









本文是课程《数据科学与金融计算》第2-3章的学习笔记,主要介绍R语言在统计和机器学习中的应用,用于知识点总结和代码练习,Q&A为问题及解决方案,参考书籍为《R软件及其在金融定量分析中的应用》。
往期回顾:
| 博文 | 内容 |
|---|---|
| 【R】【课程笔记】01 R软件基础知识 | 数据类型、数据结构、运算、绘图等 |
| 【R】【课程笔记】02+03 基于R软件的计算 | 聚类分析、因子分析、神经网络、支持向量机等 |
| 【R】【课程笔记】04+05 数据预处理+收益率计算 | 金融数据处理、收益率、R与C++等 |
| 【R】【课程笔记】06 金融波动模型 | GARCH、SV、高频波动模型等 |
| 【R】【课程笔记】07 分位数回归与VaR(ES)计算 | VaR、ES、极值模型等 |
| 【R】【课程笔记】08 金融投资组合决策分析 | 均值-方差模型、均值-VaR模型、均值-CVaR模型等 |
目录
一、框架
二、代码
2.1 统计分析
1. 多元回归分析
多元回归分析包括:线性回归、逐步回归法
Q:怎么读取Excel表格数据(.xlsx)?“xlsx”包无法加载。
A:“xlsx”包需要加载 rJava和xlsxjars包,推荐“openxlsx”包,打开excel命令:read.xlsx(xlsxFile, sheet = 1),且无需使用命令:encoding = "UTF-8"读取中文字符。
或:装上Java[1],默认安装位置。
案例:货币的需求由三个层面组成:交易性货币需求、预防性货币需求、投机性货币需求
library(openxlsx)
#线性回归
# 1. read data from EXCEL file
dat <- read.xlsx('MacEcoData.xlsx', sheet='data1')
# 2. do logrithm operation
dat.log <- log(dat)
names(dat) # 包含"M2" "CPI" "ir" "GY"
# 3. make linear model using lm and poisson
model.lm <- lm(M2~., data=dat.log) # 线性回归,因变量为M2
class(model.lm)
print(model.lm)
summary(model.lm)
model.poisson <-glm(formula = M2~ CPI+ir+GY, # 泊松分布
family = poisson, data = dat.log)
class(model.poisson)
print(model.poisson)
summary(model.poisson)
# 4. check model
# (1) based on residuals
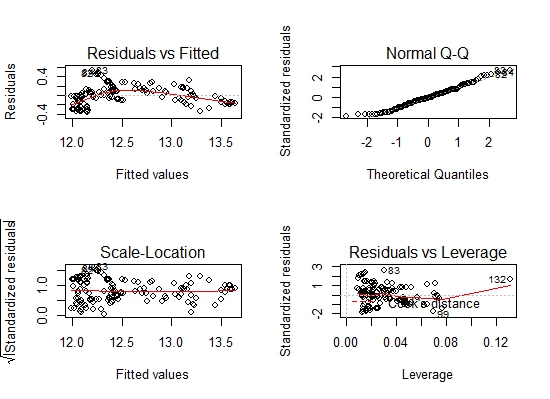
par(mfrow=c(2,2))
plot(model.lm) # 残差,Q-Q图,Cook距离,杠杆点
par(mfrow=c(1,1))
# 5. extract informaiton of model
# (1) get coefs # 系数
names(model.lm)
(coefs.lm <- coef(model.lm))
# (2) get fitted values # 拟合值
(fit.lm <- predict(model.lm, se.fit=TRUE))
# (3) get residuals # 残差
(res.lm <- resid(model.lm))
# (4) get R square and sigma
mode(summary(model.lm)) # 类型为list()
names(summary(model.lm))
(R2 <- summary(model.lm)$r.squared) # R2
(sigma <- summary(model.lm)$sigma) # 残差
# 6. forecast
# (1) set values # 赋值,数据框格式
tt <- 1:5
CPI.hat <- dat$CPI[nrow(dat)]*1.05^tt
ir.hat <- dat$ir[nrow(dat)]*1.00^tt
GY.hat <- dat$GY[nrow(dat)]*1.05^tt
NewData <- data.frame(CPI=CPI.hat, ir=ir.hat, GY=GY.hat)
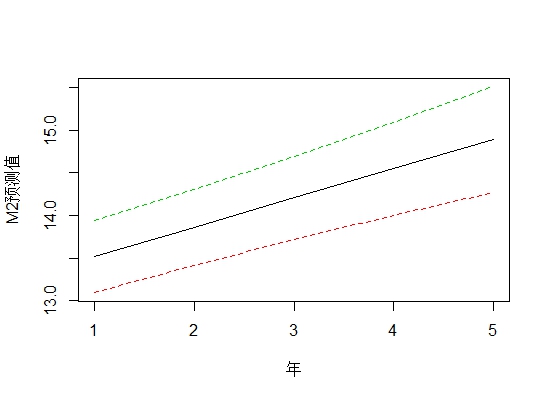
# (2) predict # 预测
M2.hat <- predict(model.lm, newdata=log(NewData),
interval='prediction')
matplot(M2.hat, lty=c(1,2,2), type='l', xlab='年',ylab = "M2预测值")
#逐步回归法
