







langchain+ChatGLM 大模型
相关文件(github上下载不来可以到这来取)【网盘文件链接】
链接:https://pan.baidu.com/s/14Dx9djCxpLJb2MgpoOkG1A?pwd=ABCD
提取码:ABCD
【注意事项】
-
解压文件/git克隆下的 langchain+ChatGLM文件要在/home文件夹下
-
新创建的model文件夹是在langchain+ChatGLM文件夹中创建的
-
在model文件夹下创建chatglm-6b-int4文件夹,把网盘的chatglm-6b-int4中的文件全部复制过去
-
在model文件夹下创建GanymedeNil——在GanymedeNil文件夹下创建text2vec-large-chinese文件夹,(把网盘中text2vec-large-chinese文件夹下的文件全部复制过去)(解决分享链接问题)
-
知识库问答模块中,上传知识库文档支持:text、word、PDF
-
如果我们访问的端口是7860等,记得通过跳板机把防火墙中这个端口打开:
(以3306端口为例)
0.0查看防火墙
查看防火墙状态:service iptables status
开启防火墙:service iptables start
关闭防火墙:service iptables stop如果出现报错:Unit iptables.service could not be found.

这是因为CentOS7默认的防火墙不是iptables,而是firewalle。出现此情况可能是iptables防火墙未安装。
如果你只是想开放某个端口的防火墙,那么你有两种选择:1.firewalld 防火墙;2.iptables防火墙。如果你选择第一种,则不用安装iptables。
下面介绍firewalld 防火墙开放端口的方法和iptables的安装方法。
0.1 firewalld 防火墙开放端口
查看firewalld状态:systemctl status firewalld
开启firewalld:systemctl start firewalld
如果启动报错:Failed to start firewalld.service: Unit is masked.
是因为被锁定了,取消firewalld的锁定:systemctl unmask firewalld,再启动即可。
开放某个端口:firewall-cmd --zone=public --add-port=3306/tcp --permanent
重新载入:firewall-cmd --reload

这样,3306端口都开放啦。
一、参考文档:
-
https://zhuanlan.zhihu.com/p/632671704
-
https://github.com/imClumsyPanda/langchain-ChatGLM/blob/master/docs/INSTALL.md
-
https://www.bilibili.com/video/BV1Ah4y1d79a/?spm_id_from=333.880.my_history.page.click&vd_source=a6e349c512d9a63f172643ef60b2eafd
-
https://www.bilibili.com/video/BV13M4y1e7cN/?spm_id_from=333.999.0.0&vd_source=a6e349c512d9a63f172643ef60b2eafd
二、具体实现步骤:
2.1 环境检查
# 首先,确信你的机器安装了 Python 3.8 及以上版本
$ python --version
Python 3.8.13
# 如果低于这个版本,可使用conda安装环境
$ conda create -p /your_path/env_name python=3.8
