









HDFS的安装部署
一、简介
HDFS前言:
设计思想:(分而治之)将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析。
在大数据系统中作用:为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务。
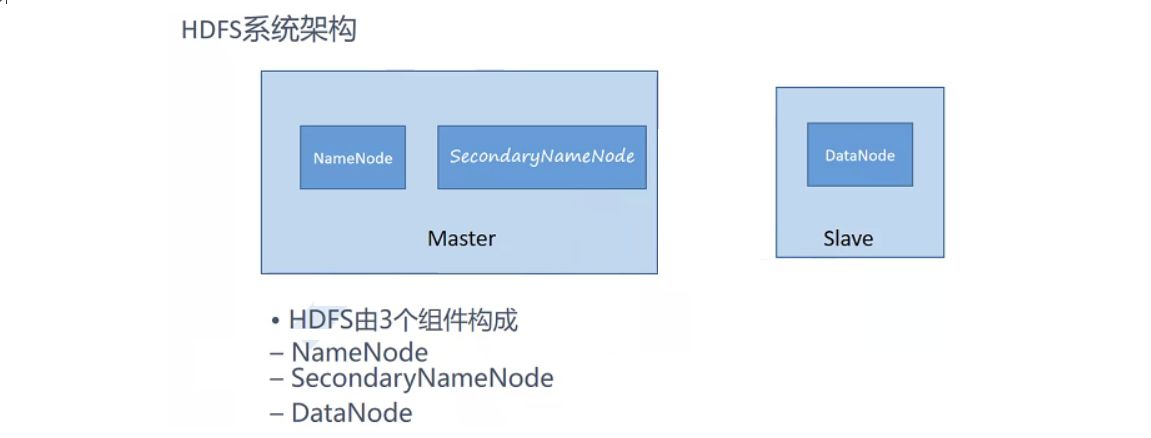
HDFS采用了主从式(Master/Slave)的体系结构,分NameNode、econdaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
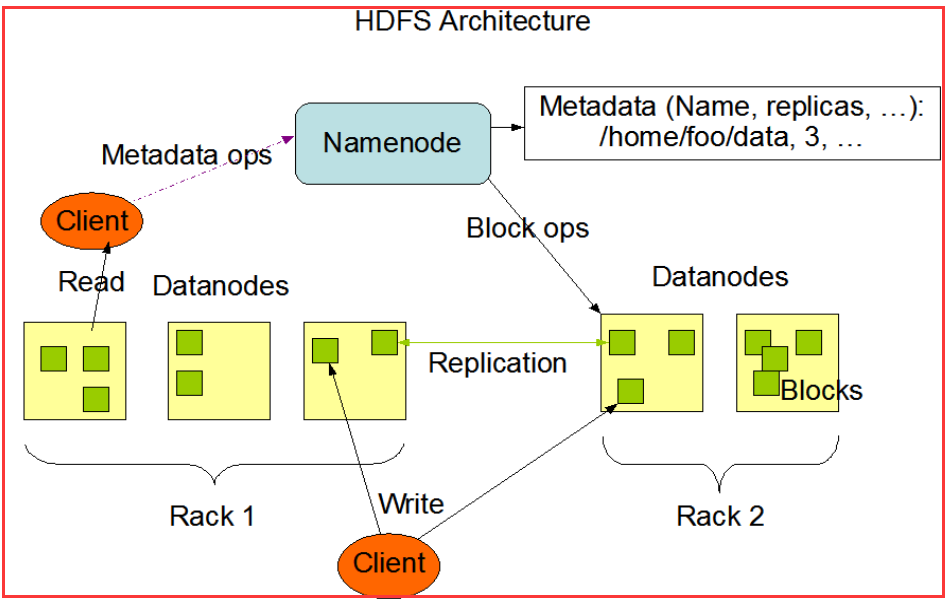
先来看看hdfs架构中的namenode。namenode是一个进程在某一个节点(机器)上,本身维护一块内存区域。内存中存储两份最重要的数据(元数据通过datanode通过心跳机制保证,datanode有新增数据,通过心跳机制告诉namenode):
- 1.文件名->block数据块的映射关系(mapping关系)
- 2.block数据块到datanode节点之间的映射关系
本质:通过block数据块找到数据真正存储的本地地址。
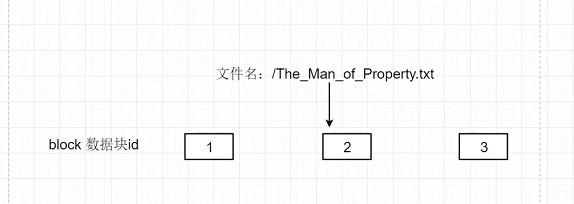
整个1、2、3数据块合起来就是文件的内容。
比如说,取快递,首先会收到快递信息,信息有快递存放的地址和快递箱。通过这个信息就能找到快递,相当于手机就是NN(主),通过查看收集上的快递信息(NN上的文件名与block数据块映射信息),找到快递是存在哪个快递箱里(找到对应的DN),再到指定的快递箱(DN)输入对应的编码(block数据块到dn节点之间的映射关系),就能取到对应的快递(数据)。
在存储数据时,首先要找NN分配DN来写入数据。hdfs默认会存储三份数据副本。
1.NameNode(NN)作用:
- 管理着文件系统命名空间
- 存储元数据
- 保存文件,block, datanode之间的映射关系
- 元信息持久化
- 运行 Namenode会占用大量内存和I/O资源
- Hadoop更倾向存储大文件原因
为什么hadoop更倾向于存储大文件?