# 1. read data from EXCEL file
dat <- read.xlsx(file='MicEcoData.xlsx', sheetName='stepReg')
names(dat) <- c('y', paste('x', 1:7, sep=''))
# 2. do linear regression
model.lm <- lm(y~.,data=dat);
summary(model.lm)
# 3. do regression step by step
model.step <- step(model.lm)
#根据AIC原则:lm(formula = y ~ x1 + x4 + x5 + x6 + x7, data = dat)
summary(model.step)
# 4. Multicollinearity:VIF
#对每个因子,用其他n-1个因子进行回归解释。处理:删除不显著的变量。
VIF <- function(x) #自定义函数
{
n = dim(x)[2]
vf = NULL
for (i in 1:n)
{
y = x[,i]
z = x[-i]
dat = data.frame[y=y,z]
tmp=lm(y~.,data=dat)
tmp=1/(1-cor(y,predict(tmp))^2)
vf=c(vf,tmp)
}
vf
}
vifres = VIF(data[,-1])
names(vifres) <- names(data)[-1]
vifres
dat = data[,5]
vifres1 = VIF(dat[,-1])
names(vifres1) <- names(dat)[-1]
vifres1
2. 聚类分析
案例:分别从农业(1-10)、金融保险(11-20)、制造业(21-30)板块各取10家公司,根据其财务报表中选取7项财务指标:营业总收入、营业利润、利润总额、净利润、基本每股收益、稀释每股收益、综合收益指数,对上市公司进行聚类。
# 1. read data from EXCEL file
dat <- read.xlsx('MicEcoData.xlsx', sheet='clust')
names(dat) <- c('label', paste('x', 1:7, sep=''))
# 2. data process
dist.matrix <- dist(scale(dat)) # scale():标准化,dist():计算距离
# 3. do cluster #分层聚类:hclust()
h.result1=hclust(dist.matrix, method="complete")
h.result2=hclust(dist.matrix, method="average")
h.result3=hclust(dist.matrix, method="ward.D")
h.result4=hclust(dist.matrix, method="centroid");
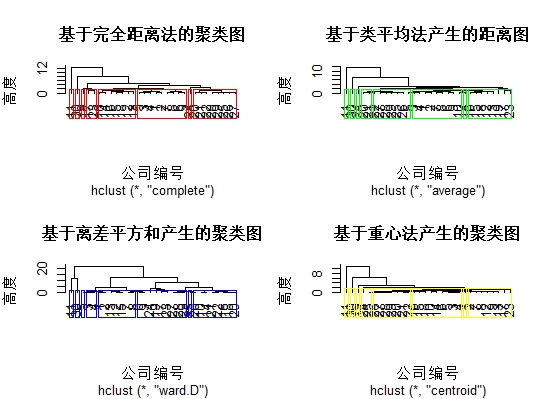
# 4. show results #k=8:聚8类
par(mfrow=c(2,2))
plot(h.result1,hang=-1,main='基于完全距离法的聚类图',xlab='公司编号',ylab='高度')
result1=rect.hclust(h.result1,k=8,border="red")
plot(h.result2,hang=-1,main='基于类平均法产生的距离图',xlab='公司编号',ylab='高度')
result1=rect.hclust(h.result1,k=8,border="green")
plot(h.result3,hang=-1,main='基于离差平方和产生的聚类图',xlab='公司编号',ylab='高度')
result1=rect.hclust(h.result1,k=8,border="blue")
plot(h.result4,hang=-1,main='基于重心法产生的聚类图',xlab='公司编号',ylab='高度')
result1=rect.hclust(h.result1,k=8,border="yellow")
3. 因子分析
案例:对上市公司财务报表中的10项指标:销售费用、管理费用、财务费用、营业利润、利润总额、净利润、基本每股收益、稀释每股收益、综合收益、营业总收入进行因子分析,并根据因子载荷结果对上市公司进行排名。
library(openxlsx)
library(nFactors) # 最佳因子数
library(psy) # 画因子载荷图,算基准:parallel()
# 1. read data from EXCEL file
dat <- read.xlsx('MicEcoData.xlsx', sheet='factor')
dat.fact <- dat[,-1] # 移除股票代码,10个变量
#x和数字(1-10)粘贴,sep=''表示中间没有空格
