






目录
结构方程模型(Structural Equation Model,简称SEM)
Assumption 1. Stable Unit Treatment Value Assumption (SUTVA).
Densely Connected Convolutional Networks
FractalNet: Ultra-Deep Neural Networks without Residuals
NPTC-net: Narrow-Band Parallel Transport Convolutional Neural Network on Point Clouds
PolyNet: A Pursuit of Structural Diversity in Very Deep Networks
A Proposal on Machine Learning via Dynamical Systems
Deep Residual Learning for Image Recognition
i-REVNET: DEEP INVERTIBLE NETWORK
简单介绍
现有分类算法多基于关联关系:不可解释性(黑盒)、准确率低(非独立同分布)
吸烟、黄牙、肺癌强相关。因果关系在深度学习的基础上对统计数据进行智能处理,判断特定变量(如吸烟)是一种疾病发生的原因(而清洁牙齿与降低肺癌发生风险无关)
三种模型
Potential Outcomes Framework
potential outcomes:The quantities y(1) and y(0)
用1/0表示行为,y是行为带来的结果
Counterfactual:当一个行为发生,另一类行为的y马上成为反事实。
the Science Table:
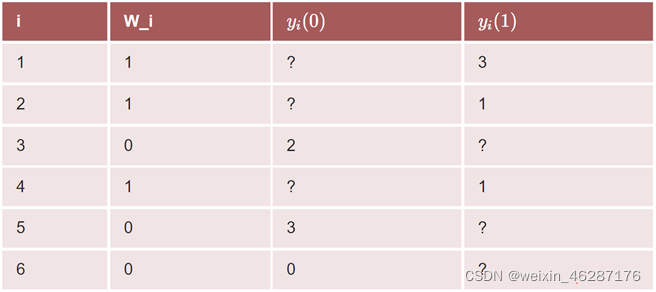
Causal Estimands:a function of the Science
ITE:
![]()
ATE:
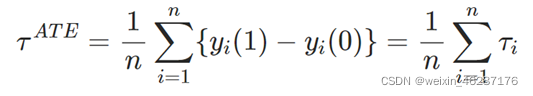
DiM:
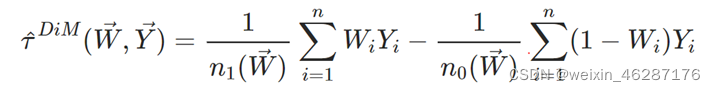
(如果w随机分布,可以认为τ_DiM=τ_ATE)
RCM的问题:如果我们增加变量,模型的体积、需要的训练数据、训练时间都将以指数级增长。
贝叶斯网络
有向无环图:不能表示因果,只能表示相关
贝叶斯网络中,A→B未必等同于A导致B。
减少条件概率表的规模
结构方程模型(Structural Equation Model,简称SEM)
内生变量:存在父节点的节点,即至少有一条边指向该节点;
外生变量:独立于其他变量,不存在父节点的节点。
![]()
在SCM里,单向箭头表达直接的因果关系,用双向箭头表明两个外生变量之间可能存在未知的混杂因素。
介入:
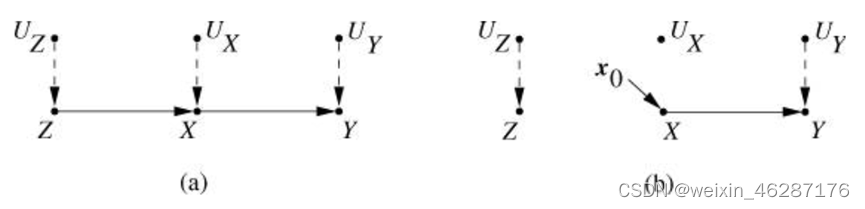
一个SCM具有马尔可夫性质,当且仅当这个SCM不包含任何的有向环,且所有外生变量均相互独立。
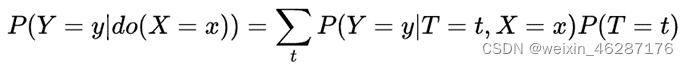
后门准则:
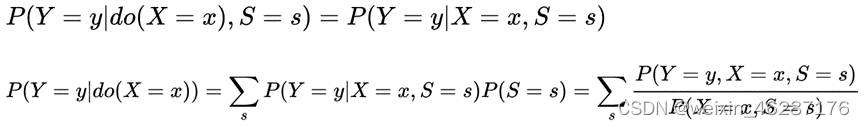
用SCM表示RCM:外生变量U代表误差项个体差异
![]()
三个假设
Assumption 1. Stable Unit Treatment Value Assumption (SUTVA).
