






本次开始学习容器编排工具——K8s
一些辅助学习网站/工具
- Killercoda Interactive Environments 其中有很多准备好的环境,比如 Kubernetes | Killercoda 可以直接体验k8s。
- Play with Kubernetes 直接创建多个实例,可以体验集群K8s的部署。
注意以上两种环境都是临时且限时的,数据不能保存,刷新也会导致数据丢失,如果想保存久一点,建议先在上面的环境弄清楚如何部署K8s集群后,再到自己电脑上通过本地虚拟机部署K8s集群学习。 - VBox
学习目标
- K8s相关概念:集群、节点/主节点、Pod、标签、注解、标签选择器、副本控制器和副本集、服务、存储卷、有状态服务集、密钥对象、命名空间、节点亲和性、污点和容忍、Secret/ConfigMap
- K8s集群的部署
- K8s上部署应用:Helm、Deployment、Service、StatefulSet、Ingress暴露服务、自动扩缩容
- K8s存储:PV/PVC、卷/持久卷、Longhorn
- K8s Job
- 通过K8s部署:Mariadb、Redis、RabbitMQ
- Rancher管理K8s集群平台:通过Rancher访问K8s、部署Longhorn、部署CI/CD工具 Drone
作业
① 在本机虚拟机上(VBox + Ubuntu)部署一个三节点的K8s集群,注意合理分配资源。尝试不同的集群部署方式,总结优缺点和便利性。
参考书籍
- 《精通Kubernetes》 [美] Gigi Sayfan
- 《基于Kubernetes的云原生DEVOps》 [美] John Arundel
- 《Kubernetes设计模式》 Bilgin Ibryam
这是目录
一、概念
-
集群:主机存储和网络资源的集合,使用集群来运行组成系统的各种工作负载。
-
控制面板(集群成员称为主节点):组成组件包括API服务器、调度器、控制器管理器:
- kube-apiserver:前端服务器,负责处理API请求。
- etcd:k8s数据库,用于存储所有信息:节点、集群资源等。
- kube-scheduler:决定在何处运行新建的Pod。
- kube-controller-manager:运行资源控制器。
- cloud-controller-manager:负责与云提供商(在基于云的集群中)进行交互,管理负载均衡以及磁盘卷之类的资源。
-
节点:单个主机(物理机或虚拟机),职责是运行pod,每个节点运行多个组件:
- kubelet:负责容器的运行时,启动调度到某个节点的工作负载,并监视其状态。
- kube-proxy:网络代理,负责将请求路由到不同节点的Pod上,以及将请求从Pod路由到互联网上。
- 容器运行时:负责启动和停止容器,并处理容器通信。(通常由Docker负责)
-
-
Pod:Kubernetes的工作单元,一个Pod包含多个容器,这些容器具有相同的IP地址和端口空间,且都有本地共享存储,每个Pod有唯一的UID。
-
标签:
-
注解
-
标签选择器
-
副本控制器和副本集
-
服务
-
存储卷
-
有状态服务集
-
密钥对象
-
命名空间
-
节点亲和性
-
污点和容忍
二、部署k8s
原机环境:windows
虚拟环境:ubuntu20.4
虚拟运行环境管理工具Vagrant详细使用教程(下载安装vagrant可以看本篇)
1.部署vagrant
(1)初始化一个Ubuntu 18.04的镜像
可以这样直接下载,也可以去官网下盒子:Discover Vagrant Boxes
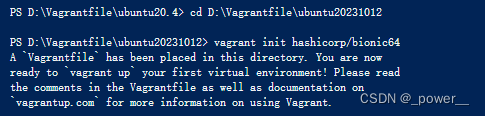
vagrant init hashicorp/bionic64
运行显示:
(2)配置vagrantfile文件
初始化后文件夹中多出vagrantfile文件,修改改文件进行虚拟机配置,应注意:需要cpu个数大于1,ip地址符合本地地址掩码(本地 ipconfig 查看)
vagrantfile文件:
Vagrant.configure("2") do |config|
(1..3).each do |i|
config.vm.define "k8s-node#{i}" do |node|
# 设置虚拟机的Box
config.vm.box = "hashicorp/bionic64"
# 设置虚拟机的主机名
node.vm.hostname="k8s-node#{i}"
# 设置虚拟机的IP
node.vm.network "private_network", ip: "192.168.33.#{99+i}", netmask: "255.255.255.0"
# 设置主机与虚拟机的共享目录
node.vm.synced_folder "D:/Vagrantfile/vagrant_workspace/share", "/home/vagrant/share"
# VirtaulBox相关配置
node.vm.provider "virtualbox" do |v|
# 设置虚拟机的名称
v.name = "k8s-node#{i}"
# 设置虚拟机的内存大小
v.memory = 2048