names(dat.fact) <- paste('x', 1:ncol(dat.fact), sep='')
# 2. do factor analysis
# (1) determine the optimal number of factors
ev <- eigen(cor(dat.fact)) # 特征值和特征向量
# 随机生成的特征值
ap <- parallel(subject=nrow(dat.fact),var=ncol(dat.fact), rep=100, cent=.05)
#x为要分析的特征值,aparallel为基准
nS <- nScree(x=ev$values, aparallel=ap$eigen$qevpea)
plotnScree(nS,main='因子分析图',xlab='因子',ylab='特征')
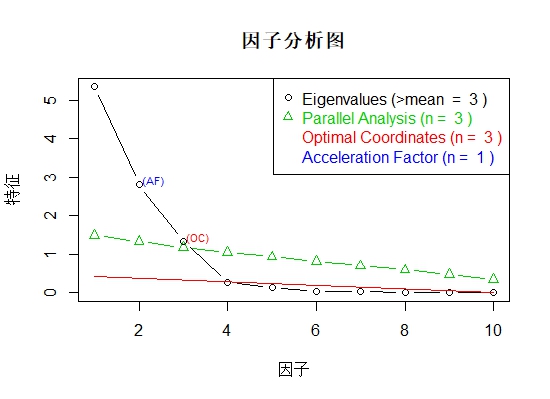
# (2) estimate
# 本题为了方便起见,选因子个数为2
factor.result <- factanal(x=dat.fact, factor=2, scores="regression")
#来源“psy”包,提供了因子数目和特征值大小的图形表示
scree.plot(dat.fact)
names(factor.result)
print(factor.result)
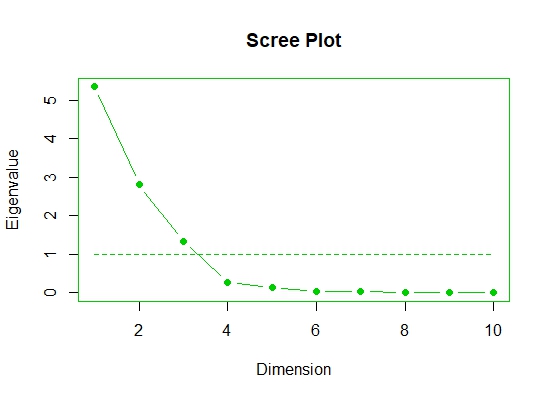
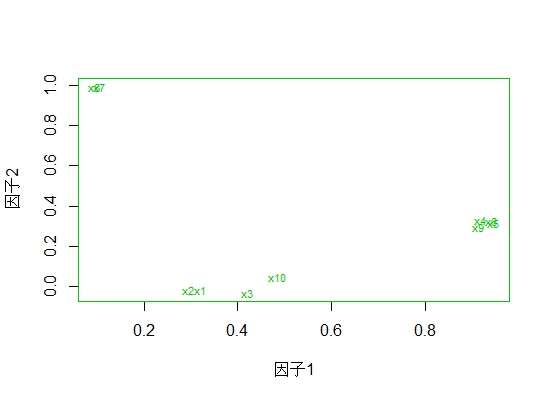
# 3. plot loadings
load <- factor.result$loadings[,1:2]
plot(load, type="n",xlab='因子1',ylab='因子2')
text(load, labels=names(dat.fact), cex=.7)
# 4. do comprehensive evaluation
# (1) calculate weights
# 求出各个因子的特征值,计算因子的权重
lambdas <- eigen(factor.result$correlation)$value
(w <- lambdas[1:2]/sum(lambdas[1:2]))
# (2) evaluate
# 计算因子得分并排序
score <- factor.result$scores
eva <- score %*% w
eva.result <- data.frame(firm=dat[,1], eva=eva)
eva.result[order(eva.result$eva, decreasing=TRUE),]
2.2 经济计量分析
经济计量模型包括二元选择模型(线性概率模型、变换概率模型)、计数数据模型(Poisson模型、负二项分布模型)、广义线性模型(分为:随机成分、系统成分、连接函数)。
1. 二元选择模型
案例:比较标准正态分布、逻辑分布、极值分布的函数。
# 1. generate x
x <- seq(-5, 5, length=100) #在(-5,5)之间生成100个等距离的数
# 2. compute CDFs
# (1) normal distribution
CDF.norm <- pnorm(q=x, mean=0, sd=1)
# (2) logitstic distribution
CDF.logit <- plogis(q=x, location=0, scale=1)
# (3) extreme distribution
pextreme <- function(x) 1-exp(-exp(x))
CDF.extr <- pextreme(x)
# 3. compare the results
par(mfrow=c(1,1))
plot(c(x,x,x), c(CDF.norm, CDF.logit, CDF.extr), type='n', xlab='x', ylab='CDF') #type='n'只画框框
lines(x, CDF.norm, lty=1, lwd=2)
lines(x, CDF.logit, lty=2, lwd=2)
lines(x, CDF.extr, lty=3, lwd=2)
abline(h=0.5, lty=20) #区分
abline(v=0, lty=20)
legend('topleft', legend=c('标准正态分布', '逻辑分布', '极值分布'), lty=c(1,2,3), lwd=c(2,2,2))
正态分布尾巴比较轻,logit处于中间。
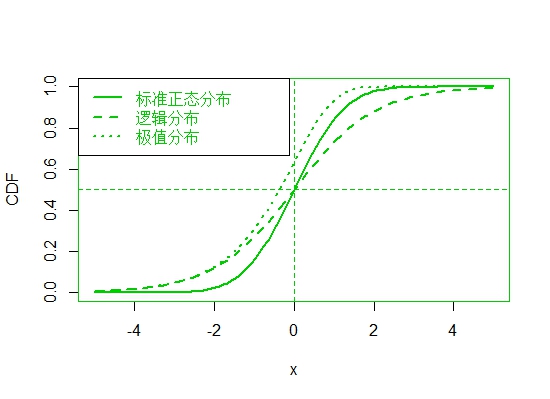
poisson模型[1]
read.table("PSQ.txt", header=T)=>psq
data = NULL
gender =NULL
#前四行为(0,1),接下来80个为(0,0),再接下来...