The potential outcomes for any unit do not vary with the treatment assigned to other units, and, for each unit, there are no different forms or versions of each treatment level, which lead to different potential outcomes.
变量组实体受到变量影响效果一致性
Assumption 2. Stable Unit Treatment Value Assumption (SUTVA). The potential outcomes for any unit do not vary with the treatment assigned to other units, and, for each unit, there are no different forms or versions of each treatment level, which lead to different potential outcomes.
Assumption 2. Ignorability.
Given the background variable, X, treatment assignment W is independent to the potential outcomes, i.e., W ⊥⊥ Y(W = 0),Y(W = 1)|X.
相同的背景(background variables)不管treatment一不一样,potential outcome相同
相同的背景(background variables)相同的potential outcome,treatment distribution相同
Assumption 3. Positivity.
For any value of X, treatment assignment is not deterministic: P(W = w|X = x) > 0, ∀w and x.
主流方法
1.样本重加权
Re-weighting Methods:By assigning appropriate weight to each unit in the observational data, a pseudo-population can be created on which the distributions of the treated group and control group are similar.
样本重加权是一种解决选择偏差的高效方法,通过为每个单元分配合适的权重,创建出一个干预组与对照组分布类似的拟群。
a.基于倾向评分的样本重加权
![]() (样本权重)
(样本权重)
b.混杂因子平衡
区分混杂因子与调整变量的不同影响,同时消除无关变量。(z是调整变量)

2.stratification method
Ideally, in each subgroup, the treated group and the control group are similar under certain measurements over the covariates, therefore, the units in the same subgroup can be viewed as sampled from the data under randomized controlled trials.
创建区组的常用方法:相等频率法(equal frequency):
每个亚组(区组)中的协变量具有相同的出现概率
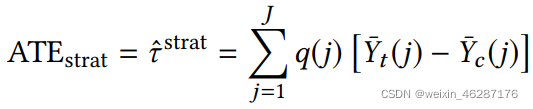
3.匹配方法
匹配即对于实验组的每一个样本,在对照组找到与之匹配(即二者相似)的一个样本,组成一个样本对,最后基于所有的样本对进行建模,以达到控制混淆的目的。这里的匹配方法如果用的是倾向性得PS,那就是PSM的概念。
一种 RCT 的模仿: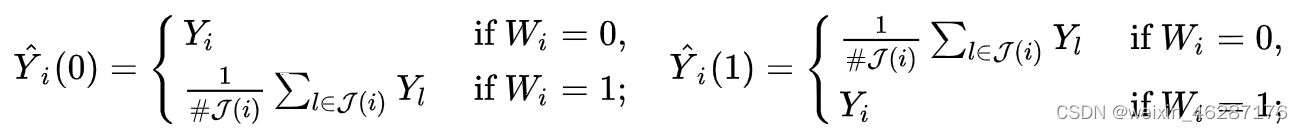
4.基于树的方法
分类回归树:根据众数作为样本类别/均值作为回归预测值。
基于 CART 提出了一种数据驱动的方法,根据干预效果的差异,将数据划分为多个亚组(子空间)->能够获得有效的干预效果置信空间(无需稀疏假设)
5.表征学习
特征学习或表征学习是学习一个特征的技术的集合:将原始数据转换成为能够被机器学习来有效开发的一种形式。它避免了手动提取特征的麻烦,允许计算机学习使用特征的同时,也学习如何提取特征:学习如何学习。
通过学习事实数据来预测反事实结果,其将因果推断问题转变为了一个领域适应问题。
学习到的表征需要在以下三类目标上进行权衡:
(1)事实表征的低误差预测;
(2)反事实结果的低误差预测(考虑相关的事实结果);
(3)干预组与对照组分布之间的距离。
找出一个表征与假设以最小化:
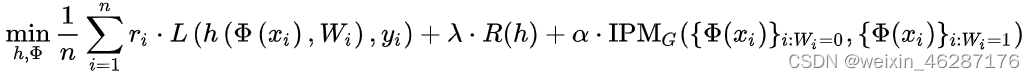
6.多任务学习方法
dropout 正则化机制:通过依赖于相关联倾向评分的 dropout 概率为每个训练样本进行网络结构优化(随机去除单元),如果样本的特征在干预组与对照的特征空间中重叠较低,则其对应的 dropout 概率会偏高。
7.元学习方法
1) Control the confounders, i.e., eliminate the spurious correlation between the confounder and the outcome;
2) Give an accurate expression of the CATE estimation [87].