# 设置虚拟机的CPU个数
v.cpus = 4
end
end
end
end
(3)创建虚拟机
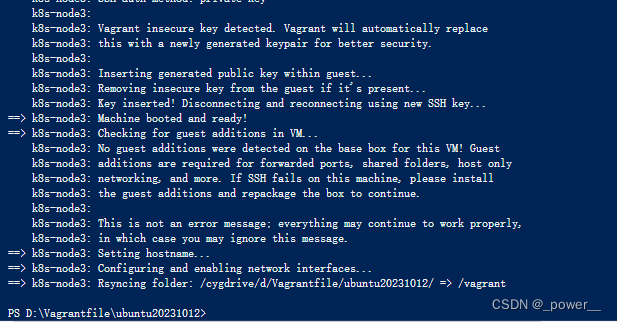
vagrant up
运行显示:
vagrant常见命令:
# 查询当前管理的盒子
vagrant box list
# 添加指定的vagrant的box镜像到vagrant中
vagrant box add <box的文件路径及文件名> --name <自定义box名称>
# 根据名字删除指定的box
vagrant box remove <NAME>
# ---虚拟机相关命令---
# 新建虚拟机
vagrant init <boxname> # 加上boxname 表示使用指定box名创建虚拟机
# 启动虚拟机命令
vagrant up
# 查看虚拟机状态
vagrant status
# 停止虚拟机
vagrant halt
# 暂停虚拟机
vagrant suspend
# 重启虚拟机
vagrant reload
# 恢复虚拟机 | 不管虚机是关闭还是暂停状态,甚至是 error 状态,都可以执行 vagrant up 来让虚机恢复运行
vagrant resume
# 删除虚拟机
vagrant destroy
# 使用vagrant自带的ssh工具去连接当前目录下的虚拟机
vagrant ssh
2.连接finalshell(可选)
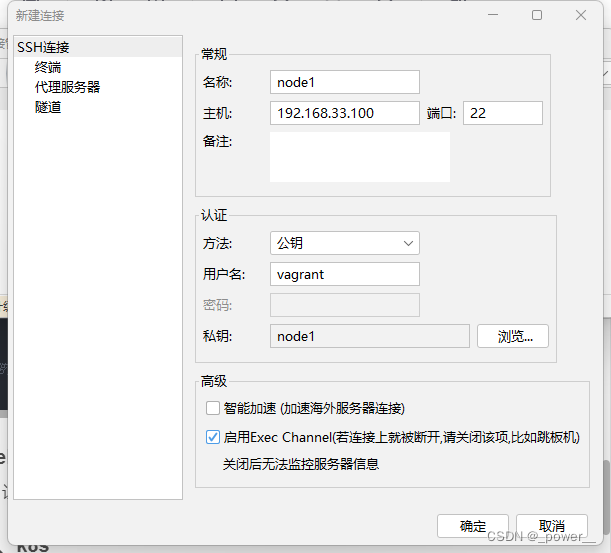
图形化工具连接,让命令使用更方便,选用其他shell也可以,此处选用finalshell
新建连接:vagrant默认不允许使用用户名与密码来进行登录(在/etc/ssh/sshd_config编辑后才可以),而是使用私钥登录,私钥在当前vagrantfile同路径下的.vagrant目录下:
D:\Vagrantfile\ubuntu20231012.vagrant\machines\k8s-node1\virtualbox\private_key
初始用户账号密码都是vagrant
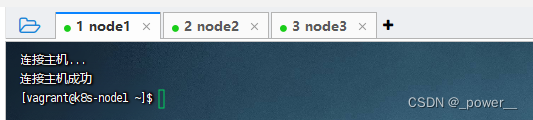
连接效果:
3.部署docker、k8s
(1)基本虚拟机配置(所有节点)
进入到三个虚拟机
# 切换到root用户
sudo -i
(可选)开启root的密码访问权限
# 修改配置 PermitRootLogin yes PasswordAuthentication yes
vi /etc/ssh/sshd_config
# 重启sshd服务
service sshd restart
关闭 swap 分区
sudo swapoff -a
sudo sed -i '/ swap / s/^/#/' /etc/fstab
修改内核参数
apt-get update -y
apt-get install -y bridge-utils
# 加载br_netfilter内核模块
modprobe br_netfilter
# 检查br_netfilter模块是否已成功加载
lsmod | grep br_netfilter
集群同步时间
sudo apt-get update
sudo apt-get install ntpdate
sudo ntpdate ntp.ubuntu.com
运行显示:
(可选)添加主机名与 IP 对应关系
vi /etc/hostname
(2)Docker部署
# (可选)卸载之前的Docker:
sudo apt-get remove docker docker-engine docker.io containerd runc
# 安装Docker必须的依赖:
sudo apt-get update
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common
# 设置Docker repo的APT位置:
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 安装Docker和Docker CLI:
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io
# 配置Docker加速:
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://ke9h1pt4.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload && sudo systemctl restart docker
# 设置Docker开机启动:
sudo systemctl enable docker
(3)k8s部署
安装kubeadm、kubelet 和 kubectl
添加阿里与APT源:
sudo tee /etc/apt/sources.list.d/kubernetes.list <<EOF
deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main
EOF