for(i in 1:dim(psq)[1])
{
if(psq[i,3]>0) {
for(j in 1:psq[i,3])
{data=rbind(data, c(psq[i,1],1))
gender=c(gender,psq[i,2])
}}
if(psq[i,4]>0) {
for(j in 1:psq[i,4])
{data=rbind(data, c(psq[i,1],0))
gender=c(gender,psq[i,2])
}}
}
#构建数据集,广义线性模型(更改连接函数)
dat1 = data.frame(y=data[,2], score=data[,1],gender=as.factor(gender))
lgfit=glm(y~score+gender, data=dat1, family=binomial(link="logit"))
pbfit=glm(y~score+gender, data=dat1, family=binomial(link="probit")
2.3 时间序列分析
时间序列模型分为:ARMA模型、VAR模型、脉冲响应和方差分解。
步骤:定阶-建模-描述
Q:已安装‘vars’包,无法使用函数VARselect(),错误类型:找不到‘vars’所需要的程辑包‘strucchange’,安装‘strucchange’后,提示错误类型:installation of package ‘strucchange’ had non-zero exit status?
A:“non-zero exit status”问题的可能原因有:通过尝试解压、下载依赖包[1]等均无法解决,最后将R升级到最新版[2],问题解决。
Q:连续画图报错,错误类型:invalid graphics state
A:解决办法,先dev.off(),再画第2张图。
案例:VAR模型,脉冲响应分析和方差分解。
# 1. load packages
library(vars)
library(quantmod)
# 2. setup data set
# (1) get data from yahoo website
getSymbols('^SSEC', from='2000-01-01', to='2013-12-30')
getSymbols('^HSI', from='2000-01-01', to='2013-12-30')
dim(SSEC)
names(SSEC)
detach(package:quantmod)
# (2) comput return of stocks
price.SSEC <- SSEC$SSEC.Adjusted
price.HSI <- HSI$HSI.Adjusted
r.SSEC <- 100*diff(log(price.SSEC)) #对数收益率
r.HSI <- 100*diff(log(price.HSI))
r.data <- merge(r.SSEC, r.HSI, join='inner') #按日期合并
#删除NA值:is.na()判断有没有NA,1表示对行操作,any表示任何1个没有就删去
R <- r.data[!apply(is.na(r.data), 1, any), ]
colnames(R) <- c('SSEC', 'HSI')
# 3. select optimal lags #定阶
VARselect(R, lag.max=8, type='both') #both:截距项和趋势项都包括
# 4. estimate VAR(1) model
VAR.model <- VAR(R, p=1, type='both')
VAR.model
summary(VAR.model)
plot(VAR.model, names='SSEC')
plot(VAR.model, names='HSI')

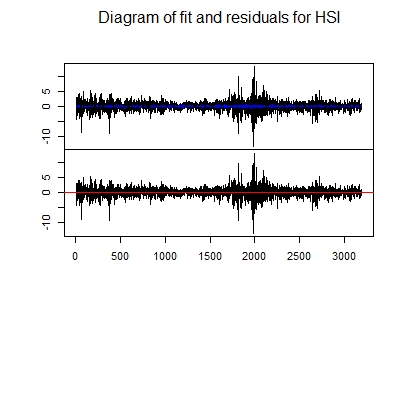
# 5. comput IRF and FEVD #计算脉冲响应和方差分解
# (1) estimate VECM #向量误差修正模型
#ca.jo():Johansen Procedure for VAR,trace代表迹,trend代表趋势变量,k代表滞后阶数
vecm <- ca.jo(R, type='trace', ecdet='trend', K=3, spec='transitory')
LR <- matrix(NA, nrow=2, ncol=2)
SR <- matrix(NA, nrow=2, ncol=2)
LR[1,2] <- 0
SR[2,1] <- 0
#SVEC:Estimates an SVEC by utilising a scoring algorithm.