namenode内存有限,如果内存存放大量小文件,会占用大量内存和I/O资源,使得集群反应速度慢。所以,hadoop不适合存储大量的小文件。hdfs1.0的块大小是64M,hdfs2.0是128M。
总结:
1.对于集群硬盘资源造成严重浪费;
2.nn本身内存有限,造成namenode内存溢出;
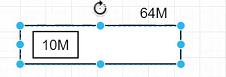
假设有一个块,大小64m,但是存储的文件大小是10m,就浪费了54m的空间,对集群的硬盘资源造成了严重浪费。
2.DataNode(NN)作用
- 负责存储数据块,负责为系统客户端提供数据块的读写服务
- 根据 Namenodel的指示进行创建、删除和复制等操作
- 心跳机制,定期报告文件块列表信息
3.容错–数据可靠性
-
一个NN和多个DN
-
故障检测
-
-
数据节点
-
- 心跳包(检测是否宕机):dn和nn随时保持心跳,3s一次,保证集群可靠性;
- 快报告(安全模式下检测)
- 数据完整性检测(校验和比较–crc32)
-
-
空间回收机制
-
- Trash目录:-skipTrash(删除的文件跳过回收站直接删除)
-
数据复制(冗余机制)
-
- 副本-数据冗余存放(机架感知策略)
-
snn,保证镜像文件数据可以恢复;
4.HDFS特点
优点
- 存储并管理PB级数据
- 处理非结构化数据
- 注重数据处理的吞吐量(延迟不敏感)
- 应用模式:write-once-read-many存取模式(无数据一致性问题)
缺点
-
存储小文件(不建议)
-
大量随机读(不建议)
-
需要对文件修改(不建议)
-
- 对文件修改会影响块进行重新分配,块分配又会影响到和多个dn节点间进行网络通讯;
-
多用户写入(不支持)
hdfs不适合场景
存储海量小文件
文件被修改
大量随机读取,对于大数据的文件读取,更倾向于顺序读,因为随机读取需要寻址,浪费时间影响效率,而且顺序读取的效率会比内存读取要高
二、集群环境搭建
虚拟机上准备三台服务器,可以考虑通过克隆来快速创建。
克隆服务器
以下是针对每一台服务器的操作。
1)修改主机名
hostnamectl set-hostname clu00
hostnamectl set-hostname clu01
hostnamectl set-hostname clu02
2)配置静态IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
#三台服务器根据虚拟机中的网络设置,确定IP段,分别设置不同的IP
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="static" #静态IP
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens33"
UUID="2d20e204-e445-4dd0-adaa-82ca0e5c5d03"
DEVICE="ens33"
ONBOOT="yes" #开启网络
IPADDR=192.168.81.10 #设置IP
GATEWAY=192.168.81.2
NETMASK=255.255.255.0
DNS1=8.8.8.8
DNS2=8.8.4.4
#配置完后,重启网络
systemctl restart network
3)添加主机和IP的映射
vim /etc/hosts
#注释或删除原有内容,添加如下内容
192.168.81.10 clu00
192.168.81.11 clu01
192.168.81.12 clu02
4)关闭防火墙
#查看:
systemctl status firewalld.service
#关闭:
systemctl stop firewalld.service
#启动:
systemctl start firewalld.service
5)创建hadoop用户
(base) [root@clu00 ~]# useradd hadoop
(base) [root@clu00 ~]# passwd hadoop
#用户名,密码均为hadoop
6)设置免密登陆
注意,由于涉及启动的操作权限问题,此处的免密登陆统一采用hadoop用户
[hadoop@clu00 ~]$ ssh-keygen
[hadoop@clu01 ~]$ ssh-keygen
[hadoop@clu02 ~]$ ssh-keygen
[hadoop@clu00 ~]$ ssh-copy-id clu00
[hadoop@clu00 ~]$ ssh-copy-id clu01
[hadoop@clu00 ~]$ ssh-copy-id clu02
[hadoop@clu01 ~]$ ssh-copy-id clu00
[hadoop@clu01 ~]$ ssh-copy-id clu01
[hadoop@clu01 ~]$ ssh-copy-id clu02
[hadoop@clu02 ~]$ ssh-copy-id clu00
[hadoop@clu02 ~]$ ssh-copy-id clu01
[hadoop@clu02 ~]$ ssh-copy-id clu02
三、Java开发环境部署
1)yum安装方式
安装java
yum list java* #检索包含java的列表
yum install -y java-1.8.0-openjdk.x86_64 #选择需要的版本进行安装
