







参考教材:《机器学习python实践》
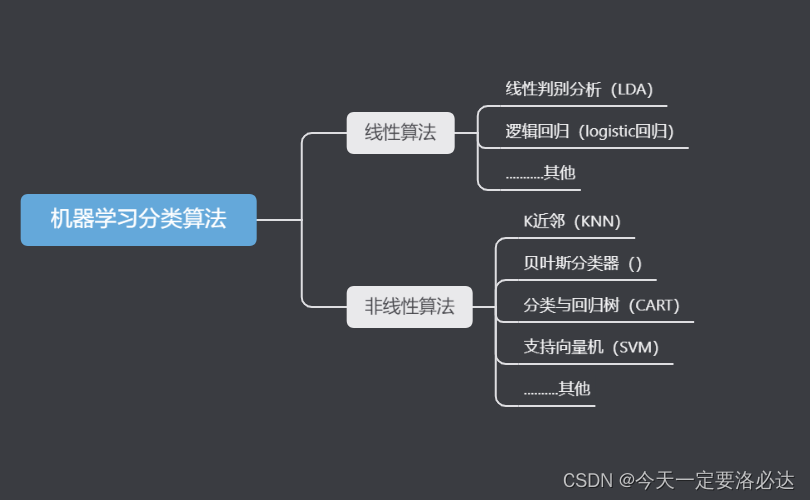
一、主要分类算法总结
二、LDA
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from pandas.plotting import scatter_matrix
file_name='E:/数学建模2022/算法/分类算法/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
f=open(file_name)#因为中文要报错,所以多了这么一个步骤
data=pd.read_csv(f,names=names)
array=data.values #从dataframe数据格式转为矩阵格式,重要的一步
X=array[:,:4] #输入特征
Y=array[:,4] #标签label
seed=7
num_folds=10 #通常取3,5,10,不知道设置为多少时,设为10
#K折交叉验证分离的核心函数
kfold=KFold(n_splits=num_folds,random_state=seed,shuffle=True) #n_splits这里指要分成多少块
model=LinearDiscriminantAnalysis() #选择模型
result=cross_val_score(model,X,Y,cv=kfold,scoring='accuracy')#交叉验证的函数,scoring默认为精度,也可以修改为其他的
print('每一折的精度如下')
print(result)
print('评估结果(平均精度)如下:{}'.format(result.mean()))
print('评估结果(标准方差)如下:{}'.format(result.std()))
三、逻辑回归
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from pandas.plotting import scatter_matrix
file_name='E:/数学建模2022/算法/分类算法/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
f=open(file_name)#因为中文要报错,所以多了这么一个步骤
data=pd.read_csv(f,names=names)
array=data.values #从dataframe数据格式转为矩阵格式,重要的一步
X=array[:,:4] #输入特征
Y=array[:,4] #标签label
seed=7
num_folds=10 #通常取3,5,10,不知道设置为多少时,设为10
#K折交叉验证分离的核心函数
kfold=KFold(n_splits=num_folds,random_state=seed,shuffle=True) #n_splits这里指要分成多少块
model=LogisticRegression() #选择模型
result=cross_val_score(model,X,Y,cv=kfold,scoring='accuracy')#交叉验证的函数,scoring默认为精度,也可以修改为其他的
print('每一折的精度如下')
print(result)
print('评估结果(平均精度)如下:{}'.format(result.mean()))
print('评估结果(标准方差)如下:{}'.format(result.std()))
四、KNN
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from pandas.plotting import scatter_matrix
file_name='E:/数学建模2022/算法/分类算法/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
f=open(file_name)#因为中文要报错,所以多了这么一个步骤
data=pd.read_csv(f,names=names)
array=data.values #从dataframe数据格式转为矩阵格式,重要的一步
X=array[:,:4] #输入特征
Y=array[:,4] #标签label
seed=7
num_folds=10 #通常取3,5,10,不知道设置为多少时,设为10
#K折交叉验证分离的核心函数
kfold=KFold(n_splits=num_folds,random_state=seed,shuffle=True) #n_splits这里指要分成多少块
model=KNeighborsClassifier() #选择模型
result=cross_val_score(model,X,Y,cv=kfold,scoring='accuracy')#交叉验证的函数,scoring默认为精度,也可以修改为其他的
print('每一折的精度如下')
print(result)
print('评估结果(平均精度)如下:{}'.format(result.mean()))
print('评估结果(标准方差)如下:{}'.format(result.std()))
五、贝叶斯
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from pandas.plotting import scatter_matrix
file_name='E:/数学建模2022/算法/分类算法/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
f=open(file_name)#因为中文要报错,所以多了这么一个步骤
data=pd.read_csv(f,names=names)
array=data.values #从dataframe数据格式转为矩阵格式,重要的一步
X=array[:,:4] #输入特征
Y=array[:,4] #标签label
seed=7
num_folds=10 #通常取3,5,10,不知道设置为多少时,设为10
#K折交叉验证分离的核心函数
kfold=KFold(n_splits=num_folds,random_state=seed,shuffle=True) #n_splits这里指要分成多少块
model=GaussianNB() #选择模型
result=cross_val_score(model,X,Y,cv=kfold,scoring='accuracy')#交叉验证的函数,scoring默认为精度,也可以修改为其他的