svec <-SVEC(vecm, r=1, LR=LR, SR=SR, lrtest=FALSE, boot=TRUE, runs=100)
summary(svec)
# (2) comput IRF
# 脉冲响应模型irf()
svec.irf <- irf(svec, response='SSEC', n.ahead=60, boot=TRUE)
par(mfrow=c(1,2))
plot(svec.irf, all.terms=TRUE, page=1)
plot(svec.irf, select=2)
par(mfrow=c(1,1))
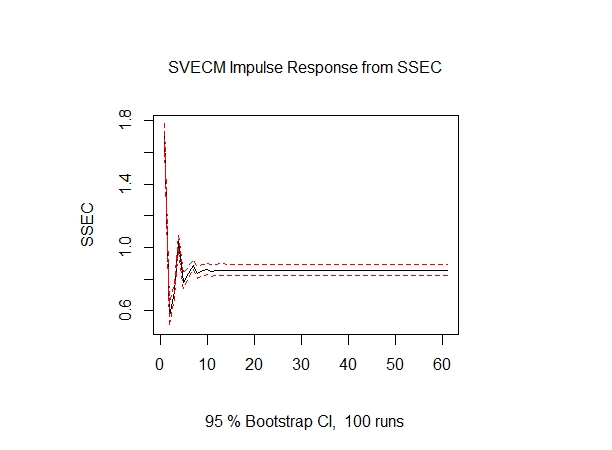
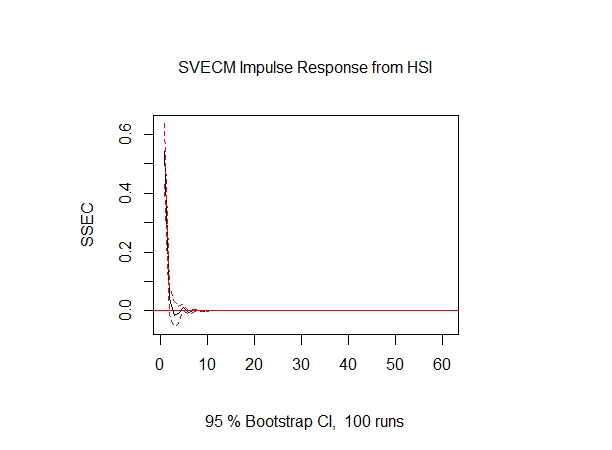
# (3) comput FEVD
# 方差分解fevd():Forecast Error Variance Decomposition
fevd <- fevd(svec, n.ahead=20)
fevd.SSEC <- fevd$SSEC
rownames(fevd.SSEC) <- 1:20
fevd.HSI <- fevd$HSI
rownames(fevd.HSI) <- 1:20
par(mfrow=c(1,2))
barplot(t(fevd.SSEC), legend.text=c('SSEC','HSI'), xlab='时期', xlim=c(0,28))
barplot(t(fevd.HSI), legend.text=c('SSEC','HSI'), xlab='时期', xlim=c(0,28))
par(mfrow=c(1,1))
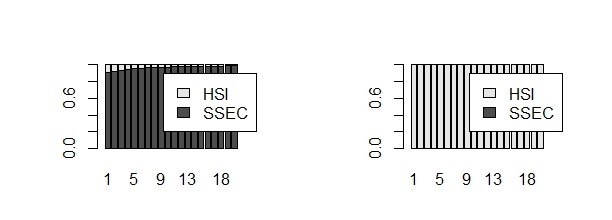
2.4 优化理论与方法
优化理论与方法包括线性规划、目标规划和非线性规划。
########################################################
# Contents:
# 1. load packages
# 2. setup data set
# 3. select optimal lags
# 4. estimate VAR(1) model
# 5. comput IRF and FEVD
#########################################################
rm(list = ls())
# (2) load packages
source('Sub-02.R') # our own functions
# 1. solve a nonlinear equation
# (1) 定义损失函数
f <- function(r, p, Cs){
n <- length(Cs)
tt <- 1:n
loss <- p - sum(Cs/((1+r)^tt))
loss
}
# (2) find the solution
Cs <- c(2000, 2000, 2500, 4000)
P <- 7704
uniroot(f, c(0,1), p=P, Cs=Cs) # 重要:解方程
# 2. optimize a nonlinear function
# (1) optimize
g <- function(r, p, Cs) {f(r, p, Cs)^2} # define g function: g=f^2
optimize(g, c(0,1), p=P, Cs=Cs) # optimize g function
# (2) compare tow approaches
rs <- seq(0, 1, length=100)
fval <- gval <- numeric(length(rs))
for (i in seq_along(rs)){
fval[i] <- f(r=rs[i], p=P, Cs=Cs)
gval[i] <- g(r=rs[i], p=P, Cs=Cs)
}
dev.off()
par(mfrow=c(2,1))
plot(rs, fval, type='l', xlab='r', ylab='f')
abline(h=0, lty=2)
plot(rs, gval, type='l', xlab='r', ylab='g')
abline(h=0, lty=2)
par(mfrow=c(1,1))
# 3. compare nonlinear optimize and L1 statistics
# (1) do L1 statistics
set.seed(1)
y <- rnorm(n=10, mean=0, sd=1)
xi <- seq(min(y), max(y), length=100)
TAU <- 0.5
(R <- objFun(tau=TAU, y, xi, plot.it=TRUE)) # calculate objective function with different xi's
(xi_est <- xi[which.min(R)]) # estimate xi which minimize objective function
(y_qua <- quantile(y, prob=TAU)) # quantile of observations which is the same as minimization point
# (2) optimize the nonlinear objective function
optimize(objFun, c(-2,2), tau=TAU, y=y, plot.it=FALSE) # optimize an objective function of L1 statistics