估计条件平均结果 ![]() ,该步骤中学习得到的预测模型为基学习器(base learner)
,该步骤中学习得到的预测模型为基学习器(base learner)
基于第一步中结果的差异推导 CATE 估计器
发展
因果推理的三个阶段:
- 关联:“黑盒”
- 干预:干预事件A,观测B是否随之改变
- 反事实:对于已经发生的事情做假定(分布不一致、领域迁移)
(我的理解是,特定的因和果之间的联系是符合一定关系的。反事实只是没有发生,调整了因的参数,但算出来的果也要是符合这个模型的,所有可以通过与事实分布一致来做。
Y(1)-Y(0).前者是事实结果,后者是反事实结果。或者说前者是treated,后者是control。
Causal feature learning
非监督机器学习、从低维数据提取高维因果关系、“可解释人工智能”,
一般的因果关系的提取过程:通过直觉、先验知识指定假设->设计实验进行验证->证实假设。CFL旨在自动化这一过程、减少先入为主的因果关系偏见的影响。
宏变量:微变量空间上的聚合关系、抽象化微观细节
(宏变量间因果关系的好坏受聚合程度影响)
稳定学习
性能驱动:效率优先
->
人工智能深水区:风险区
Human in the loop:人机协同、人在决策过程中、痛点-沟通
AI算法:独立同分布-稳定性 差
三种关联:
Causation:summer-ice cream sales
Confounding:confounding factor:age n ->smoke & weight increase(虚假关联)
Sample selection bias(样本选择偏差):狗的识别(背景)

通过样本重加权,使得所有变量相互独立(降低输入变量之间的贡献性),这时可以认为:correlation=causality
所有变量相互独立->对causal noncausal做聚类,类间相互独立。
经典论文
Johansson, Learning Representations for Counterfactual Inference
将反事实问题定义为领域适应问题
最小化discrepancy distance指的是在表示空间内,事实分布和反事实分布的差异
Generative Adversarial Nets of Indeividualized Treatment Effects(GANITE)
生成对抗网络:GAN中午名是生成对抗网络,是一种无监督学习。由两部分组成:生成器(generator) and判别器(discriminator)。生成网络从潜在空间(latent space)中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。判别网络的输入则为真实样本或生成网络的输出,其目的是将生成网络的输出从真实样本中尽可能分辨出来。而生成网络则要尽可能地欺骗判别网络。两个网络相互对抗、不断调整参数,最终目的是使判别网络无法判断生成网络的输出结果是否真实。
反思:利用因果这种思想方法去提高神经网络的分类预测能力。
第一步:特征提取(问题:confounder->代理(会对因果都造成影响的因)
方法:vae构建proxy、深度神经网络提取
第二步:反事实预测:神经网络的拟合、gan自动生成判别(这个过程筛因?)