print('每一折的精度如下')
print(result)
print('评估结果(平均精度)如下:{}'.format(result.mean()))
print('评估结果(标准方差)如下:{}'.format(result.std()))
六、CART
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from pandas.plotting import scatter_matrix
file_name='E:/数学建模2022/算法/分类算法/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
f=open(file_name)#因为中文要报错,所以多了这么一个步骤
data=pd.read_csv(f,names=names)
array=data.values #从dataframe数据格式转为矩阵格式,重要的一步
X=array[:,:4] #输入特征
Y=array[:,4] #标签label
seed=7
num_folds=10 #通常取3,5,10,不知道设置为多少时,设为10
#K折交叉验证分离的核心函数
kfold=KFold(n_splits=num_folds,random_state=seed,shuffle=True) #n_splits这里指要分成多少块
model=DecisionTreeClassifier() #选择模型
result=cross_val_score(model,X,Y,cv=kfold,scoring='accuracy')#交叉验证的函数,scoring默认为精度,也可以修改为其他的
print('每一折的精度如下')
print(result)
print('评估结果(平均精度)如下:{}'.format(result.mean()))
print('评估结果(标准方差)如下:{}'.format(result.std()))
七、支持向量机
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from pandas.plotting import scatter_matrix
file_name='E:/数学建模2022/算法/分类算法/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
f=open(file_name)#因为中文要报错,所以多了这么一个步骤
data=pd.read_csv(f,names=names)
array=data.values #从dataframe数据格式转为矩阵格式,重要的一步
X=array[:,:4] #输入特征
Y=array[:,4] #标签label
seed=7
num_folds=10 #通常取3,5,10,不知道设置为多少时,设为10
#K折交叉验证分离的核心函数
kfold=KFold(n_splits=num_folds,random_state=seed,shuffle=True) #n_splits这里指要分成多少块
model=SVC() #选择模型
result=cross_val_score(model,X,Y,cv=kfold,scoring='accuracy')#交叉验证的函数,scoring默认为精度,也可以修改为其他的
print('每一折的精度如下')
print(result)
print('评估结果(平均精度)如下:{}'.format(result.mean()))
print('评估结果(标准方差)如下:{}'.format(result.std()))
八、总结
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
plt.rcParams['font.sans-serif']=['SimHei']#显示中文标签
plt.rcParams['axes.unicode_minus']=False
file_name='E:/数学建模2022/算法/分类算法/iris.csv'
names=['separ-length','separ-width','petal_length','petal_width','class']
f=open(file_name)#因为中文要报错,所以多了这么一个步骤
data=pd.read_csv(f,names=names)
array=data.values #从dataframe数据格式转为矩阵格式,重要的一步
X=array[:,:4] #输入特征
Y=array[:,4] #标签label
seed=7
num_folds=10 #通常取3,5,10,不知道设置为多少时,设为10
#K折交叉验证分离的核心函数
kfold=KFold(n_splits=num_folds,random_state=seed,shuffle=True) #n_splits这里指要分成多少块
models={}
models['LDA']=LinearDiscriminantAnalysis() #选择模型
models['LR']=LogisticRegression() #选择模型
models['KNN']=KNeighborsClassifier() #选择模型
models['NB']=GaussianNB() #选择模型
models['CART']=DecisionTreeClassifier() #选择模型
models['SVM']=SVC() #选择模型
results=[]
for name in models:
result = cross_val_score(models[name], X, Y, cv=kfold, scoring='accuracy') # 交叉验证的函数,scori
results.append(result)
print('{}的评估结果(平均精度)为:{},评估结果(标准方差)如下:{}'.format(name,result.mean(),result.std()),)
fig1=plt.figure()
ax=fig1.add_subplot(111)
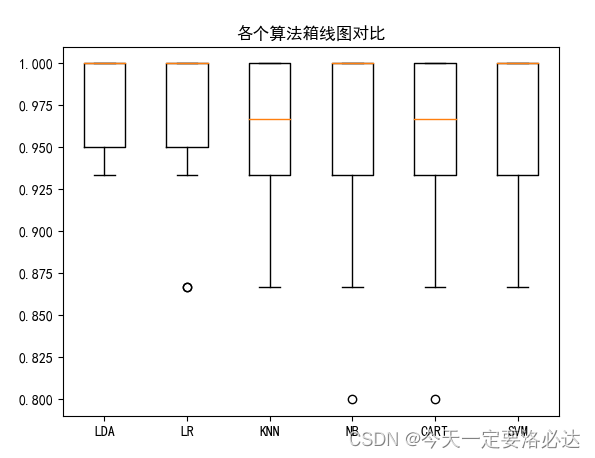
plt.boxplot(results)
ax.set_xticklabels(models.keys())
plt.title('各个算法箱线图对比')
plt.show()
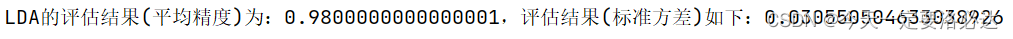
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









