------------------元组遍历------------------')
t=('Python','World',98)
# 1. 使用索引
print(t[0])
# 2. 遍历
for item in t:
print(item)
为什么要将元组设计成不可变序列
- 为什么要将元组设计成不可变序列:
- 在多任务环境下,同时操作对象时不需要加锁
- 因此,在程序中尽量使用不可变序列
- 注意事项:元组中存储的是对象的引用
- 如果元组中对象本身不可变对象,则不能再引用其它对象
- 如果元组中的对象是可变对象, 则可变对象的引用不允许改变,但数据可以改变
典例:type+id
t=(10,[20,30],9)
print(t)
print(type(t))
print(t[0],type(t[0]),id(t[0]))
print(t[1],type(t[1]),id(t[1]))
print(t[2],type(t[2]),id(t[2]))
#t[1]=100 元组是不允许修改元素的
#由于[20,30]为列表,而列表是可变序列,所以可以向列表中添加元素,而列表内存地址不变
t[1].append(100) #向列表中添加元素
print(t,id(t[1]))
集合
- Python语言提供的内置数据结构
- 与列表、宇典一样都属于可变类型的序列
- 集合是没有value的宇典
- 和字典相同,无序且不能重复
集合的创建方式
s = {2,3,4,5,5,6,7,7} #直接 {} 创建
s1 = set(range(6)) #使用内置函数 set()
s2 = set([1,2,3,4,4,5]) #列表转集合
s3 = set((2,3,1,4,4,5)) #元组转集合 集合是无序的
s4 = set('python') #字符转集合
s5 = set({12,4,6,2,89,3}) #集合转集合
s6 = set() #空集合
集合的相关操作
| 功能 | 函数 / 方法 | 描述 |
|---|---|---|
| 判断 | in | 存在 |
| not in | 不存在 | |
| 新增 | add() | 一次只添加一个 |
| update() | 至少添加一个 | |
| 删除 | remove() | 一次删除一个,不存在报错 |
| discard() | 一次删除一个,不存在不报错 | |
| pop() | 不能添参数,一次任意删一个 | |
| clear() | 清空集合元素 |
print('----------------集合的相关操作--------------')
#判断 in 或者 not in
s={10,20,30,40,50}
print(10 in s)
#增加 add 或者 updata
s.add(100) #一次只添加一个
s1={3762,9773}
s.update(s1) #至少添加一个
print(s)
#删除
s.remove(100)
print(s)
s.pop()
s.pop()
print(s)
s.clear()
对比归纳总结
| 数据结构 | 是否可变 | 是否重复 | 是否有序 | 定义符号 |
|---|---|---|---|---|
| 列表(list) | 可变 | 可重复 | 有序 | [ ] |
| 字典(dict) | 可变 | key不重复,value可重复 | 无序 | {key:value} |
| 元组(tuple) | 不可变 | 可重复 | 有序 | ( ) |
| 集合(set) | 可变 | 不可重复 | 无序 | { } |

















 306
306











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