# 4. compare quadratic programming and OLS
# (1) generate data
beta <- c(5, 2)
sigma <- 1
n <- 100
set.seed(1)
eps <- rnorm(n, mean=0, sd=1)
x <- runif(n, min=-10, max=10)
y <- beta[1] + beta[2]*x + sigma*eps
# (2) do linear regression by OLS
model.lm <- lm(y~x)
(coef.OLS <- coef(model.lm))
# (3) solve quadratic programming by optim function
lossQuad <- function(betaHat, x, y){
sum((y-betaHat[1]-betaHat[2]*x)^2)
}
optim(par=coef.OLS, fn=lossQuad, y=y, x=x) # optimize a loss function
#没有限制条件的优化方法
fun<- function(x)
{x^2}
ucminf(1,fun)
3.1 人工智能方法
1. 神经网络与支持向量机
案例:采用BP神经网络,多层感知机神经网络,径向量机神经网络方法,分类ST和非ST股票。
library(neuralnet) # for neural network
library(monmlp) # for MLP:多层感知神经网络
library(RSNNS) # for RBF:径向基神经网络
library(e1071) # for SVM
library(rminer) # for SVM
library(openxlsx) # for excel data
library(ROCR) # for ROCR curve
library(DAAG) # 计算混淆矩阵
# 1. setup dataset
# (1) read data from EXCEL file
dat <- read.xlsx('StockData.xlsx', sheet='Sheet1')
# (2) name data
names(dat) <- c(paste('x',1:7,sep=''), 'y')
summary(as.factor(dat[,'y']))
y=dat$y
# 2. make BP neural network # BP神经网络
# (1) estimate model
# 误差限限制为0.0001
set.seed(12345) #设置随机数,防止抽样不同结果不同
model.BP <- neuralnet(y~x1+x2+x3+x4+x5+x6+x7, dat, hidden=10, threshold=0.0001)
# (2) plot BPNN
plot(model.BP, rep="best")
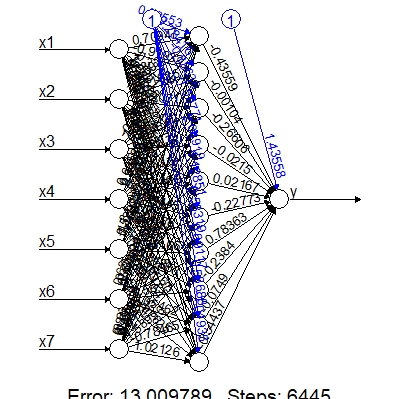

# (3) do classification
class.BP <- round(compute(model.BP, dat[,-8])$net.result)
DAAG::confusion(class.BP, dat[,8]) #混淆矩阵
plot(performance(prediction(class.BP, y), "tpr","fpr")) # plot ROC
performance(prediction(class.BP, y), "auc")@y.values[[1]] # accuracy
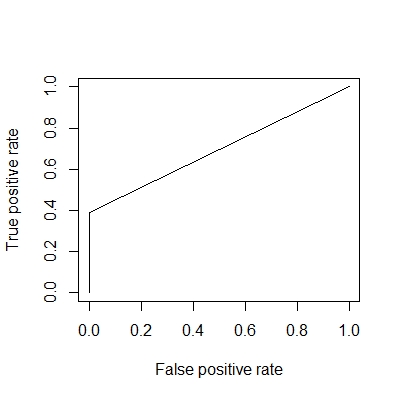
# 3. make MLP neural network
# 多层感知机神经网络,设置隐藏节点数10,使用bagging方法提高模型预测能力。
# (1) estimate model
set.seed(12345)
x <- as.matrix(dat[,1:7])
y <- as.matrix(dat[,8])
model.MLP <- monmlp.fit(x=x, y=y, hidden1=10, n.ensemble=15, monotone=1, bag=TRUE) #单调,用bagging办法投票
y.hat <- monmlp.predict(x=x, weights=model.MLP)
# (2) show results
tmp=y.hat
tmp[y.hat<0.5]=0
tmp[y.hat>0.5]=1
#DAAG::confusion(tmp, y) # calculate confusion matrix
plot(performance(prediction(y.hat, y), "tpr","fpr")) # plot ROC
performance(prediction(y.hat, y), "auc")@y.values[[1]] # accuracy
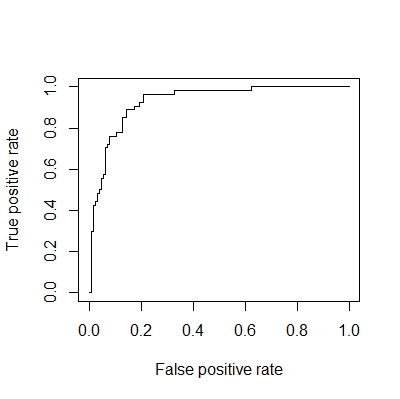
# 4. make RBF neural network:径向基
# (1) estimate model
set.seed(12345)
x1=apply(x,2,function(z){(z-mean(z))/sd(z)}) #径向基需要做标准化
inputs <- x1
