









*结合Open-cv 以及深度学习的停车位识别
基于Open-cv 的停车场停车位识别个人笔记附所有代码(下)
基于Open-cv 的停车场停车位识别个人笔记附所有代码(上)
在学习唐宇迪老师的图像识别课程中,里边包含这样一个关于停车场车位识别的小项目,结合自己理解,优化了部分代码(此文中出现的为部分结果图),想更多了解的移步唐宇迪老师课程。
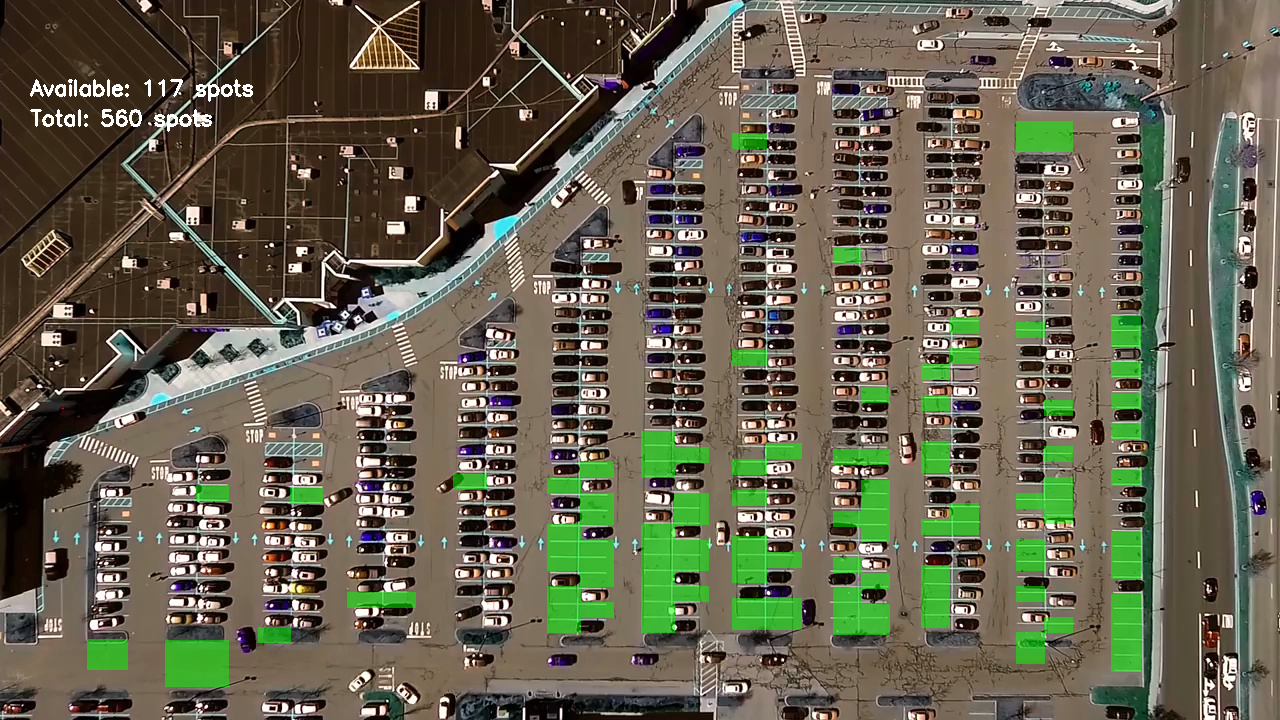
在上一节空停车位检测中,最后得到了如图1 的检测结果图,此部分主要解释如何通过CNN学习识别车位是否被占的情况。
1. 数据获取
众所周知,如果用CNN来训练一个模型的话,第一步便是对数据进行分析,针对此项目中的停车位识别,首先第一步便是对类似于图1 的图像进行车位裁剪,其中包含已占车位以及未占车位,裁剪之后对所得图像进行resize。
ef assign_spots_map(self,image, spot_dict, make_copy = True, color=[255, 0, 0], thickness=2):
if make_copy:
new_image = np.copy(image)
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
cv2.rectangle(new_image, (int(x1),int(y1)), (int(x2),int(y2)), color, thickness)
return new_image
def save_images_for_cnn(self,image, spot_dict, folder_name ='cnn_data'):
for spot in spot_dict.keys():
(x1, y1, x2, y2) = spot
(x1, y1, x2, y2) = (int(x1), int(y1), int(x2), int(y2))
#裁剪
spot_img = image[y1:y2, x1:x2]
spot_img = cv2.resize(spot_img, (0,0), fx=2.0, fy=2.0)
spot_id = spot_dict[spot]
filename = 'spot' + str(spot_id) +'.jpg'
print(spot_img.shape, filename, (x1,x2,y1,y2))
cv2.imwrite(os.path.join(folder_name, filename), spot_img)
在得到所有的裁剪图像之后,再对图像进行分类即将空车位以及已占车位区别开来,此处我用了最傻的办法,“人眼识别”,将其分别存放。
 图2. 已占车位裁剪图 图2. 已占车位裁剪图
|
 图3. 空车位裁剪图 图3. 空车位裁剪图
|
2. 模型搭建
在获得数据之后,接下来便是模型搭建,模型建立在Keras框架上,首先是进行数据增强,其次利用迁移学习引入VGG16模型,因为此项目数据量只有300左右,倘若自己训练模型,效果反而不佳,冻结VGG模型的前10层保证训练效果,之后配置其他超参数。
train_datagen = ImageDataGenerator(
rescale = 1./255,
horizontal_flip = True,
fill_mode = "nearest",
zoom_range = 0.1,
width_shift_range = 0.1,
height_shift_range=0.1,
rotation_range=5)
batch_size = 32
epochs = 15
num_classes = 2
model = applications.VGG16(weights='imagenet', include_top=False, input_shape = (img_width, img_height, 3))
for layer in model.layers[:10]:
layer.trainable = False
模型的结构、评估指标、运行结果如下:
x = model.output
x = Flatten()(x)
predictions = Dense(num_classes, activation="softmax")(x)
model_final = Model(input = model.input, output = predictions)
model_final.compile(loss = "categorical_crossentropy",
optimizer = optimizers.SGD(lr=0.0001, momentum=0.9),
metrics=["accuracy"])
loss: 0.0402 - accuracy: 0.9885 - val_loss: 0.4546 - val_accuracy: 0.9319
因此,通过构建CNN模型使算法在检测到停车位之后能够继续识别车位是否被占,从而可以应用到之后的停车场图像以及停车场实时视频中。
3. 算法优化
在复现此算法当中,个人觉得依然可以从以下方面继续优化算法:
- 停车场图像的处理,首先不同时间的光照、车身形状、颜色都会对停车位的检测造成影响,其次存在车身压线无法具体检测车位的情况。
- 在划分ROI区域时候,6个点可以更贴近其真实的停车场轮廓。
- CNN模型中,可以尝试其他的模型如Resnet系列以及Inception系列。同时能够通过视频中的不同帧,获取更多的训练数据。
- 在检测空车位的算法中,再加入微调算法,以及代价补偿机制等等。
















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