#安装默认的目录为:/usr/lib/jvm/
java -version #查看java版本
#以上安装完只有java,没有javac命令
yum install java-1.8.0-openjdk-devel.x86_64 #安装完整的java开发环境
java环境变量的配置
通过 yum install 安装 jdk,是不会自动配置 JAVA_HOME 环境变量的。如果有一些服务依赖这个环境变量就会启动失败。需要手动配置 JAVA_HOME 环境变量。
#找到JDK的安装路径
(base) [root@song jvm]# which java
/usr/bin/java
(base) [root@song jvm]# ls -lr /usr/bin/java
lrwxrwxrwx. 1 root root 22 Sep 22 16:32 /usr/bin/java -> /etc/alternatives/java
(base) [root@song jvm]# ls -lrt /etc/alternatives/java
lrwxrwxrwx. 1 root root 73 Sep 22 16:32 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64/jre/bin/java
#一步步找到正确的 JAVA_HOME 位置:
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64
#配置JAVA_HOME
vim /etc/profile
#在里面添加以下配置
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.302.b08-0.el7_9.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
#让配置生效
source /etc/profile
#测试是否成功
echo $JAVA_HOME
2)安装包安装方式
#下载解压(base) [root@clu00 ~]# mkdir /usr/java(base) [root@clu00 usr]# cd java(base) [root@clu00 java]# lsjdk-8u301-linux-x64.tar.gz(base) [root@clu00 java]# tar -xvf jdk-8u301-linux-x64.tar.gz #配置环境变量export JAVA_HOME=/usr/java/jdk1.8.0_301export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_HOME/bin
四、HDFS的安装部署
以下未特别指明,就是在每一台服务器的操作。可以重复操作,也可以配置完毕后直接scp拷贝传输修改后的文件。
尽量不使用root用户来操作,使用hadoop
root用户下,赋予hadoop的sudo权限
visudo
#添加hadoop的权限
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
1.下载解压安装包
下载地址:Index of /dist/hadoop/common (apache.org)
[hadoop@clu00 ~]$ ls
hadoop-3.3.0.tar.gz
[hadoop@clu00 ~]$ tar -xvf hadoop-3.3.0.tar.gz
2.添加环境变量
所有服务器都要配置修改。
[hadoop@clu00 ~]$ sudo vim /etc/profile
#添加如下内容,地址根据自己的实际路径指定
export HADOOP_HOME=/home/hadoop/hadoop-3.3.0
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
#修改后要让配置生效
[hadoop@clu00 ~]$ source /etc/profile
3.修改配置文件
HDFS的配置文件:大多数默认是XML和TXT格式存在。配置文件默认存放在/etc/hadoop目录下。
HDFS中6个重要的配置文件:
- core-site.xml:Hadoop全局的配置文件,也包含一些HDFS的宏观配置。
- dfs-site.xml:HDFS配置文件。
- yarn-site.xml:YARN配置文件。
- mapred-sie.xml:MapReduce配置文件。
- slaves:从节点列表。
- hadoop-env.sh:与运行脚本的环境变量相关的配置文件。
在主节点
[hadoop@clu00 ~]$ cd /home/hadoop/hadoop-3.3.0
[hadoop@clu00 hadoop-3.3.0]$ ls
bin include libexec licenses-binary NOTICE-binary README.txt share
etc lib LICENSE-binary LICENSE.txt NOTICE.txt sbin
[hadoop@clu00 hadoop-3.3.0]$ mkdir hdfs/tmp -p
[hadoop@clu00 hadoop-3.3.0]$ mkdir hdfs/name -p