要是从提取的特征里面得到因果的信息(用正确的因去得到误差小的反事实分布。
PDE与因果推断
欧拉差分
差分方法的设计思想是, 将寻求微分方程的解 y(x)的分析问题化归为 计算离散值 y_n+1 的代数问题,而“步进式”则进一步将计算模型化归为仅含一个 变元 y_n+1的代数方程——差分格式。
离散化:消除导数项y’。由于差商是是微分的近似计算,实现离散化的一种直截了当的途径是用差商替代导数。
![]()
改进的 Euler格式:
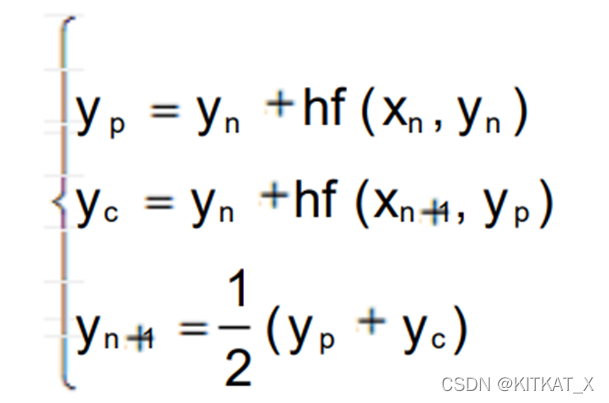
数据->高维数据中的点云->落在低维流形上->在低维流形定义PDE->求解PDE
流形:
高维数据维度冗余
流形是d维空间在m维空间被扭曲之后的结果(m>d)
神经网络特征->低维空间维数
PDE-Net
1.微分算子对应的卷积核
2.内嵌在网络中的非线性函数
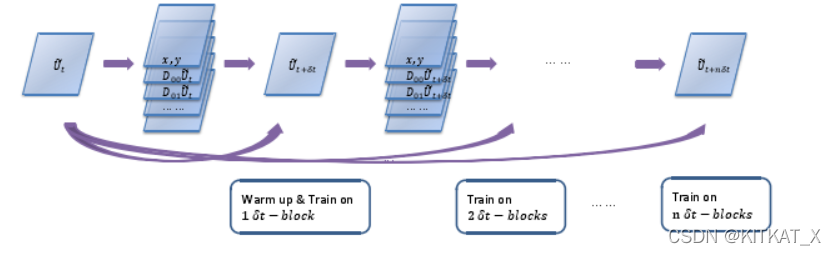
PDE时间格式演进:
![]()
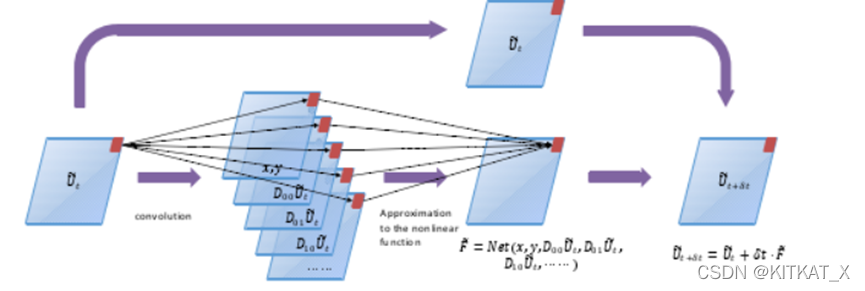
IMAGE RESTORATION: TOTAL VARIATION, WAVELET FRAMES, AND BEYOND JIAN-FENG CAI, BIN DONG, STANLEY OSHER, AND ZUOWEI SHEN:这篇文章建立了卷积核微分阶和微分算子的阶之间的关系。
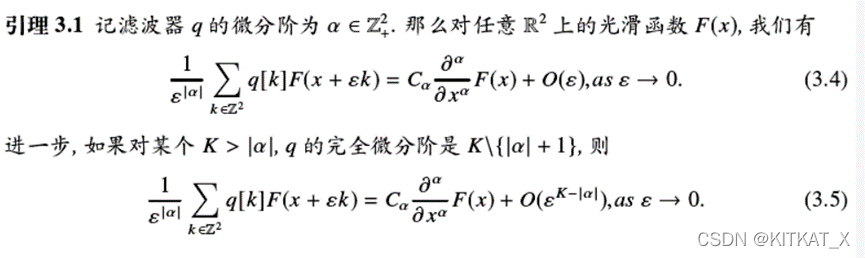
两个函数卷积之后的导数等于一函数的导数*一函数的卷积
一个a阶的微分算子可以被一个微分阶为a的滤波器逼近
卷积核微分阶:

卷积核的矩:

以下将证明:将滤波器q应用于光滑函数f上时可以得到f各阶导数的线性组合。而各阶导的系数为滤波器的矩。即限制滤波器的矩,能限定滤波器和逼近微分的精度。
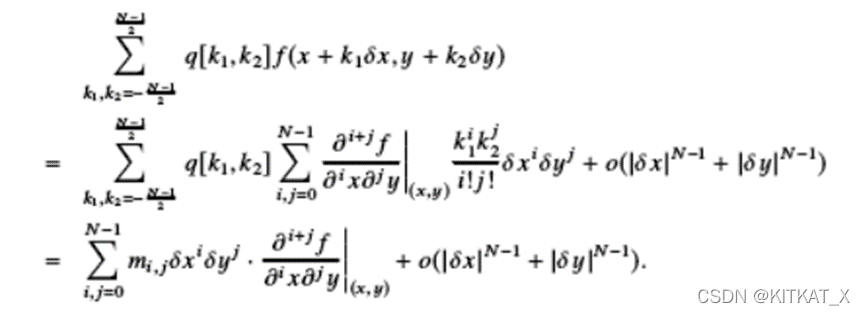
且卷积核q到矩M的映射是可逆线性的。
损失函数:观测值和PDE-Net训练值的差值的范数。
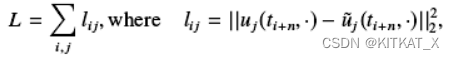
PDE-Net是一个RNN,逐渐增加训练block。
Warmup:固定卷积核,专注训练子网络参数。
子网络:Network in Network(网络中内嵌微型网络)。
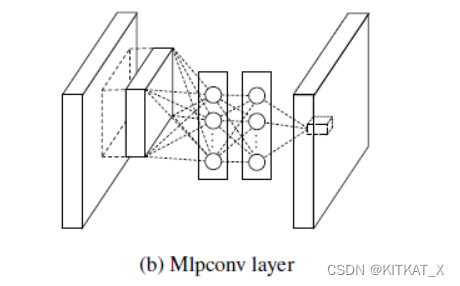
MLPConv在常规卷积(感受野大于1的)后接若干1x1卷积,每个特征图视为一个神经元,特征图通过1x1卷积就类似多个神经元线性组合
所有参数:
- 卷积核的矩->生成卷积核
- 逼近f的子网络参数
- 超参数(卷积核大小、Net结构等)
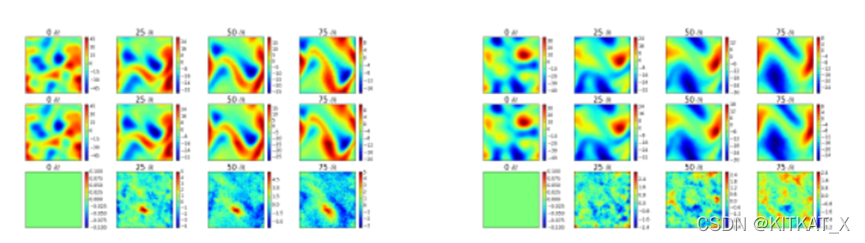
用对流扩散方程进行实验:
第一行是无噪声样本,第二行是用PDE-Net训练的预测值,第三行为二者差值。
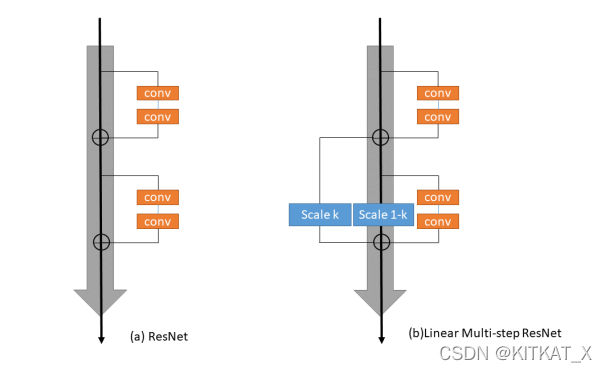
Beyond Finite Layer Neural Networks: Bridging Deep Architectures and Numerical Differential Equations
解释了Res-Net等网络与微分方程的关系。并基于此借鉴线性多步法的思想建立 LM-architecture。证明了其在同样参数的条件下能取得更好效果。