curl -s https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | sudo apt-key add -
安装kubelet kubeadm kubectl:
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
# 阻止自动更新(apt upgrade时忽略)。所以更新的时候先unhold,更新完再hold。
apt-mark hold kubelet kubeadm kubectl
# 开机启动:
sudo systemctl enable kubelet && sudo systemctl start kubelet
运行显示:
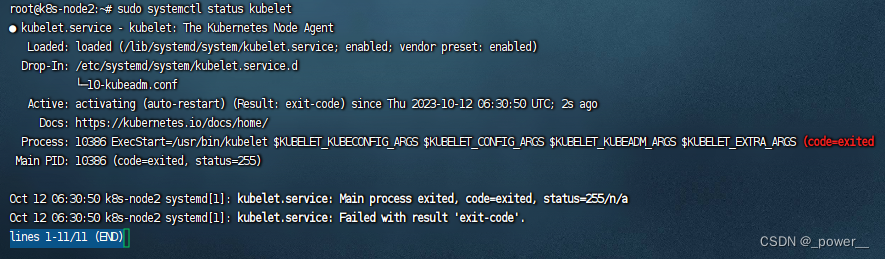
查看kubelet的状态:
sudo systemctl status kubelet
运行结果:
4.部署 k8s-master(v1.28.2)
(1)拉取必要的镜像
在运行 kubeadm init 之前可以先执行 kubeadm config images pull 来测试与 gcr.io 的连接,尝试是否可以拉取镜像,如果你的服务器在国内,是无法访问"k8s.gcr.io", “gcr.io”, “quay.io”
先测试:
kubeadm config images pull
如果不能正常拉取,在 init 时采用国内的镜像源,添加:--image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers'
(可选、但没必要)手动拉取:
# 首先查看kubeadm config 依赖的images有哪些(依据你当前kubeadm版本):
kubeadm config images list
# 然后从国内镜像拉取这些镜像,记得修改为你需要的版本(有些是可以直接拉取的,比如 k8s.gcr.io/coredns/coredns)
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.28.2
#将拉取下来的images重命名为kubeadm config images list所需的镜像名字
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/kube-apiserver:v1.28.2 registry.k8s.io/kube-apiserver:v1.28.2
(2)kubeadm 初始化
(如果你是 v1.27、v1.28 可以修改cri需求3.6->3.9,即报错4)
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml
vim /etc/containerd/config.toml
# [plugins."io.containerd.grpc.v1.cri"]块下的sandbox_image值改为国内镜像即可(pause版本因人而异)
# 该行3.6改为3.9,前面的地址改为你需要的地址
# 比如我的初始化采用的国内镜像地址为:--image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers'
# 就改为 sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9"
# 让配置生效
systemctl daemon-reload && systemctl restart containerd
①初始化
kubeadm init --kubernetes-version=1.28.3 --apiserver-advertise-address=192.168.33.100 --image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers' --service-cidr=10.1.0.0/16 --pod-network-cidr=192.168.0.0/16
如下显示即为成功:

如果没成功参考【报错1-5】
每次重新尝试时记得执行 kubeadm reset 和 rm -r $HOME/.kube 再重新 init
②配置证书
按照图片中提示,执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
③在node2、node3执行join命令使其加入集群
获取加入集群的命令(或复制上图所选):
kubeadm token create --print-join-command
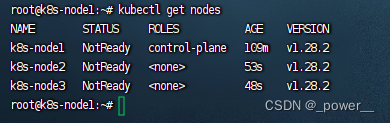
测试 kubectl:
kubectl get nodes
运行显示:
【报错1】在 kubeadm init 过程中, [wait-control-plane] 处超时
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime.