# 激活环境
$ source activate /your_path/env_name
$ pip3 install --upgrade pip
# 关闭环境
$ source deactivate /your_path/env_name
# 删除环境
$ conda env remove -p /your_path/env_name
【注释: conda管理环境与保存环境配置】
2.1.1 环境管理原因与环境命名细则
在开始使用conda管理python环境之前,需要强调几点:
1、因为工作需要以及学习需要,我们通常需要不同版本的python或者不同版本的python的package来保证我们的代码正常运行。例如,我们需要复现别人的NLP实验,这里以ACL2019的两篇最佳论文为例,某一篇论文运行环境是Python2.7+Tensorflow1.8.0(ACL2019的Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts,源码);另一篇论文运行环境是Python2.8+Pytorch1.0.0(ACL2019的TRADE Multi-Domain and Unseen-Domain Dialogue State Tracking,源码)。更一般地,由于python2和python3存在很大的差别,所以,我们的服务器可能至少需要两个不同版本的python以便我们能够同时使用python2和python3。
2、在正式管理环境的时候,需要规范一下自己的环境名称,最好提前建立一套命名规则,其次,要学会保存好自己的环境配置,并且定期更新环境配置。所以,这里谈谈命名规则:
- 一是要简短,因为我们进入环境前需要使用conda activate env_name #env_name就是要激活的环境名称,所以简短的名称既容易记忆也容易打出来;
- 二是不要使用下划线,这会影响你的输入速度;
- 三是要体现python版本;
- 四是可以考虑工程特性,例如是偏向于NLP还是偏向于CV;
- 五是可以考虑体现重要包,例如tensorflow、pytorch等。
例如:py27、py36、nlppy27、cvpy27、nlppy36、cvpy36、tfpy27、torchpy36等等。
2.1.1 查看已有python环境
在创建环境之前,一个好的习惯就是先查看已有的python环境,确保已有python环境不适合自己的任务,再去创建新的环境。
conda 提供了两种列举已有环境的命令,如下:
命令1:(我用命令1多一些)
conda env list
命令2:
conda info --envs
2.1.2确定命名并且创建新的环境
2.1.2.1、创建一个python2.7的环境
不指定工程特性、考虑体现重要包,因此命名为py27,因为创建的单词为create,所以相对应的创建命名为conda create,我们可以通过以下命令获取帮助:
conda create --help
常用的参数有--clone、-n,当然,帮助里面还告诉了我们很多其他参数,可以以后慢慢了解。不妨直接拉到帮助的最后,因为在最后面给出了一个使用例子,如下:
Examples:
conda create -n myenv sqlite
因此,参考这个Examples,完整的py38创建命令如下:
conda create -n py27 python=2.7 #python=2.7指定python版本
终端提示如下:

需要输入y并按回车确认创建环境:
环境创建完成后会有如下提示:

这个时候,我们可以用conda env list来查看最新的环境列表,结果如下:

其中,带*的表示当前所处的环境,当然,在用户名左侧也会用一个加括号的环境名标记出来
2.1.2.2、创建一个python3.6和一个最新版本python的环境