[hadoop@clu00 hadoop-3.3.0]$ mkdir hdfs/data -p
1).hadoop-env.sh
[hadoop@clu00 hadoop-3.3.0]$ cd etc/hadoop/
[hadoop@clu00 hadoop]$ vim hadoop-env.sh
#修改添加如下内容,实际路径根据自己jdk路径
export JAVA_HOME=/usr/java/jdk1.8.0_301
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
2).core-site.xml
[hadoop@clu00 hadoop]$ vim core-site.xml
#要指定集群的Namenode以及对应端口,此处为clu00:9000
#
<configuration>
<property><!--指定namenode的地址-->
<name>fs.defaultFS</name>
<value>hdfs://clu00:9090</value>
</property>
<property><!--用来指定使用hadoop时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-3.3.0/hdfs/tmp</value>
</property>
</configuration>
3).hdfs-site.xml
hdfs-site.xml:HDFS的重要配置文件,其Namenode节点和Datanode节点相关的配置项不同。
Namenode主要有3个配置项:dfs.namenode.name.dir、dfs.blocksize、dfs.replication。
Datanode主要有1个配置项:dfs.datanode.data.dir。
//Namenode主要有3个配置项dfs.namenode.name.dir、dfs.blocksize、dfs.replication。
//Datanode主要有1个配置项dfs.datanode.data.dir
[hadoop@clu00 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop-3.3.0/hdfs/name</value>
<!--namenode的目录位置,对应的目录需要存在value里面的路径-->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop-3.3.0/hdfs/data</value>
<!--datanode的目录位置,对应的目录需要存在value里面的路径,可以是一个或多个用逗号分隔的本地路径-->
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
<!--hdfs系统的副本数量-->
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>clu01:50090</value>
<!--备份namenode的http地址,clu00是主机名-->
</property>
</configuration>
4)mapred-site.xml
[hadoop@clu00 hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>clu00</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5) yarn-site.xml
[hadoop@clu00 hadoop]$ vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>clu00</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
6)workers
[hadoop@clu00 hadoop]$ vim workers
#
clu01
clu02
4.拷贝hadoop文件
[hadoop@clu00 hadoop]$ scp -rq /home/hadoop/hadoop-3.3.0 clu01:/home/hadoop/
[hadoop@clu00 hadoop]$ scp -rq /home/hadoop/hadoop-3.3.0 clu02:/home/hadoop/
提示:若未通过克隆来得到统一的jdk环境,也可以通过scp来拷贝传输;以及环境变量文件。
提示:若未通过克隆来得到统一的jdk环境,也可以通过scp来拷贝传输;以及环境变量文件。
注意:任何配置修改后,都需要同步到集群所有节点上,再进行启动。
5.启动
[hadoop@clu01 ~]$ cd /home/hadoop/hadoop-3.3.0/sbin/
[hadoop@clu01 sbin]$ hdfs namenode -format #第一次启动时,才需要格式化格式化主节点
#出现下面即成功
2021-09-26 17:22:23,322 INFO common.Storage: Storage directory /home/hadoop/hadoop-3.3.0/hdfs/name has been successfully formatted.
