







文章目录
基本语法
五、流程控制语句
1.if
语法结构
if 条件表达式: # 用冒号代表语句块开始
代码块 # 缩进非常重要
a = 10
if a > 10:
print('大于10')
print('hello')
补充:键盘输入input()函数
name = input('请输入您的姓名')
print(type(name),name) # 所有输入的内容都是当作字符串
2.if-else
if 条件表达式 :
代码块
else :
代码块
3.if-elif-else
if 条件表达式 :
代码块
elif 条件表达式 :
代码块
elif 条件表达式 :
代码块
elif 条件表达式 :
代码块
else :
代码块
六、数据类型之对象类型
1.序列
序列是python中最基本的一种数据结构,数据结构是指数据存储的方式
序列是保存一组有序的数据,所有的数据在序列中都有一个唯一的(位置)索引
序列中的有序,指的是数据放入的顺序有序
序列的分类
- 可变序列
列表list
- 不可变序列
字符串str
元组tuple
(1)列表
python中的一个对象,列表用来保存多个有序的数据,列表是用来存储对象的对象
列表(List)是Python中使用最多的数据类型,在其他语言中通常叫数组
Python中的列表比其他语言中的数组功能要强得多
①创建列表
使用[]创建列表,用逗号(,)分割元素
列表中可以保存任意类型的元素
可以通过索引访问控制列表中的元素,索引从0开始,超出范围会报错IndexError: list index out of range
使用len() 函数可以获得列表元素的个数
arr = [] # 创建空列表
arr = [1,2,3,4,8,6] # 在创建的时候就指定元素
print(arr, type(arr)) # [1, 2, 3, 4, 8, 6] <class 'list'>
# 列表中可以保存任意类型的元素
arr = [1,'Hello',True,None,[1,3,4], print]
print(arr) # [1, 'Hello', True, None, [1, 3, 4], <built-in function print>]
print(arr[0]) # 1
列表强大的地方
- 可以使用负数来获取元素,-1代表最后一个元素,-2代表倒数第二个元素
print(arr[-1]) # <built-in function print>
- 支持更多的运算符
- 支持切片
②遍历列表
i =0
while i<len(arr):
print(arr[i])
i += 1
'''
1
Hello
True
None
[1, 3, 4]
<built-in function print>
'''
# 用负数索引遍历
i = -1
while i>= -len(arr):
print(arr[i])
i -= 1
'''
<built-in function print>
[1, 3, 4]
None
True
Hello
1
'''
# 用for循环遍历
for i in arr:
print(i)
'''
1
Hello
True
None
[1, 3, 4]
<built-in function print>
'''
③+和*在列表中的使用
+号可以将两个列表拼接成一个列表
*号可以将列表复制指定次数
arr2 = [1,2,3]+[4,5,6]
print(arr2) # [1, 2, 3, 4, 5, 6]
print(arr2*3) # [1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6, 1, 2, 3, 4, 5, 6]
④in 和 not in在列表中的使用
in 用来检测指定元素在列表中,在就返回True
not in 检测指定元素不在列表中,不在就返回True
print(10 in arr2) # False
print(10 not in arr2) # True
⑤切片
切片就是在现有列表的基础上,获取一个子列表
做切片的时候,总是返回一个新的列表,不会影响原有的列表
列表[起始:结束:步长]
起始包含在子列表中,但是结束不包含在新列表中
起始,结束,步长都可以缺省
起始缺省就是从头开始切
结束缺省就是一直切到最后一个元素
步长默认是1
arr3 = arr2[::]
print(arr3) # [1, 2, 3, 4, 5, 6]
print(id(arr2),id(arr3)) # 2493090232640 2493090233152
print(arr2 == arr3) # True
print(arr2[2:]) # [3, 4, 5, 6]
print(arr2[:3]) # [1, 2, 3] 结束位置是3,不包含第三个
print(arr2[::2]) # [1, 3, 5]
print(arr2[1::2]) # [2, 4, 6]
# 步长可以取负数,代表倒过来取元素,不能取0
print(arr2[::-1]) # [6, 5, 4, 3, 2, 1]
**切字符串**
s = 'abcdefghijk'
