






在预测任务中给定样例集D={(x1,y1),(x2,y2)……,(xm,ym)},其中yi是xi的真实标记,要评估学习器f的性能,就要把学习器预测结果f(x)与真实标记y进行比较。
回归任务最常用的性能度量是“均方误差”(mean squared error)
就是“均 方 差” (个人感觉类似于高中方差?)
更一般的,对于数据分布D和概率密度函数p(x),均方误差可描述为
其实也就是将离散转化为连续。
2.1 错误率与精度
错误率和精度是分类任务中最常用的两种性能度量,既适用于二分类任务,也适用于多分类任务,错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例,对样例集D,分类错误率定义为:
此处的连乘符号代表指示函数,若括号中的内容为真,则值取1,否则取值0;
精度则定义为
更一般的,对于数据分布D和概率密度p(x),错误率与精度可分别描述为
2.2查准率查全率与F1
以西瓜问题为例,农夫拉来了一车西瓜,我们用训练好的模型进行判别,但我们关注的是真的是预测的对错吗?比如真的烂瓜是否被预测正确为烂瓜?仔细想想不是的,因为我们最终的目的是——买到好瓜,我们关心的问题应该是,“我们通过模型挑出的西瓜(即模型认为是好瓜)的西瓜中,有多少比例是真好瓜”或者是“所有好瓜中有多少比例被我们通过模型挑了出来”;
类似的需求在信息检索、Web搜索中等应用中经藏出现,例如在信息检索领域,我们经常会关心“检索出的信息中有多少比例是用户感兴趣的” “用户感兴趣的信息有多少被检索出来了”
查准率,查全率,就是两种更适用于此类需求的性能度量。
对于二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为
真正例(True positive)假正例(False positive)
真反例(True negative) 假反例(False negative)
这四种情形,利用缩写TP FP TN FN 来分别表示上面的四种情况,TP+FP+TN+FN=样例总数
分类结果的混淆矩阵如图所示
| 预测结果 | 预测结果 | |
| 真实情况 | 正例 | 反例 |
| 正例 | TP (真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(假正例) |
查准率和查全率是一对矛盾的度量,一般来说,查准率高时查全率低,查全率高时查准率低,通常只有在一些简单任务钟,才可能使查全率和查准率都很高。
我们根据学习器的预测结果对样例进行排序,排在千米按的是学习器认为最可能是正例的样本,排在最后的是最不可能是正例的样本。按此顺序逐个把样本作为正例进行预测,则每次可以计算出当前的查准率和查全率得到曲线,简称P-R曲线
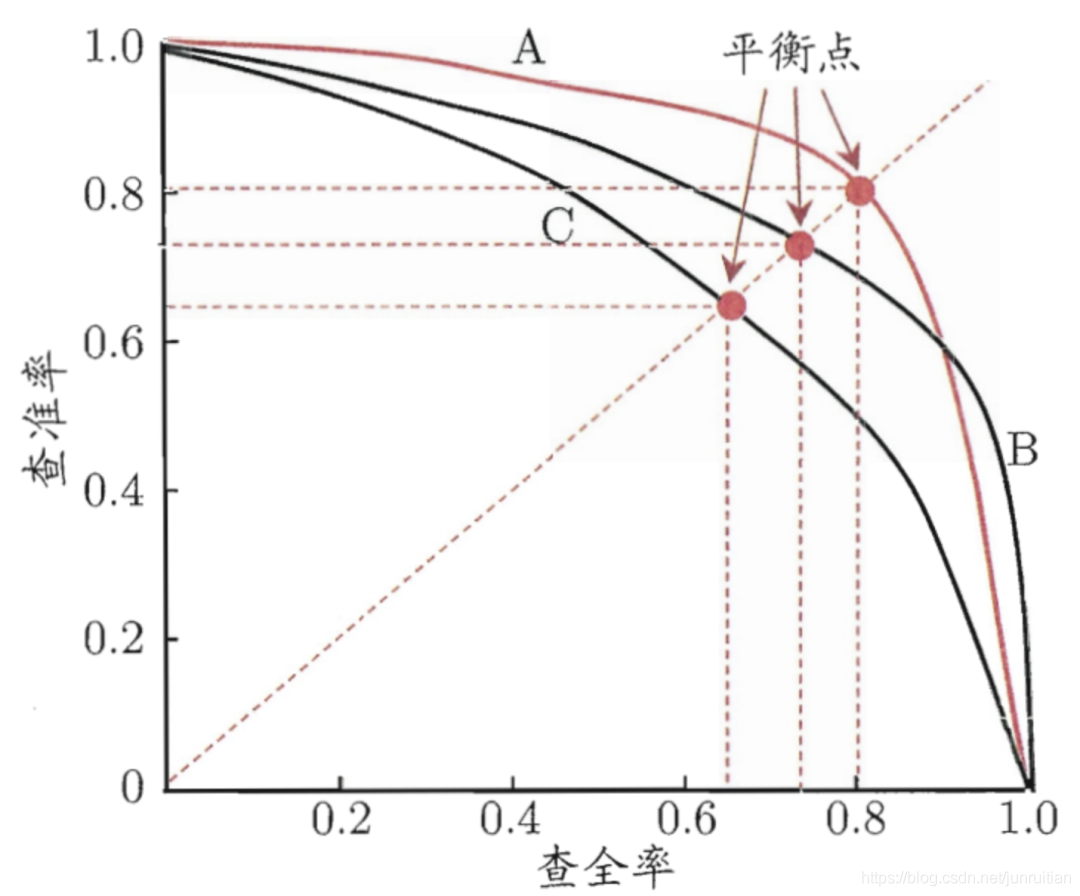
若一个学习器的PR曲线完全在另一个PR曲线的上方 ,则可断言前一个学习器的性能优于后者,如图中的A曲线和C曲线,对于同样的样本数据,学习器A的查准率和查全率总是高于学习器C,然而一般很难出现完全优于的情况,更多的会是像A,B一样,在不同的样本例子上,会体现出各自不同的忧虑,但人们仍然希望能够比较两个学习器性能的高低,因此人们选择了一个比较合理的判定依据是比较P-R曲线下面积的大小。














 7583
7583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