[hadoop@clu01 sbin]$ ./start-dfs.sh #统一启动
[hadoop@clu00 sbin]$ ./start-all.sh #启动所有
[hadoop@clu00 sbin]$ ./stop-dfs.sh #统一关闭
提示:启动过程中若出现操作权限问题,被拒绝,查看前面此刻的用户是否与前面设置免密登陆的用户一致,推荐都是用hadoop用户。
6.测试
#主中心
[hadoop@clu00 sbin]$ jps
23090 NameNode
23350 Jps
#子中心
[hadoop@clu01 hadoop]$ jps
6384 DataNode
6497 SecondaryNameNode
6531 Jps
[hadoop@clu02 ~]$ jps
4672 DataNode
4735 Jps
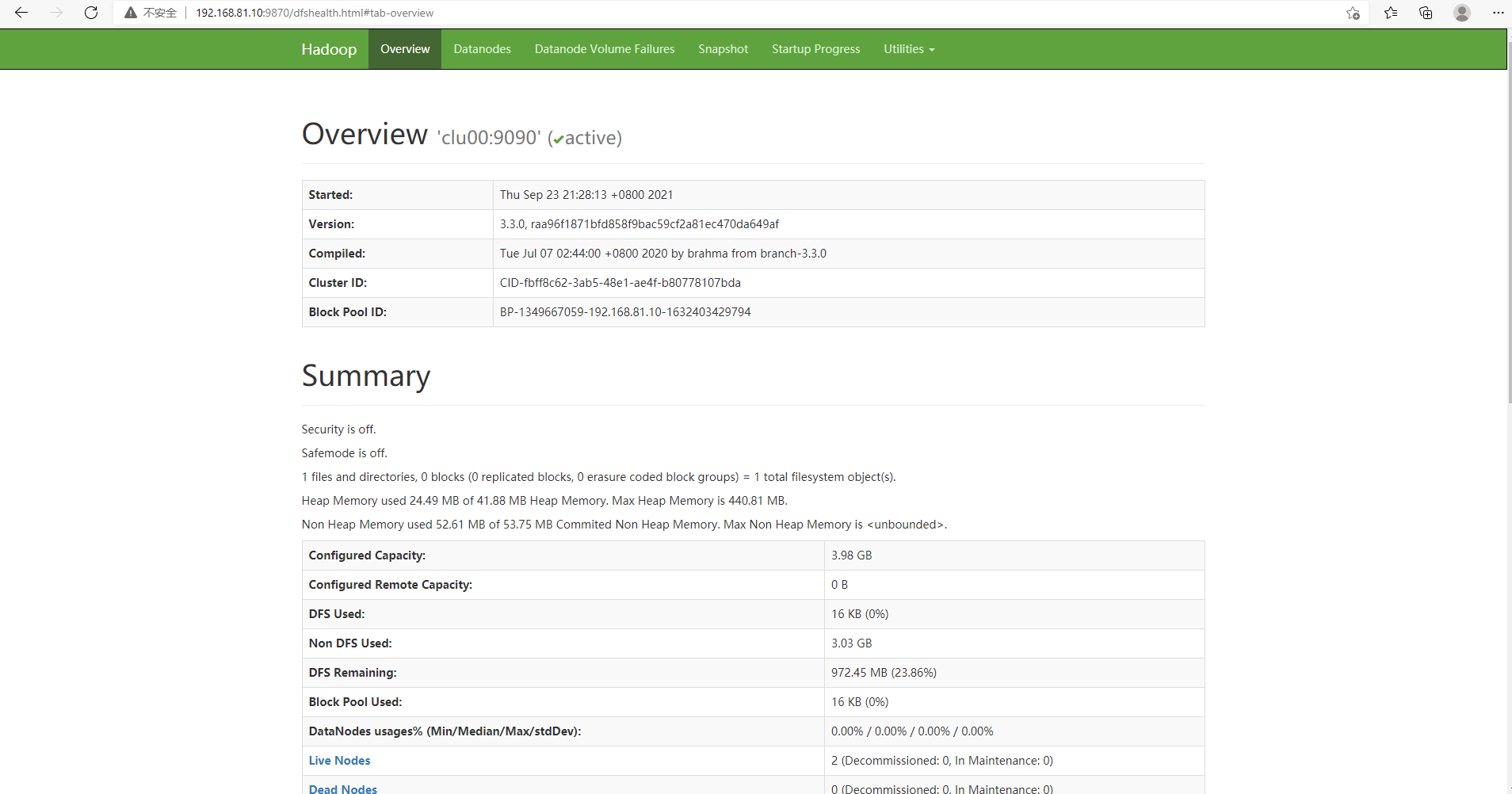
7.Web界面访问
访问hadoop web输入192.168.81.10:9870
(hadoop3.0之后端口改成了9870,hadoop2.0是50070)

遇到的问题:
1)主节点启动后jps没有namenode,可能由于第一次启动,忘记格式化namenode
[hadoop@clu01 sbin]$ hdfs namenode -format