print(s[0:3]) # abc
print(s[:-3]) # abcdefgh
print(s[::2]) # acegik
print(s[::-1]) # kjihgfedcba
⑥列表中的增删改查
- dir可以用来查看对象的方法和属性
print(dir(arr2))
'''
['__add__', '__class__', '__class_getitem__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
'''
- 修改:直接修改索引对应的元素
arr2[2] = 33
print(arr2) # [1, 2, 33, 4, 5, 6]
- 删除del

del arr2[2]
print(arr2) # [1, 2, 4, 5, 6] 原始序列里面的第二个元素33被删除了
- 切片修改(改的是原始的)
arr2 = [1,2,3,4,5,6]
arr2[0:2] = [10,20] # 使用10和20替换0和1索引上的元素
print(arr2) # [10, 20, 3, 4, 5, 6]
arr2[0:2] = [10,30,50] # 新元素替换原来位置的元素,在这是拿3个替换了2个
print(arr2) # [10, 30,50, 3, 4, 5, 6]
如果设置了步长,序列中的元素个数必须和切片中的元素个数一样

arr2 = [1,2,3,4,5,6,7]
arr2[::2] = [10,30,50,70]
print(arr2) # [10, 2, 30, 4, 50, 6, 70]
- 切片删除
arr2 = [1,2,3,4,5,6]
del arr2[0:2]
print(arr2) # [3, 4, 5, 6]
arr2 = [1,2,3,4,5,6]
arr2[1:4] = []
print(arr2) # [1, 5, 6]
- 删除最后一个元素:三种方法
arr2 = [1,2,3,4,5,6]
# del arr2[-1:]
# del arr2[len(arr2)-1]
# arr22[-1:]=[]
print(arr2)
切片修改删除只用可变序列,字符串不可以用切片修改删除的方法
⑦列表通用方法
| 函数 | 功能 | 说明 |
|---|---|---|
| len | 获取容器元素个数 | |
| del | 删除变量 | |
| max | 返回容器中的最大值 | 一定是可排序的 |
| min | 返回容器中的最小值 | 一定是可排序的 |
可以使用**对象.方法()**方式调用
| 函数 | 功能 | 说明 |
|---|---|---|
| index | 找出某个元素在列表中的位置 | |
| append | 在列表的末尾增加元素 | |
| insert | 插入新元素到指定位置,第一个参数是索引 | |
| extend | 将另外一个列表追加到后面 | |
| reomve | 删除列表中的第一个指定元素,如果元素不存在则报错 | |
| clear | 清空 | |
| pop | 默认弹出最后一个元素,也支持索引弹出 | |
| count | 统计列表中元素的个数 | |
| sort | 排序,默认是升序 |
arr = ['zhangsan','lisi','wangwu']
print(arr.index('lisi')) # 1
arr.append('chenliu')
print(arr) # ['zhangsan', 'lisi', 'wangwu', 'chenliu']
arr.insert(1,'tianqi')
print(arr) # ['zhangsan', 'tianqi', 'lisi', 'wangwu', 'chenliu']
# 一次只能插入一个对象
arr.insert(1,['tinaqi,huba'])
print(arr)
# ['zhangsan', ['tinaqi,huba'], 'tianqi', 'lisi', 'wangwu', 'chenliu']
arr2 = [1,2,3]
arr.extend(arr2)
print(arr)
# ['zhangsan', ['tinaqi,huba'], 'tianqi', 'lisi', 'wangwu', 'chenliu', 1, 2, 3]
# 追加字符串的时候,实际是追加一个个字符的列表
arr.extend('xu9')
print(arr)
# ['zhangsan', ['tinaqi,huba'], 'tianqi', 'lisi', 'wangwu', 'chenliu', 1, 2, 3, 1, 2, 3, 1, 2, 3, 'x', 'u', '9']

arr = ['zhangsan','lisi','wangwu']
arr.remove('lisi')
print(arr) # ['zhangsan', 'wangwu']
arr = ['zhangsan','lisi','lisi','wangwu']
arr.remove('lisi') #只删除第一个