Densely Connected Convolutional Networks
每一层都利用了前面所有层训练的特征,每一层的输出都作为之后所有层的输入参数。

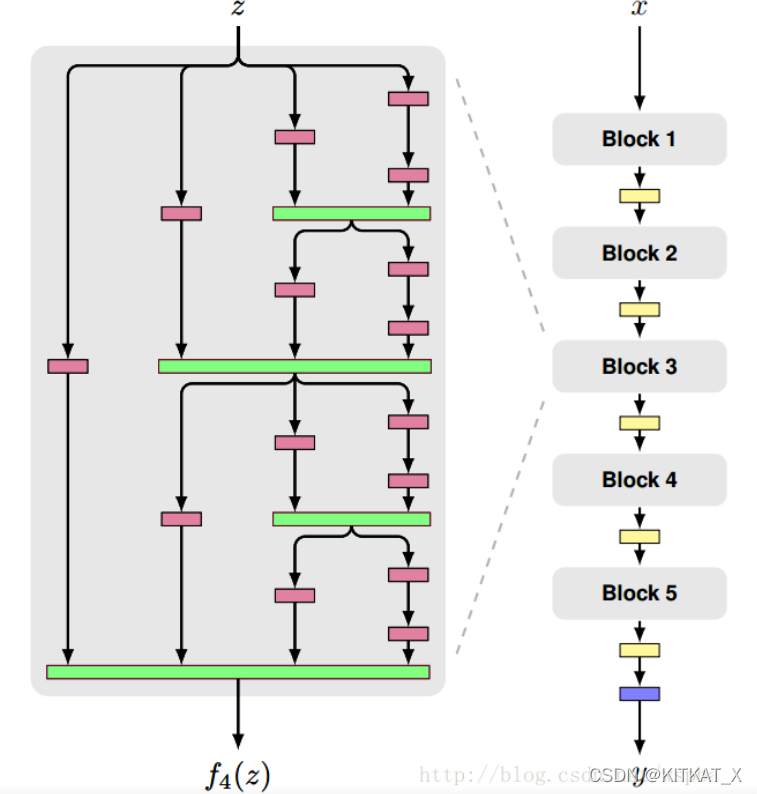
FractalNet: Ultra-Deep Neural Networks without Residuals
每一个Fractal的模块,实际上就是由多个浅层和深层的联合而成,层的深度成2的指数型增长。不同深度的输出进行联合时采用的不是ResNet中使用的加法,而是一个求均值的操作。
DropPath
让路径随机失活。也就是说在多个不同深度的层进行联合时,模型会以一个比例随机的让某些路径的输入关闭,但最少保证有一个输入。
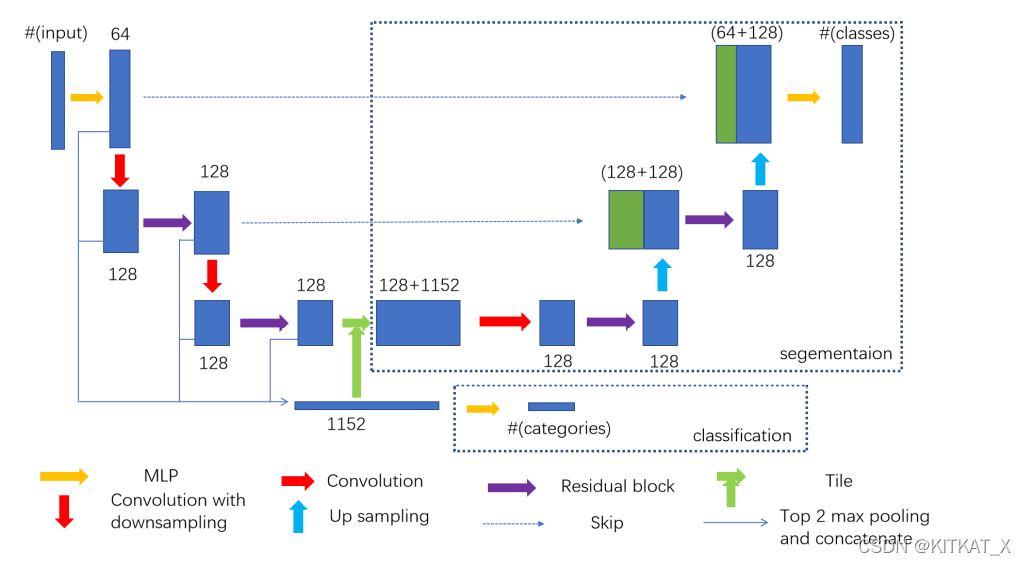
NPTC-net: Narrow-Band Parallel Transport Convolutional Neural Network on Point Clouds
欧几里得空间
一类特殊的向量空间。对通常3维空间V3中的向量可以讨论长度、夹角等几何性质。
The left half of the NPTC-net is the encoder part of the network for feature extraction. For classification, features at the bottom of the network are directly attached to a classification network; while for