colnames(inputs) <- NULL
outputs <- normalizeData(y, "0_1")
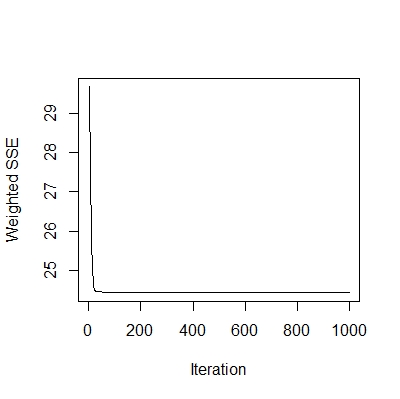
model.RBF <- rbf(inputs, outputs, size=10, maxit=1000)
# (2) show results
plotIterativeError(model.RBF) # show iterations
y.hat <- predict(model.RBF, inputs)
DAAG::confusion(round(y.hat), y) # calculate confusion matrix
plot(performance(prediction(y.hat, y), "tpr","fpr")) # plot ROC
performance(prediction(y.hat, y), "auc")@y.values[[1]] # accuracy
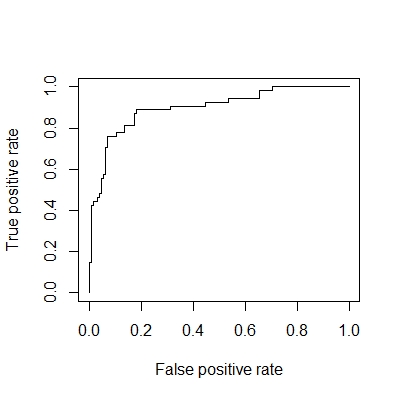

# 5. make SVM model
# (1) set index for K-fold CV
n <- nrow(dat) # sample size
ind.samp <- 1:n # index of sample
K <- 10 # K-fold
ind.K <- rep(1:K, ceiling(n/K))[1:n] # keep the same length as sample size
set.seed(12345)
ind.CV <- sample(ind.K, n) # 打乱顺序
# (2) define accuracy function
Acurr <- function(y, yfit) {mean(y==yfit)}
# (3) estimate model and calculate accuracy of classification
Acurr.in <- Acurr.out <- numeric(K)
SVM.model <- list() # 列表,元素个数待定
for (k in 1:K){
ind.i <- ind.samp[ind.CV==k]
SVM.model[[k]] <- fit(y~., data=dat[-ind.i,], model='svm', task='class')
y.train <- predict(SVM.model[[k]], dat[-ind.i,])
y.test <- predict(SVM.model[[k]], dat[ind.i,])
Acurr.in[k] <- Acurr(y=dat[-ind.i,'y'], yfit=y.train)
Acurr.out[k] <- Acurr(y=dat[ind.i,'y'], yfit=y.test)
}
# (4) evaluation
Acurr <- round(cbind(Acurr.in, Acurr.out), digits=4)
rownames(Acurr) <- paste('k=', 1:K, sep='')
print(Acurr)
boxplot(Acurr)
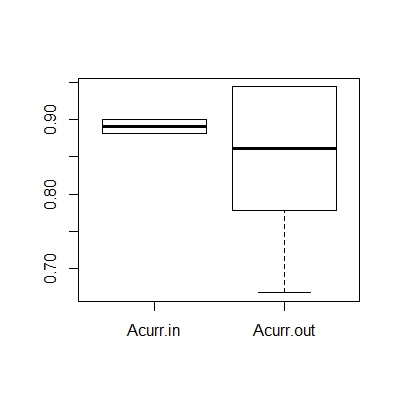
3.2 高维数据分析
最小二乘法的局限性(非满秩不可逆)、岭回归、Lasso回归。
1. LASSO回归
用交叉验证进行Lasso变量选择(将多少个回归系数约束为0),定义广义交叉验证类的统计量GCV。
案例:检验Lasso变量选择结果
# (2) load packages
library(lars) # LASSO 回归
library(ridge) # 岭回归
library(mvtnorm) # 多元正态分布
# 1. generate data
N <- 30
B <- 50
rho <- 0.5 #解释变量之间的相关系数
sigma <- 3
betas <- c(3.5,1,0,2,0,0) #有3个为0
set.seed(12345)
I <- matrix(rep(1:length(betas), times=length(betas)), byrow=FALSE, nrow=length(betas))
J <- matrix(rep(1:length(betas), times=length(betas)), byrow=TRUE, nrow=length(betas))
(corr <- rho^abs(I-J))
eps <- rnorm(N, mean=0, sd=1)
X <- rmvnorm(n=N, mean=rep(0, length(betas)), sigma=corr) #生成多元正态
cor(X)
Y <- X %*% betas + sigma * eps
dat <- data.frame(Y, X)
# 2. do regression for one simulation
# (1) do OLS regression
model.ols <- lm(Y~.-1, data=dat) # 没有截距项
summary(model.ols)
coef.ols <- coef(model.ols)
coef.ols[coef.ols!=0] # 没有做变量选择,所以每个变量都被估计为非零
# (2) do ridge regression # 有偏估计
model.rid <- linearRidge(Y~.-1, data=dat)
summary(model.rid)