print(arr) # ['zhangsan','lisi','wangwu']
arr = ['zhangsan','lisi','wangwu']
arr.pop()
print(arr) # ['zhangsan', 'lisi']
arr = ['zhangsan','lisi','wangwu']
arr.pop(1)
print(arr) # ['zhangsan', 'wangwu']
arr = [1,2,3,1,1,2,2,3,3,3,4,5]
print(arr.count(4)) # 1
arr.sort()
print(arr) # [1, 1, 1, 2, 2, 2, 3, 3, 3, 3, 4, 5]
arr.sort(reverse=True)
print(arr) # [5, 4, 3, 3, 3, 3, 2, 2, 2, 1, 1, 1]
arr = [1,2,3]
arr.reverse() #并不产生新的列表
print(arr) # [3,2,1]
#切片产生新的列表
arr = [1,2,3]
arr2 = arr[::-1]
print(id(arr2),id(arr)) # 2493094230656 2493094175744
⑧range函数:
一个用来生成自然数序列的函数
arr = range(5) # # 生成0~4的自然数序列
for i in arr:
print(i)
'''
0
1
2
3
4
'''
print(list(arr)) # [0, 1, 2, 3, 4]
可以通过range() 创建一个指定执行次数的for循环
for i in range(1,11):
print(i)
else:
print("end")
'''
1
2
3
4
5
6
7
8
9
10
end
'''
对多层循环的处理:跳出两层循环
错误示范:break只跳出了一层for循环

- 封装到一个方法里,用return来解决(return只能用在函数体里面)
def f():
for i in range(1,10):
for j in range(1,i+1):
if i*j > 25:
return
print("%d*%d=%d"%(i,j,i*j),end='')
print()
f()
'''
1*1=1
2*1=2 2*2=4
3*1=3 3*2=6 3*3=9
4*1=4 4*2=8 4*3=12 4*4=16
5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
6*1=6 6*2=12 6*3=18 6*4=24
'''
- 通过写一个布尔变量,来判断是否跳出
flag = True
for i in range(1,10):
for j in range(1,i+1):
if i*j > 25:
flag = False
break
print("%d*%d=%d"%(i,j,i*j),end=' ')
if not flag:
break
print()
- 用循环自带的else结构来实现(官方给的处理方案)
第二层子循环中,如果是正常执行完for j循环则接着执行else中的的内容,else中continue是继续执行外层循环for i;
如果for j 循环遇到if i*j > 25不正常执行,则break跳出for j 循环,接着就到了for i 循环的最后一步break,实现了跳出for i 循环
for i in range(1,10):
for j in range(1,i+1):
if i*j > 25:
break
print("%dx%d=%d"%(i,j,i*j),end=' ')
else:
print()
continue
break
- 抛出异常
(2)元组Tuple
元组是一个不可变的序列,所有的操作方式和列表一致
# 使用()来常见元组
t = () # 创建一个空的元组
print(t,type(t)) # () <class 'tuple'>
t1 = (1,2,3,4,5)
print(t1) # (1,2,3,4,5)
# 使用[index]去访问tuple中的元素
print(t1[3]) # 4
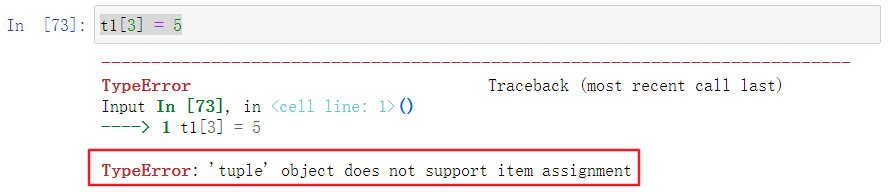
元组中的元素不可修改
# 当tuple不是空的时候,可以省略()
t2 = 10,20,30,40,50
print(t2) # (10, 20, 30, 40, 50)
# 元组的解包
a,b,c,d,e = t2
print(a)
print(b)
print(c)
print(d)
print(e)
'''
10
20
30
40
50
'''
# 可以利用元组的解包特点来交换数值
a = 10
b = 20
a,b = b,a
print(a,b) # 20 10
# 解包前后要匹配
# 少了会
# ValueError: too many values to unpack (expected 4)
# 多了会
# ValueError: not enough values to unpack (expected 6, got 5)
# 可以利用*号来匹配元组,只能出现一次
a,b,*c = t2