To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all running Kubernetes containers by using crictl:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock ps -a | grep kube | grep -v pause'
Once you have found the failing container, you can inspect its logs with:
- 'crictl --runtime-endpoint unix:///var/run/containerd/containerd.sock logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster
To see the stack trace of this error execute with --v=5 or higher
解决:原因为 kubeadm config images list 中的镜像没有完全拉取成功,建议更换 init 的镜像仓库或注意版本正确和重命名时细节错误
【报错2】container runtime is not running
[init] Using Kubernetes version: v1.28.3
[preflight] Running pre-flight checks
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR CRI]: container runtime is not running: output: time="2023-10-24T05:24:13Z" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
, error: exit status 1
[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
To see the stack trace of this error execute with --v=5 or higher
解决:
sudo rm /etc/containerd/config.toml
sudo systemctl restart containerd
【报错3】在 kubeadm init 时进程被占用或文件已存在
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR Port-10259]: Port 10259 is in use
[ERROR Port-10257]: Port 10257 is in use
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR CRI]: container runtime is not running: output: time="2023-10-12T07:02:00Z" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
解决:这三个方法依次尝试
方法一:(一般这样就可以了)
kubeadm reset
方法二:结束进程
方法三:
- 移除旧的容器:
apt remove containerd - 更新库数据安装新的容器:
apt update && apt install containerd.io - 重启容器:
systemctl restart containerd - Set up the Docker repository as described in https://docs.docker.com/engine/install/ubuntu/#set-up-the-repository
- Remove the old containerd:apt remove containerd
- Update repository data and install the new containerd: apt update, apt install containerd.io
- Remove the installed default config file: rm /etc/containerd/config.toml
- Restart containerd: systemctl restart containerd
【报错4】已有pause:3.9但是只能识别pause:3.6
[init] Using Kubernetes version: v1.28.3
[preflight] Running pre-flight checks
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
W1024 05:25:43.062430 32726 checks.go:835] detected that the sandbox image "registry.k8s.io/pause:3.6" of the container runtime is inconsistent with that used by kubeadm.
