






损失函数|交叉熵损失函数
详解softmax函数以及相关求导过程
1 图像分类
我们希望根据图片动物的轮廓、颜色等特征,来预测动物的类别,有三种可预测的类别:猫、狗、猪。
假设我们当前有两个模型(参数不同),这两个模型都是通过sigmoid/softmax的方式得到对于每个预测结果的概率值:
sigmoid
- 其表达式及函数图像:

softmax

模型1
| 预测 | 真实 | 是否正确 |
|---|---|---|
| 0.3 0.3 0.4 | 0 0 1 (猪) | 正确 |
| 0.3 0.4 0.3 | 0 1 0 (狗) | 正确 |
| 0.1 0.2 0.7 | 1 0 0 (猫) | 错误 |
模型2
| 预测 | 真实 | 是否正确 |
|---|---|---|
| 0.1 0.2 0.7 | 0 0 1 (猪) | 正确 |
| 0.1 0.7 0.2 | 0 1 0 (狗) | 正确 |
| 0.3 0.4 0.3 | 1 0 0 (猫) | 错误 |
Mean Squared Error (均方误差)
均方分误差是一种插件的损失函数,其定义为:
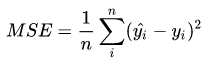
模型1

对所有的样本loss求均值
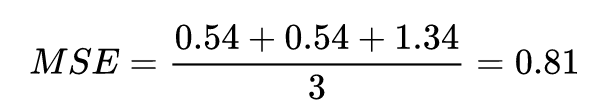
模型2
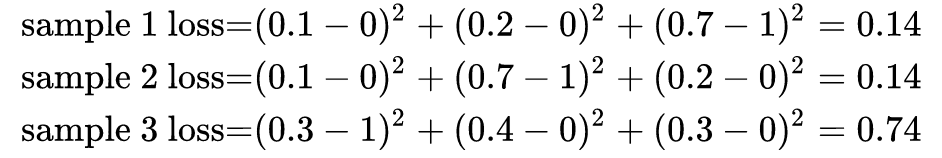
对所有的样本loss求均值
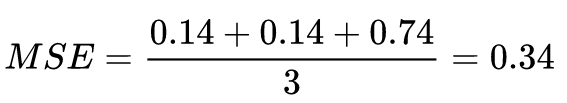
我们发现,MSE能够判断出来模型2由于模型1。
sigmoid缺点:
- 在分类问题中,使用 sigmoid/softmax得到概率,配合MSE损失函数,采用梯度下降法进行学习时,会出现模型在一开始训练的时候,学习速率非常慢。
Cross Entropy Loss Function(交叉熵损失函数)
表达式


模型1
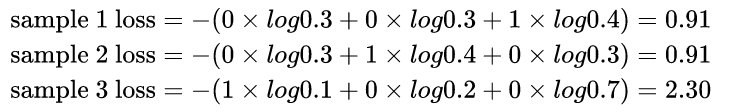
对所有样本的loss求平均:
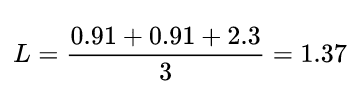
模型2

对所有样本的loss求平均:
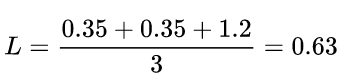
可以发现,交叉熵损失函数可以捕捉到模型1和模型2预测效果的差异。
3 学习过程
交叉熵损失函数经常用于分类问题中,特别是在神经网络中做分类问题是。此外,由于交叉熵设计到计算每个类的概率,所以交叉熵几乎每次都和 sigmoid或者softmax函数一起出现。
我们用神经网络最后一层输出的情况,来看整个模型预测,获得损失和学习的过程:
- 1、神经网络最后一层得到每个类别的得分score(也叫logits);
- 2、该得分经过sigmoid(或者softmax)函数获得概率输出。
- 3、模型预测的类别概率输出与真实类别的one-hot进行交叉熵损失函数计算。
学习任务分为二分类和多分类情况,分开讨论:
3.1 二分类

如上图所示,求导过程可分成三个子过程,即拆成三项偏导的乘积:
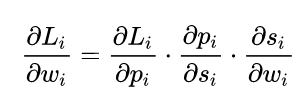




3.2 多分类

多分类求导过程参考详解softmax函数以及相关求导过程
举例:

步骤一: 先求出4、5、6点的输出,然后在用softmax函数求出a5的a6、a7的输出

步骤二:因为是多分类,所以交叉熵损失函数中,是目标类别的yi人为是1,其他的认为是0,所以可以去掉求和操作。
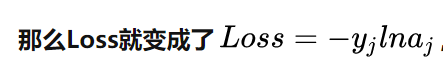
步骤三:求导数
- 在该例子中,参数为w41,w42,w43,w51,w52,w53,w61,w62,w63,比如我想求出w41,w42,w43的偏导,就需要将Loss函数求偏导传到结点4,然后再利用链式法则继续求导即可:

w51…w63等参数的偏导同理可以求出。
那么我们的关键就在于Loss函数对于结点4,5,6的偏导怎么求,如下:
1)当j=i时,此时是 a4对z4求偏导,就是说现在对a4点的求导传给了4点。



- 2)当 j!=i 时,




L1
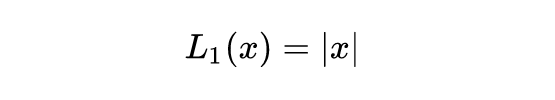
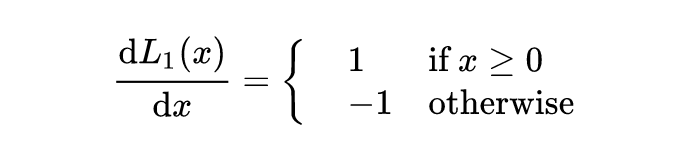
L1对x的倒数为常数。这导致训练后期**,预测值和ground truth差异很小的时,L1损失对预测值的导数的绝对值任然为1**,而learning rate如果不变,损失函数将在稳定值附近波动,难以继续收敛已到达更高的精度。
L2
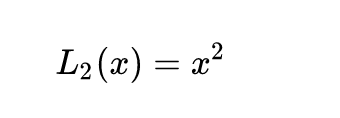
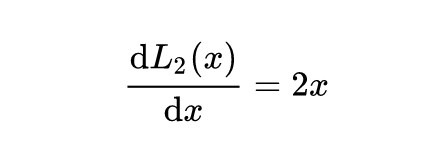
当x增大时,L2损失对x的导数也增大。这导致训练初期时,预测值和ground truth差异过大时,损失函数对预测值的梯度过大,训练十分不稳定。
smoothL1
- 当预测框与 ground truth 差别过大时,梯度值不至于过大;
- 当预测框与 ground truth 差别很小时,梯度值足够小

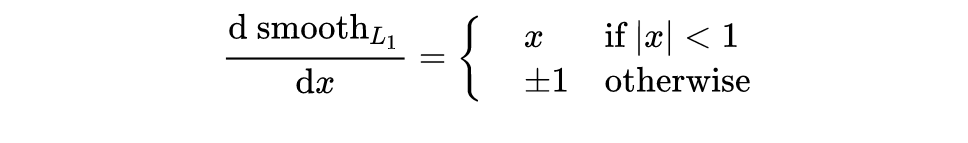
smoothL1在x较小的时候,对x的梯度也会变小,而在x很大的时候,对x的梯度的绝对值叨叨上限值1,不会太大以至于破坏网络参数。smoothL1完美避开了L1和L2的损失的缺陷。其函数图像如调所示
















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