segmentation, features are decoded using the right half of the NPTC-net (decoder part of the network) to output the segmentation map
PolyNet: A Pursuit of Structural Diversity in Very Deep Networks
Inception结构:使用一个密集成分来近似或者代替最优的局部稀疏结构
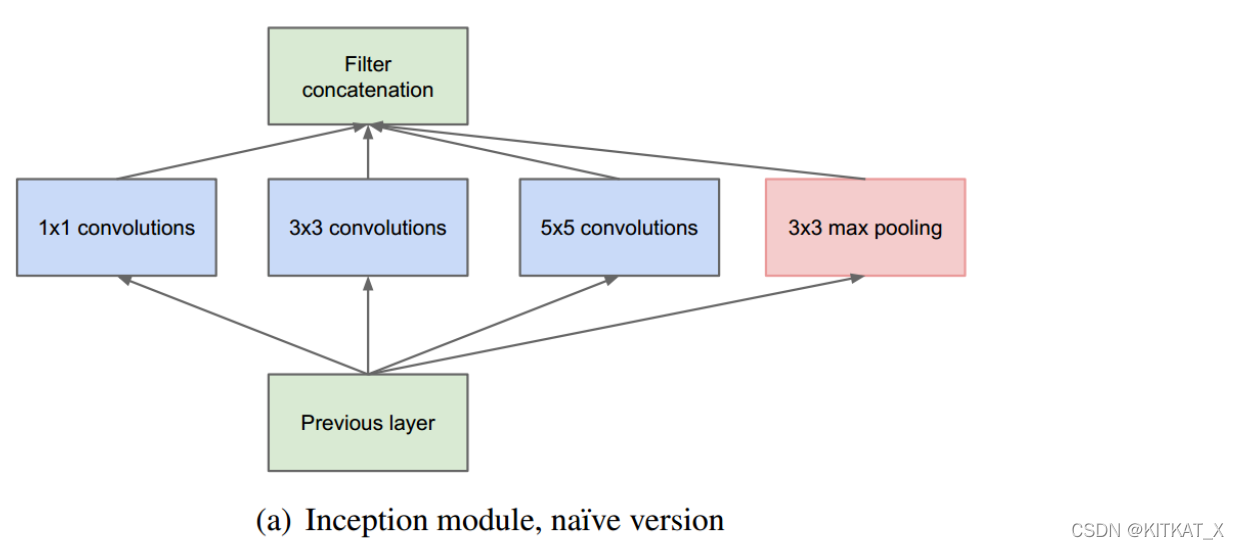
a)采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
b)之所以卷积核大小采用1、3和5,主要是为了方便对齐;
c)文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了;
d)网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
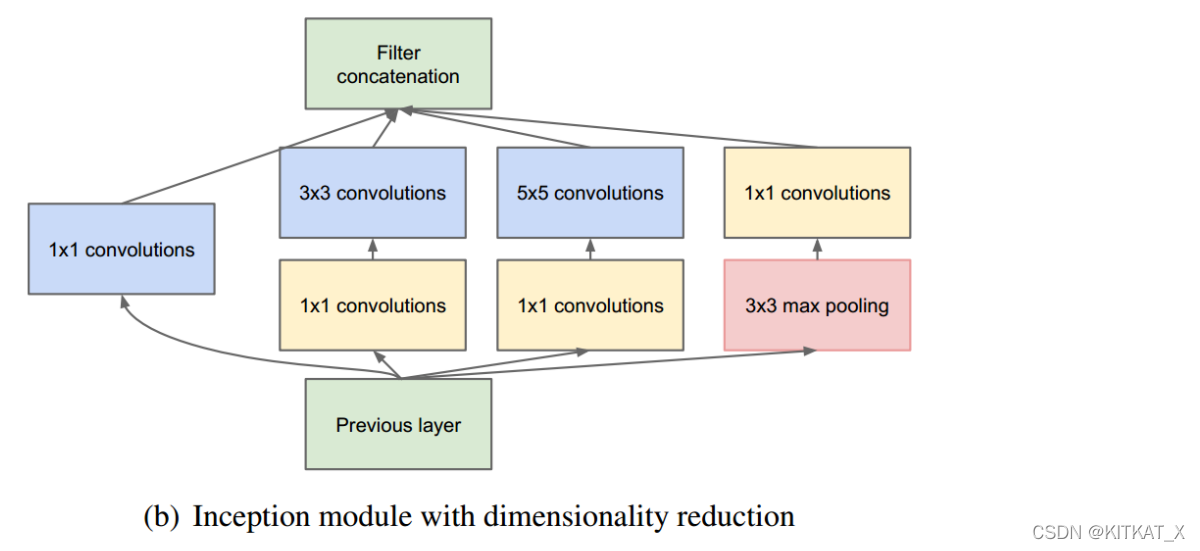
借鉴NIN,采用1x1卷积核来进行降维,同时,引入更多的非线性,提高泛化能力,因为卷积后要经过ReLU激活函数。
PolyInception 模块是 Inception 单元的多项式组合,它会以并行或串行的方式集成多条计算路径。
A Proposal on Machine Learning via Dynamical Systems
A dynamical system is a rule for time evolution on a state space.