It is recommended that using "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9" as the CRI sandbox image.
解决方法:
mkdir /etc/containerd
containerd config default > /etc/containerd/config.toml
vim /etc/containerd/config.toml
# [plugins."io.containerd.grpc.v1.cri"]块下的sandbox_image值改为国内镜像即可(pause版本因人而异)
# 该行3.6改为3.9,前面的地址改为你需要的地址
# 比如我的初始化采用的国内镜像地址为:--image-repository='registry.cn-hangzhou.aliyuncs.com/google_containers'
# 就改为 sandbox_image = "registry.cn-hangzhou.aliyuncs.com/google_containers/pause:3.9"
# 让配置生效
systemctl daemon-reload && systemctl restart containerd
【报错5】The connection to the server localhost:8080 was refused
vagrant@k8s-node1:~$ kubectl get nodes
E1024 08:33:03.904391 28052 memcache.go:265] couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused
E1024 08:33:03.907331 28052 memcache.go:265] couldn't get current server API group list: Get "http://localhost:8080/api?timeout=32s": dial tcp [::1]:8080: connect: connection refused
The connection to the server localhost:8080 was refused - did you specify the right host or port?
解决方法:原因是 init 后没有按提示执行命令
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
(3)安装Calico网络插件(在master上)
kubectl apply -f https://docs.projectcalico.org/v3.21/manifests/calico.yaml
# 或者
wget -O /root/calico.yaml https://gitee.com/qinziteng/K8S/raw/master/YMAL/calico.yaml
kubectl apply -f calico.yaml
三、k8s的使用
角色管理
#为节点添加role
kubectl label nodes <node name> node-role.kubernetes.io/<node role>=