类似地,命令为:
conda create -n py36 python=3.6 #python=3.6指定版本
目前最新版本的python为python3.7.4【2019年08月03日参考python官网】,相应地,创建命令为:
conda create -n py37 python=3.7 #python=3.7指定版本
最终,我们用conda env list来查看最新的环境列表,如下:
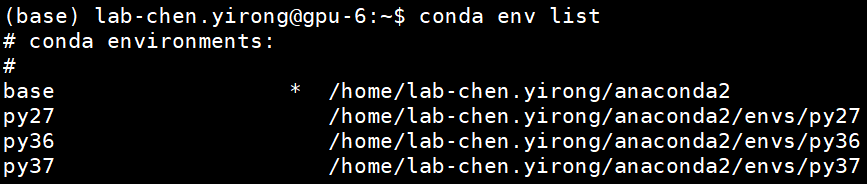
至此,我们已经安装完了相应的环境
2.1.2.3、进入创建好的环境:
- 首先需要进入指定的python环境,例如:
conda activate py27
- 然后,确保你在这个环境下已经安装了pip:
conda install pip
三、项目依赖
#进入python3.8环境下运行项目
conda activate py38
# 拉取仓库
$ git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
(直接通过我给你的百度网盘地址下载吧:)
# 进入目录
$ cd langchain-ChatGLM
# 项目中 pdf 加载由先前的 detectron2 替换为使用 paddleocr,如果之前有安装过 detectron2 需要先完成卸载避免引发 tools 冲突
$ pip uninstall detectron2
# 检查paddleocr依赖,linux环境下paddleocr依赖libX11,libXext
$ yum install libX11
$ yum install libXext
# 安装依赖
$ pip install -r requirements.txt
# 验证paddleocr是否成功,首次运行会下载约18M模型到~/.paddleocr
$ python loader/image_loader.py
PS在这过程中还要加入文件的修改:
四、下载依赖后要修改的文件
3.1、解压后——主文件夹(langchain+ChatGLM)——下的webui.py文件
.launch(server_name='172.18.22.236', (这个写自己本机的ip地址)
server_port=80, (要访问的端口号,记得打开防火墙相应的端口)
show_api=False,
share=True, (修改为True)
inbrowser=False))
# 此处请写绝对路径
embedding_model_dict = {
"ernie-tiny": "nghuyong/ernie-3.0-nano-zh",
"ernie-base": "nghuyong/ernie-3.0-base-zh",
"text2vec-base": "shibing624/text2vec-base-chinese",
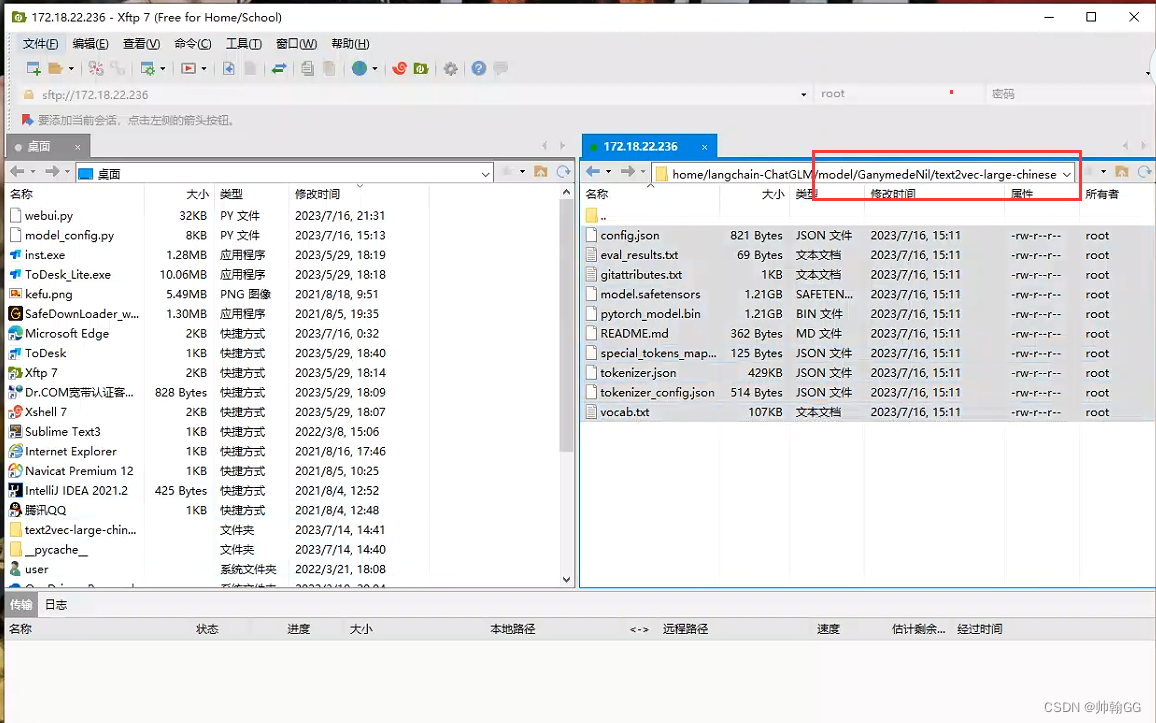
"text2vec": "model/GanymedeNil/text2vec-large-chinese", (这块要修改为model/GanymedeNil/text2vec-large-chinese,为text2vec文件夹所存放的位置)
"m3e-small": "moka-ai/m3e-small",
"m3e-base": "moka-ai/m3e-base",
}
3.2 configs文件夹下——model_config.py
# LLM 名称
LLM_MODEL = "chatglm-6b-int4" (名称修改为chatglm-6b-int4)
NO_REMOTE_MODEL = True (修改为True)
"chatglm-6b-int4": {