A dynamical system is a state space S, a set of times T and a rule R for evolution, R:S×T→S that gives the consequent(s) to a state s∈S. A dynamical system can be considered to be a model describing the temporal evolution of a system.
在这篇Proposal中,鄂老师表示深度神经网络可以理解为离散的动力学系统。离散的动力学系统很难分析,但连续的动力学系统在数学上更易于分析,因此它可作为深度神经网络的数学基础。
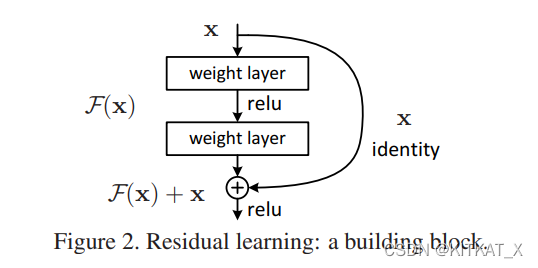
Deep Residual Learning for Image Recognition
网络深度↑,性能↓。消过拟合、减小训练误差、测试误差。
输入+输出
i-REVNET: DEEP INVERTIBLE NETWORK
一个以时间换空间的可逆Res-Net
证明gx可逆即证明x迭代式是收敛的-> 
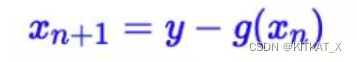
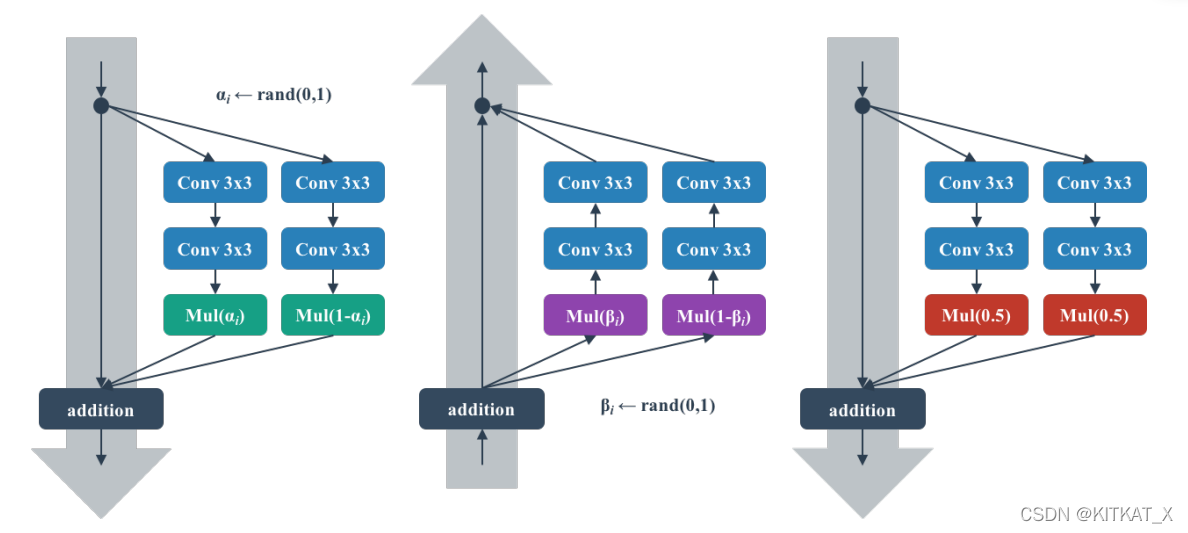
Shake-Shake regularization
adding noise to the gradient during training helps training and generalization of complicated neural networks.
Shake-Shake regularization can be seen as an extension of this concept where gradient noise is replaced by a form of gradient augmentation.

















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









