






无监督学习无标签----学习数据本身的结构和关系,
监督学习有标签----用于预测因变量
监督学习的因变量 (连续--回归 离散--分类)
流程
- 明确项目任务:回归/分类
- 收集数据集并选择合适的特征。
- 选择度量模型性能的指标。
- 选择具体的模型并进行训练以优化模型。
- 评估模型的性能并调参。
回归模型选择
线性\多项式回归
分类回归树---递归分割,将特征空间按递归分割为互不重叠的区域(分块,每个块内不同的函数)
由节点和有向边组成,节点分为内部节点和叶节点.
内部节点表示特征或属性,叶节点表示类别.

避免过拟合的方法:
预剪枝:划分前先用验证集验证,能提高准确性则继续递归生成节点,否则把节点标记为叶节点。
后剪枝:先从训练集生成决策树,再自底向上考察非叶结点,若将该结点对应的子树替换为叶 结点能提升泛化性能,则替换。
支持向量机回归SVR


![]()
KKT条件---局部最优解
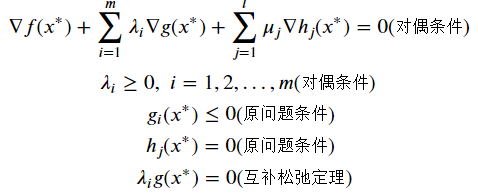

拉格朗日对偶函数d(λ,μ)是原问题最优解f(x*)的下界
将拉格朗日对偶问题(D)转化为
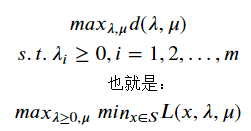
弱对偶定理:对偶问题(D)的最优解D*一定小于原问题最优解P*
而且对偶问题关于λ,μ的线性函数d为凸函数,为凸优化问题
当f(x)与gi(x)为凸函数,hj(x)为线性函数,X是凸集,x∗满足KKT条件,那么取等号𝐷∗=𝑃∗
参考 https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVR.html?highlight=svr#sklearn.svm.SVR
优化模型
![]()
不可约误差Var(𝜀)
偏差度量的是单个模型的学习能力,拟合精确度
方差度量的是同一模型在不同数据集上的稳定性,受扰动影响
一般而言,增加模型的复杂度,会增加方差,减少偏差
特征提取
正则化
降维
调参
稍后会加以补充















 2121
2121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