"name": "chatglm-6b-int4",
"pretrained_model_name": "model/chatglm-6b-int4", (修改所在的位置为model/chatglm-6b-int4)
"local_model_path": None,
"provides": "ChatGLM"
},
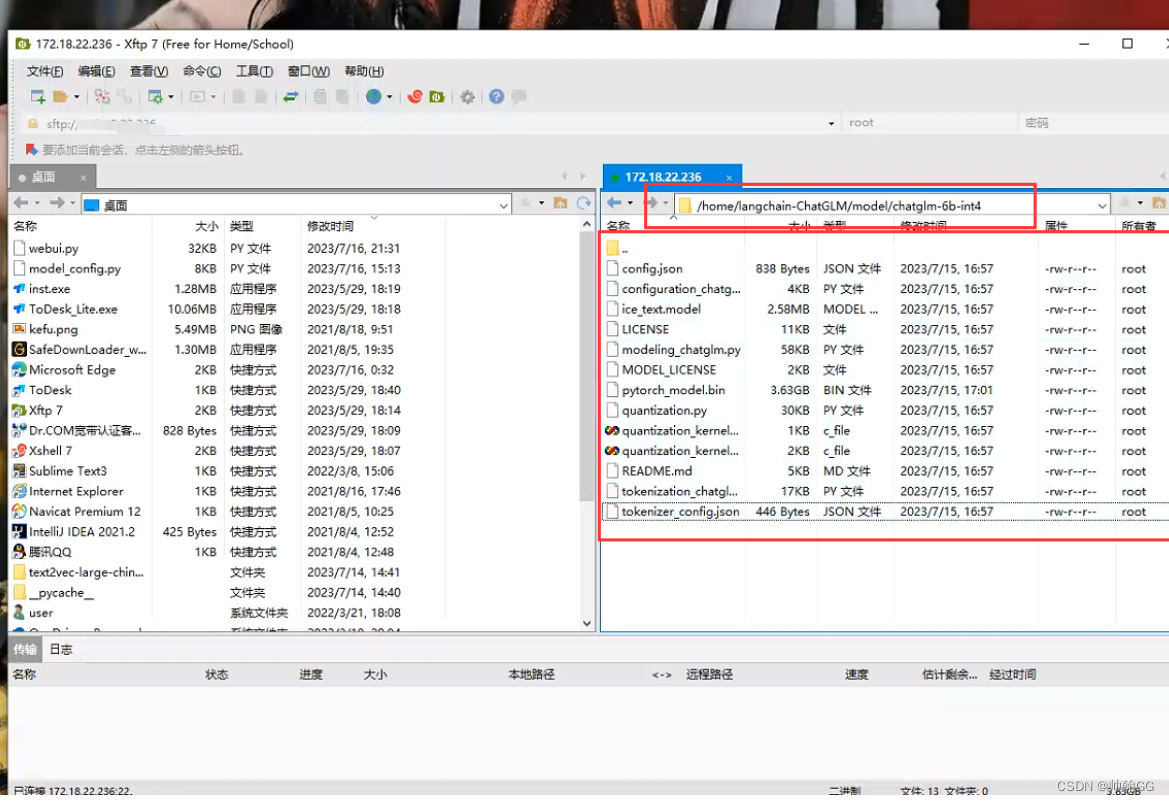
3.3 在langchain-ChatGLM文件夹下——创建model文件夹——chatglm-6b-int4文件夹——然后把下载好的chatGLM-6B-INT4版本的模型复制model文件夹下chatglm-6b-int4(这里我用的是上一个版本已经部署好的ChatGLM-6B的chatglm-6b-int4中的所以文件复制过去的)
3.4 在model文件夹下创建GanymedeNil——在GanymedeNil文件夹下创建text2vec-large-chinese文件夹(解决分享链接问题)
五、项目部署:
5.1 首先查看正在运行的项目所占用的端口号:
netstat -ntlp //查看当前所有tcp端口·
netstat -ntulp |grep 80 //查看所有80端口使用情况·
这里,我相用默认的80端口访问,查看80端口所占用情况
这时我发现我的80端口被 进程所占用
5.2结束原来正在执行的进程
kill 46712
5.3 后台运行我们的webui.py文件
#先进入webui.py文件所在的路径
cd /home/langchain-ChatGLM
#进入python3.8的环境
conda activate py38
#后台运行webui.py文件
$ nohup python /data/python/server.py > python.log3 2>&1 &
六、可能遇到的问题+解决方案
6.1 关于text2vec这块,安装失败
因为项目作者使用了GanymedeNil/text2vec-large-chinese这个模型。我在部署的时候,模型是自动下载的。这里就有一些水友反馈说下载失败,遇到这个问题的朋友可以自己上huggingface下载上述模型,地址传送门:(我们的百度网盘上的text2vec-large-chinese文件夹中自行下载)
模型下载完之后,可以在放在项目文件夹下,于此同时,需要在model_config.py配置文件里,修改一下text2vec的地址,根据你自己模型放的文件夹修改一下。
比如,我放在model文件夹下了,文件夹路径是model/GanymedeNil/text2vec-large-chinese,那就改成这个路径就可以了。
运行的时候,可能会提示:No sentence-transformers model found with name model/GanymedeNil/text2vec-large-chinese. Creating a new one with MEAN pooling
可以忽略这个提示,功能是可以正常使用的。
6.2 pycocotools安装失败
解决方案找了一个,传送门:https://blog.csdn.net/shaojie_45/article/details/116119227
可以自行去尝试
6.3 paddle安装报错
视频里提到了,我原先安装的是python3.11的版本,后来使用conda新建虚拟环境,选择python版本为3.10就不报错了。
6.4 chatglm-6b-int4模型找不到
有水友反馈说遇到这个问题,后来发现是因为没有下载chatglm模型的问题导致的。chatglm-6b-int4模型下载,可以上官方下载,我也放了一个云盘链接,可以自行下载
(我们的百度网盘上的chatglm-6b-int4文件夹中自行下载)
到这里我们的部署就已经成功啦!!!!