#减去role
kubectl label nodes <node name> node-role.kubernetes.io/<node role>-
查看pod状态
kubectl get pods --all-namespaces -owide
kubectl describe pod calico-node-gj8xr -n kube-system
四、Rancher v2.6
1.部署 Rancher 在 Vagrant
以下过程全部参考rancher官方文档:Rancher v2.6 Docs
Vagrant 需要使用插件来创建 VirtualBox 虚拟机。请执行以下命令进行安装:
vagrant plugin install vagrant-vboxmanage
vagrant plugin install vagrant-vbguest
开始使用
# 使用命令行工具,把 Rancher Quickstart 克隆到本地。
git clone https://github.com/rancher/quickstart
# 进入包含 Vagrantfile 文件的文件夹。
cd quickstart/rancher/vagrant
# (可选)编辑 config.yaml 文件:根据需要更改节点数和内存分配(node.count, node.cpus, node.memory)
# (可选)更改 admin 的密码以登录 Rancher。(admin_password,最少 12 个字符)
# 初始化环境,这可能会花费一段时间
vagrant up --provider=virtualbox
配置完成后,在浏览器中打开 https://192.168.56.101 默认的用户名和密码是 admin/adminPassword
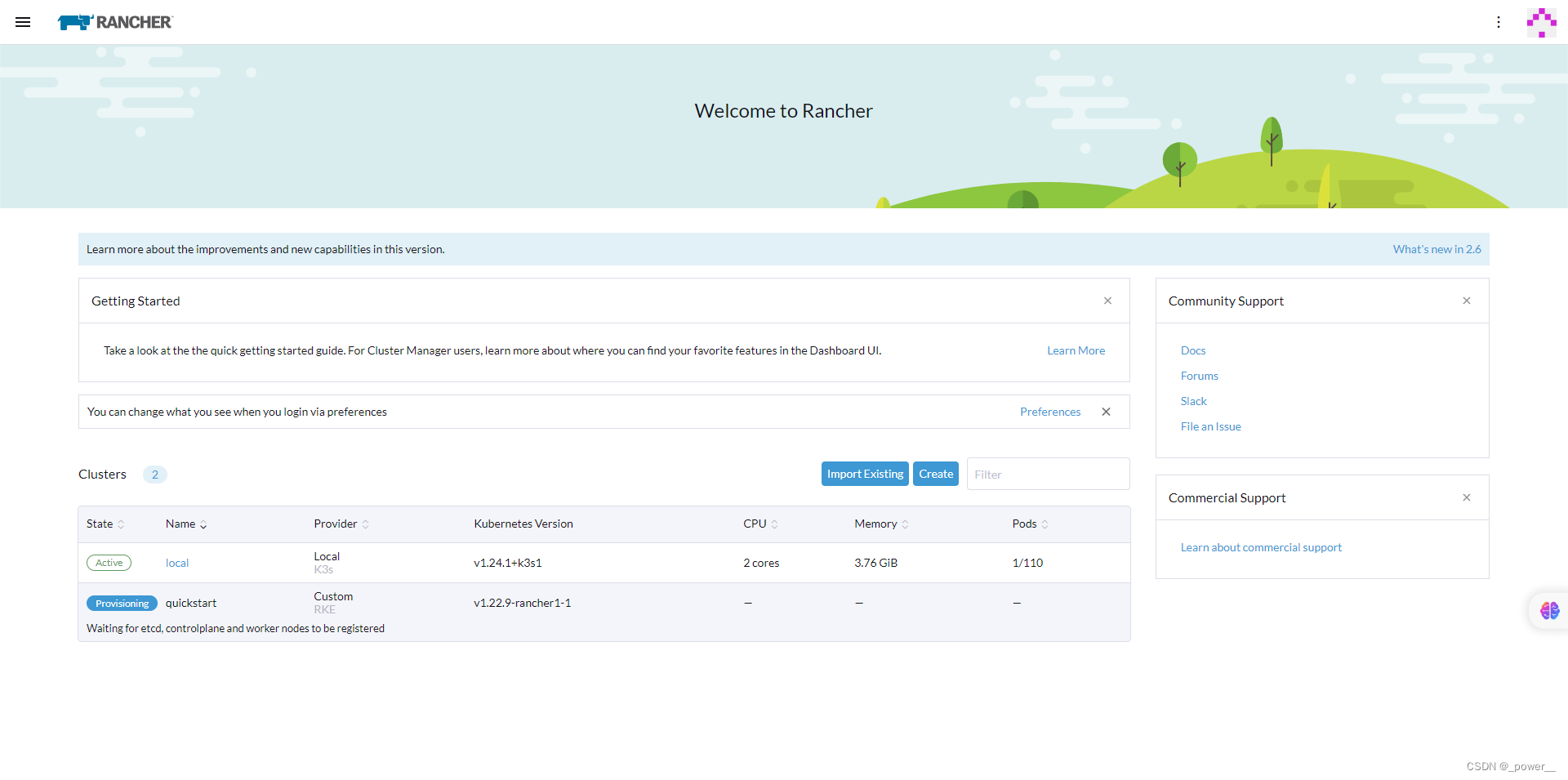
结果:Rancher Server 和你的 Kubernetes 集群已安装在 VirtualBox 上
学习参考
实验环境的选择(私人)
基于vagrant搭建k8s集群
使用kubeadm创建集群失败报Unable to register node with API server
详解linux下查看系统版本号信息的方法(总结)
Kubernetes安装-Ubuntu版
搭建k8s集群初始化master节点 kubeadm init 遇到问题解决
Rancher 添加主机无法显示、添加主机无效的解决办法
血泪史: k8s Initial timeout of 40s passed
kubeadm安装单节点Master的kubernetes
kubeadm init running into issue - [ERROR CRI]: container runtime is not running
registry.k8s.io/pause:3.6 does not use the address specified by --image-repository when executing kubeadm init















 456
456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