2)在目录进行操作,显示没有权限
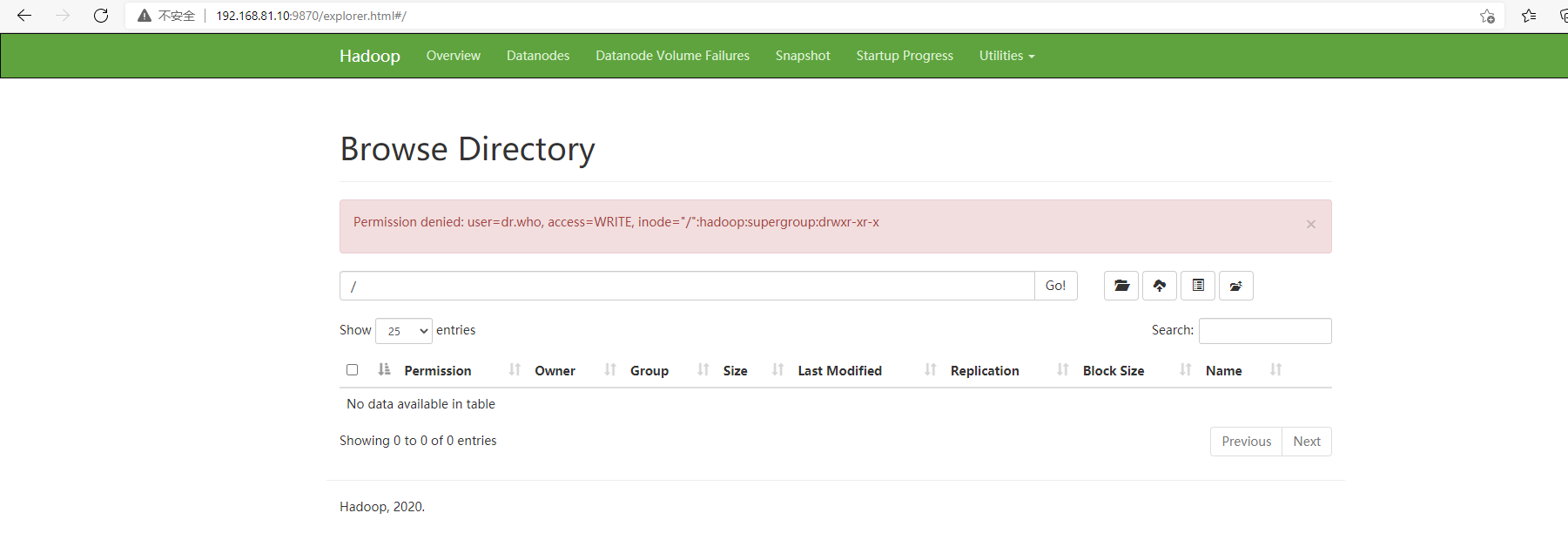
[hadoop@clu00 hadoop]$ vim core-site.xml
#添加以下内容,忽略权限检查
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
#修改配置后要在集群中同步配置
[hadoop@clu00 hadoop]$ scp -rq /home/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml clu01:/home/hadoop/hadoop-3.3.0/etc/hadoop/
hadoop@clu01's password:
[hadoop@clu00 hadoop]$ scp -rq /home/hadoop/hadoop-3.3.0/etc/hadoop/core-site.xml clu02:/home/hadoop/hadoop-3.3.0/etc/hadoop/
#关闭重启HDFS,以使配置生效
[hadoop@clu00 sbin]$ ./stop-dfs.sh
[hadoop@clu00 sbin]$ ./start-dfs.sh
3)启动hadoop集群后,查看进程发现名称节点的NameNode进程启动了,但是数据节点的DataNode进程没有启动。