print(a)
print(b)
print(c)
'''
10
20
[30, 40, 50]
'''
(3)序列的比较
arr1 = [1,2,3]
arr2 = [1,2,3]
print(arr1==arr2) # True
# 在python中==就是比较两个序列的值,java不是
print(id(arr1),id(arr2)) # 2493094705344 2493094719424
t1 = 1,2,3
t2 = 1,2,3
print(t1 == t2) #True
print(id(t1),id(t2)) # 2493094810560 2493094810304
# 比较是否是同一个 is修饰符
print(t1 is t2) # False
print(arr1 is arr2) # False
2.字典
字典相当于Java的map结构,Java中的HashMap
列表的存储性能很好,列表是最快索引查找,如果是查询某一个,性能很差
链表是适合最简单的增加和删除
字典因为是key-value结构,查询特定元素很快
d = {} #创建一个空字典
print(d,type(d)) # {} <class 'dict'>
d = {'zhangsan':80,'lisi':90,'wangwu':100}
print(d,type(d)) # {'zhangsan': 80, 'lisi': 90, 'wangwu': 100} <class 'dict'>
# 字典的值可以是任意对象,键是不可变对象,一般都使用字符串(str,int, tuple, bool)
# 使用键来获取值
print(d['zhangsan']) # 80
print(d['yangmi']) # 如果键不存在,会报错 KeyError: 'yangmi'
# 可以使用dict函数来创建字典,参数名就是键(字符串),值就是值
d3 = dict(name='zhangsan',age=20)
print(d3) # {'name': 'zhangsan', 'age': 20}
# len()返回字典键的个数
# in可以判断是否存在某个键
# get可以根据键去获取值,支持默认值
print(d3.get('name')) #zhangsan
print(d3.get('gender')) # None
# 如果gender为None,则使用默认值'男'
print(d3.get('gender','男')) # 男
# 可以通过修改键直接修改值,如果该值不存在则添加
d3['gender'] = '女'
print(d3) # {'name': 'zhangsan', 'age': 20, 'gender': '女'}
# 如果存在值则不添加,否则添加一个默认值
d3.setdefault('score','80')
print(d3) # {'name': 'zhangsan', 'age': 20, 'gender': '女', 'score': '80'}
# 删除
del d3['score']
print(d3) # {'name': 'zhangsan', 'age': 20, 'gender': '女'}
d3 = dict(name='zhangsan',age=20)
a = d3.pop('name')
print(a,type(a)) # zhangsan <class 'str'>
print(d3) # {'age': 20}
# popitem
d3 = dict(name='zhangsan',age=20)
a = d3.popitem()
print(a,type(a),d3) # ('age', 20) <class 'tuple'> {'name': 'zhangsan'}
# 遍历
# 遍历键
d = {'zhangsan':80,'lisi':90,'wangwu':100}
for key in d.keys():
print(key,d[key])
'''
zhangsan 80
lisi 90
wangwu 100
'''
# 遍历值
for v in d.values():
print(v)
'''
80
90
100
'''
# items取出的都是tuple,可以解包用
for k,v in d.items():
print(k,v)
'''
zhangsan 80
lisi 90
wangwu 100
'''
字典的一个运用
最新的3.10里面python支持了switch-case,之前的版本不支持,可以用字典来实现
def do_0():
print(0)
def do_1():
print(1)
def do_2():
print(2)
switch = {'零':do_0,'一':do_1,'二':do_2}
switch.get('零')() # 0
3.字符串
字符串是python中最博大精深的,函数功能非常多和复杂
'capitalize',
'casefold',
'center',