coef.rid <- coef(model.rid)
coef.rid[coef.rid!=0] # 也没有做变量选择
# (3) do lasso regression
model.lasso <- lars(X, Y, type='lasso')
plot(model.lasso) # 参数估计的路径图
summary(model.lasso)
set.seed(12345)
CV.lasso <- cv.lars(X, Y, K=10) # 做交叉验证
# 最小值的位置在哪,即λ,对应的参数估计
(best <- CV.lasso$index[which.min(CV.lasso$cv)])
(coef.lasso <- coef.lars(model.lasso, mode='fraction', s=best))
names(coef.lasso) <- colnames(dat)[-1]
coef.lasso[coef.lasso!=0]
读图:下图一为参数估计的路径图,从右往左看,最右端有6个变量(非零),往左看λ逐渐变大。下图二最小值的位置为λ。
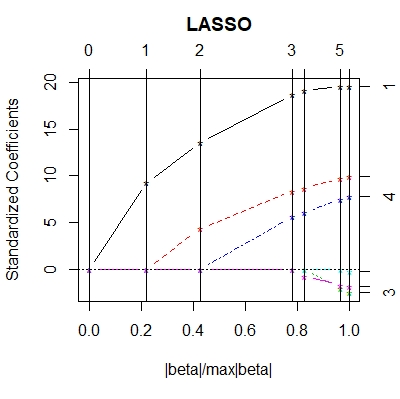
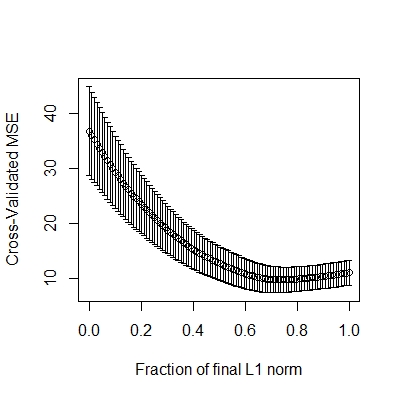
# 3. do regression for 50 simulations——一般模拟做500次
# (1) define Monte Carlo function
MonteCarlo <- function(N, betas, type='lasso'){
# (1) generate data
I <- matrix(rep(1:length(betas), times=length(betas)), byrow=FALSE, nrow=length(betas))
J <- matrix(rep(1:length(betas), times=length(betas)), byrow=TRUE, nrow=length(betas))
corr <- rho^abs(I-J)
eps <- rnorm(N, mean=0, sd=1)
X <- rmvnorm(n=N, mean=rep(0, length(betas)), sigma=corr)
Y <- X %*% betas + sigma * eps
dat <- data.frame(Y, X)
# (2) do OLS regression
model.ols <- lm(Y~.-1, data=dat)
coef.ols <- coef(model.ols)
# (3) do ridge regression
model.rid <- linearRidge(Y~.-1, data=dat)
coef.rid <- coef(model.rid)
# (4) do lasso regression
model.lasso <- lars(X, Y, type=type)
CV.lasso <- cv.lars(X, Y, K=10, plot.it=FALSE)
best <- CV.lasso$index[which.min(CV.lasso$cv)]
coef.lasso <- coef.lars(model.lasso, mode='fraction', s=best)
names(coef.lasso) <- colnames(dat)[-1]
# (5) output
ans <- list(coef.ols=coef.ols, coef.rid=coef.rid, coef.lasso=coef.lasso)
ans
}
# (2) repeat simulation 50 times 生成一个大矩阵
coef.ols <- coef.rid <- coef.lasso <- matrix(NA, nrow=length(betas), ncol=B)
for (b in 1:B){
coef.MC <- MonteCarlo(N, betas, type='lasso')
coef.ols[,b] <- coef.MC$coef.ols
coef.rid[,b] <- coef.MC$coef.rid
coef.lasso[,b] <- coef.MC$coef.lasso
}
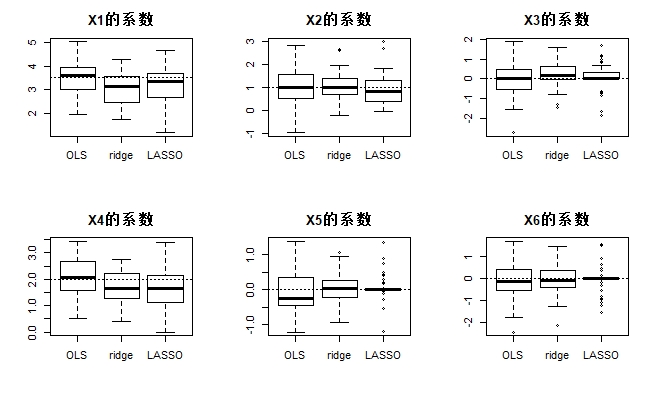
par(mfrow=c(2,3),mar=c(5,4,3,2))
coef.methods <- matrix(NA, nrow=B, ncol=3)
for (i in 1:length(betas)){
coef.methods <- cbind(coef.ols[i,], coef.rid[i,], coef.lasso[i,])
colnames(coef.methods) <- c('OLS', 'ridge', 'LASSO')
boxplot(coef.methods, main=paste('X', i, '的系数', sep=''))
abline(h=betas[i], lty=3)
}
参考资料:
[1]CRAN(strucchange): https://cran.r-project.org/web/packages/strucchange/index.html
[2]下载R:https://mirrors.tuna.tsinghua.edu.cn/CRAN/bin/















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