原因为多次格式化namenode导致的namenode与datanode之间的不一致导致。
解决方法:
#停止集群
[hadoop@clu00 sbin]$ ./stop-dfs.sh
[hadoop@clu00 hadoop]$ vim hdfs-site.xml
#删除datanode存放数据的路径,可以在hdfs-site.xml中查看

#在所有节点执行删除操作
[hadoop@clu00 hadoop]$ rm -rf /home/hadoop/hadoop-3.3.0/hdfs/data/*
#重新格式化,启动集群
[hadoop@clu00 sbin]$ hdfs namenode -format
[hadoop@clu00 sbin]$ ./start-all.sh
hadoop集群启动后datanode没有启动_huss’s blog-CSDN博客_hadoop集群启动没有datanode
4)无法上传文件
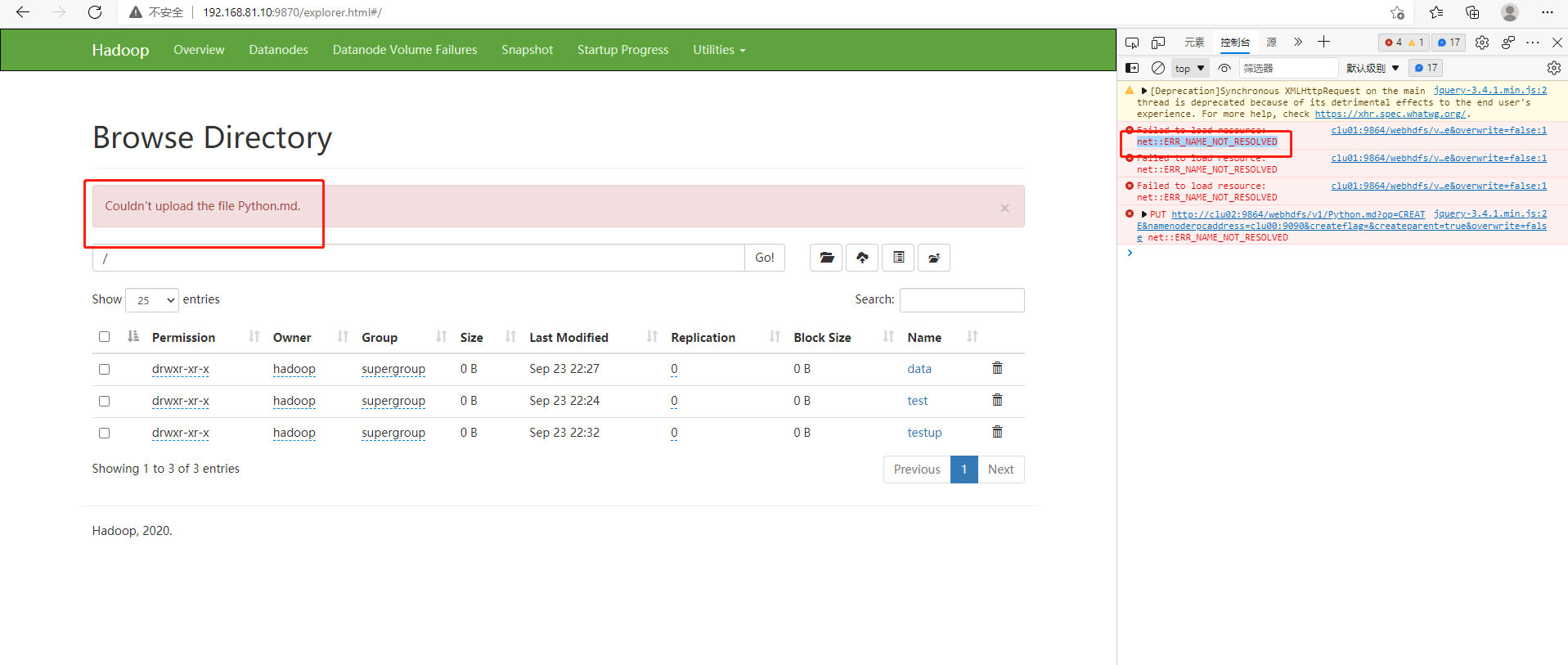
原因 : win10的hosts没有配置ip映射,无法解析域名clu00
解决办法:
点击此路径:C:\Windows\System32\drivers\etc
找到hosts,win10直接打开hosts是不可以更改的,所以怎么办呢?