'count',
'encode',
'endswith',
'expandtabs',
'find', 在指定范围内找一个字符串,相当于java indexOf 没有返回-1
'format',
'format_map',
'index', 和find一样,没有找到就直接报错
'isalnum', 都是字母和数字
'isalpha', 都是字母
'isascii',
'isdecimal', 都是数字
'isdigit', 只包含数字(支持多进制)
'isidentifier',
'islower',
'isnumeric', 都是数字
'isprintable',
'isspace',
'istitle',
'isupper',
'join',
'ljust',
'lower',
'lstrip',
'maketrans',
'partition', 将字符串分成
'removeprefix',
'removesuffix',
'replace',
'rfind', 从右到左找 相当于java lastIndexOf
'rindex',
'rjust',
'rpartition',
'rsplit',
'rstrip', 去除右边的空白
'split',
'splitlines',
'startswith',
'strip',
'swapcase',
'title',
'translate',
'upper',
'zfill'
b = '0' # '\u00b3' '零'
print(b.isdecimal()) # True False False
print(b.isdigit()) # True True False
print(b.isnumeric()) # True True True 可以支持中文大小写
s = 'abaacaa'
s1 = s.replace('a','c',2) # 可以指定次数哦,默认是全部替换
print(s1) # cbcacaa
s = 'aaaaabcccc'
s2 = s.partition('b')
print(s2) # ('aaaaa', 'b', 'cccc')
s = 'aaaaabcccc'
s2 = s.partition('a')
print(s2) # ('', 'a', 'aaaabcccc')
s = 'aaaaabcccc'
s2 = s.partition('c')
print(s2) # ('aaaaab', 'c', 'ccc')
s = 'aaaaabbcccc'
s2 = s.rpartition('b')
print(s2) # ('aaaaab', 'b', 'cccc')
# split 和java一样,通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串,str.split(str="", num=string.count(str)).
s2 = s.split('a')
print(s2) # ['', '', '', '', '', 'bbcccc']
s2 = s.split('a',2)
print(s2) # ['', '', 'aaabbcccc']
4.集合
对应数学中的set 集合
和java中的Set 一样,不保证顺序,不可重复
a = {1,2,3,4,5}
print(a,type(a)) # {1, 2, 3, 4, 5} <class 'set'>
a = {1,2,3}
b = set('abc')
a.update(b) # 将b加到a里面
print(a) # {1, 2, 3, 'a', 'b', 'c'}
a = {1,2,3}
b = {'name':'zhangsan','age':20}
a.update(b)
print(a) # {1, 2, 3, 'name', 'age'}
a = {1,2,3}
b = {1:'zhangsan',2:'lisi'}
a.update(b)
print(a) # {1,2,3} 集合的元素不可重复
集合的运算
# 交集
a = {1,2,3,4,5,6}
b = {3,4,5,6,7,8}
print(a&b) # {3, 4, 5, 6}
# 并集
print(a | b) # {1, 2, 3, 4, 5, 6, 7, 8}
# 差集
print(a-b) # {1,2}
print(b-a) # {8,7}
print(a-a) # set()
#异或
print(a ^ b) # {1, 2, 7, 8}
print((a|b)-(a&b)) # {8, 1, 2, 7}
# 一个集合是否包含于另外一个集合<
a = {1,2,3}
b = {1,2,3,4,5}
print(a < b) # True
# 一个集合是否是另外一个集合的超集>
a = {1,2,3}
b = {1,2,3,4,5}
print(a > b) #True














 6672
6672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