七、原理

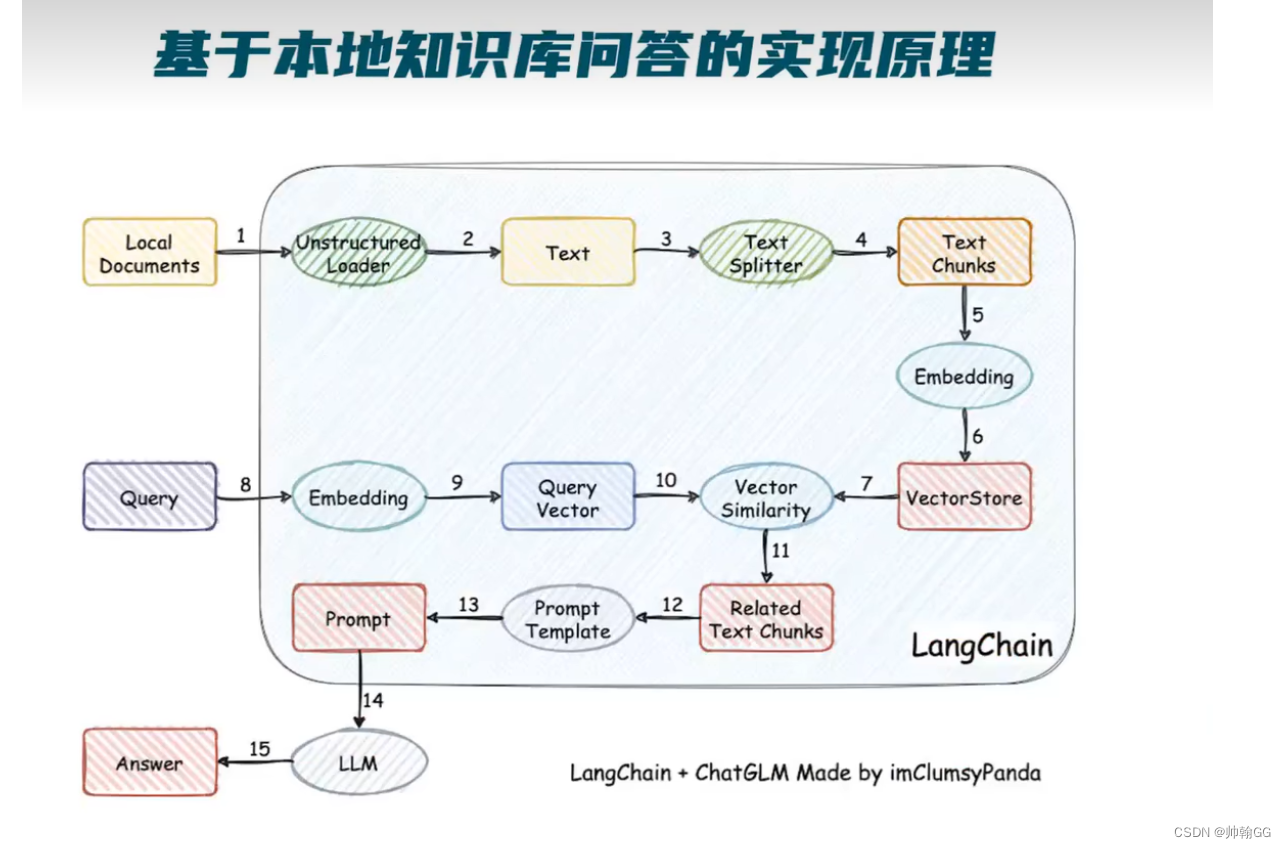
1.把本地的文件加载进来 >2.变成Text文本=>3.划分Text===>4.变为长度更短的Text Chunks =>5.通过Embedding的模型,进行向量化的过程=>6.构成VectorStore向量数据库
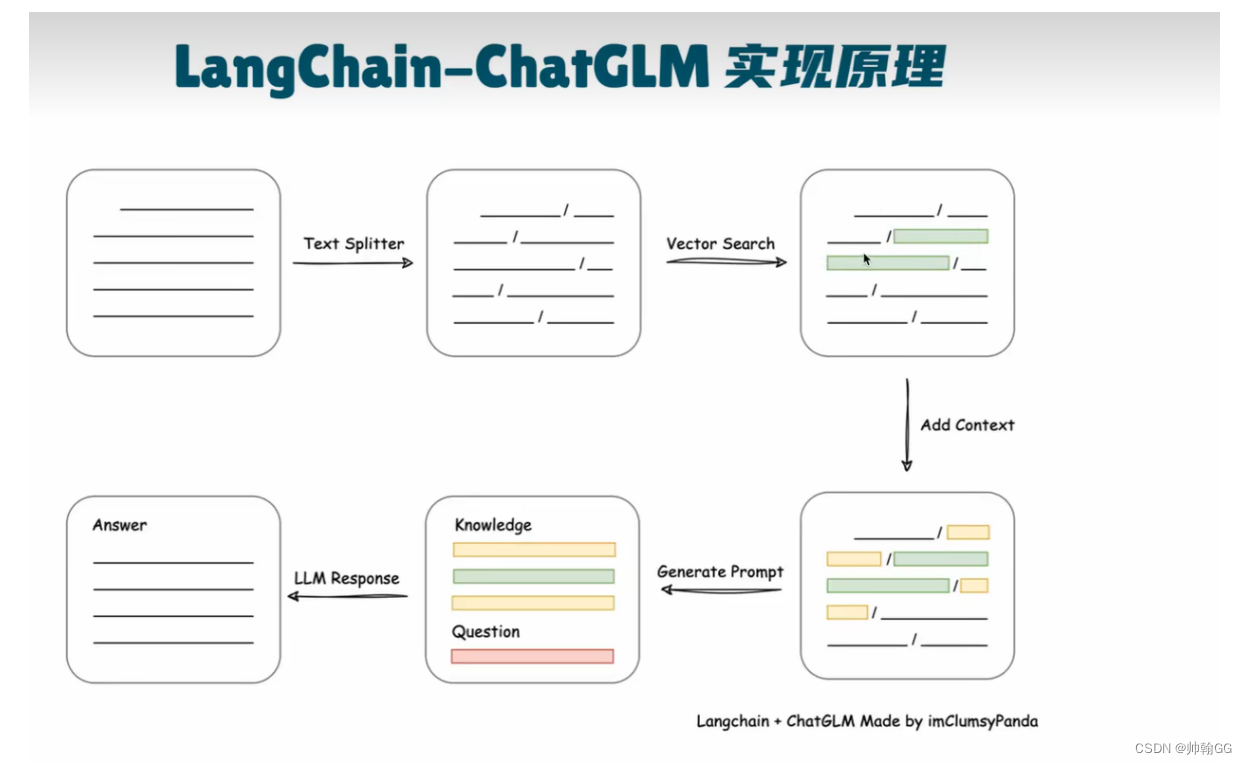
8.用户提问 => 9.通过Embedding的模型,进行向量化的过程=>10.提问的向量和已有的向量进行匹配===>11.匹配出一个/多个 相关度最高的文本Chunks =>12。获得到多个相关的文段=>13.形成先关语言模板===>14.进行输出
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