将hosts文件复制到桌面(当然你可以复制到你想复制的地方),然后打开hosts文件,添加内容。
然后将写好的hosts文件Ctrl c,再次打开此路径C:\Windows\System32\drivers\etc。
Ctrl v 将文件粘贴到里边,提醒你有个一样的要不要替换目标文件。选择替换,OK
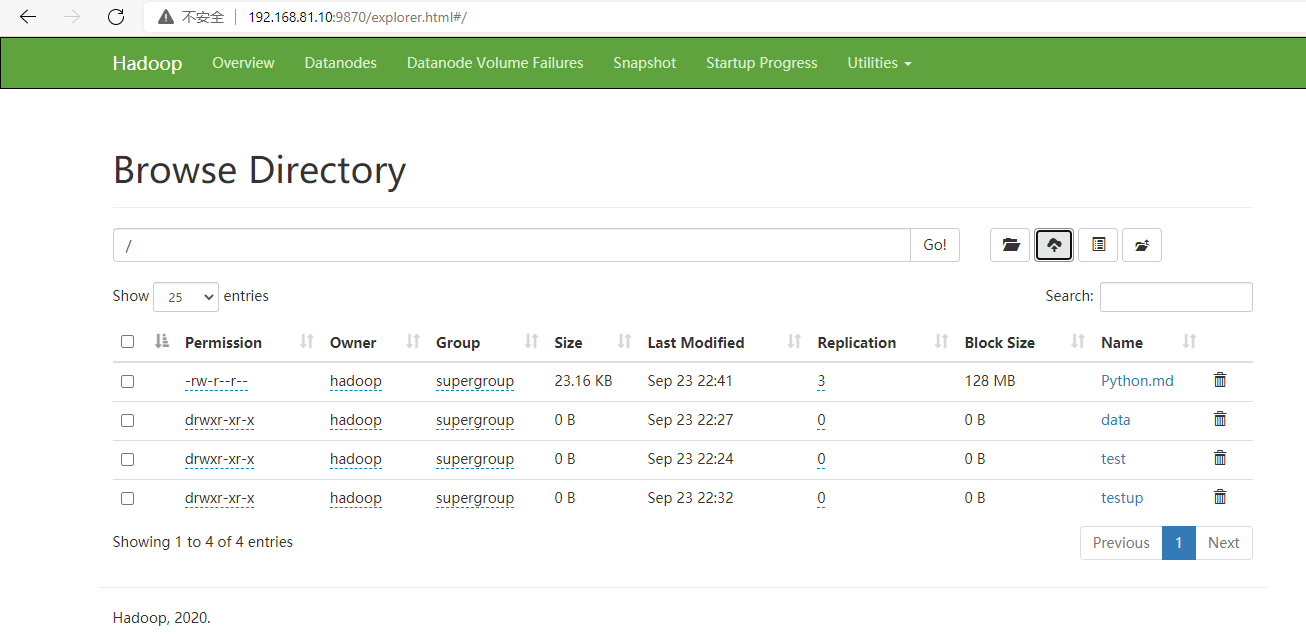
成功解决!
五、HDFS的简单使用
作为文件系统,HDFS的使用主要指对文件的上传、下载和移动,以及查看内容、建立或删除目录等。
查看HDFS状态,主要指查看节点的健康状态,查看存储容量,查看分块信息等。
控制HDFS,主要指对系统进行初始化,增加或删除子节点,以及提高HDFS的可用性等。
5.1 管理和操作命令
hdfs的命令行操作用命令hdfs实现,即命令行敲入:hdfs.
hdfs命令文件放在Hadoop目录下的bin子目录中,包含了HDFS绝大多数的用户命令,不带任何参数地执行hdfs,可以看到所有可用的指令。
- dfs:HDFS的文件系统操作指令。
- dfsadmin:HDFS的集群管理命令,比如:查看机架感知状态,可以执行hdfs dfsadmin-printTopology。
- fsck:HDFS的集群检查工具。
- namenode-format:主节点格式化指令。
- balaner:数据平衡指令。
5.2 格式化Namenode
hdfs namenode -format
(第一次启动前需要使用该指令)
5.3 Namenode的安全模式
当namenode启动时,需要将fsimage等信息读入内存,并且等待各个Datanode上报存储状态,在这个过程完成之前,叫安全模式。(safenode)
此时namenode为只读状态,只能读取不能写入,当足够数量的节点以及数据块处在健康状态时,系统会自动退出安全模式。
手动对安全模式进行管理:hdfs dfsadmin -safemode [enter | leave |get |wait]
5.4 元数据恢复
由于secondary namenode在进行元数据合并时,保存了元数据的副本信息,当Namenode发生损坏时,可以利用secondary namenode中的数据进行恢复。
- 利用stop-dfs.sh命令停止整个集群
- 清空namenode原有的元数据信息,路径可以从配置项dfs.namenode.name.dir中获得。
- 如果secondary namenode和namenode没有部署在同一个节点上,需要将secondary namenode存储的副本信息复制到namenode,其路径和secondary namenode中的元数据副本的路径一致,可以从配置项dfs.namenode.checkpoint.dir中获得。
- 执行hadoop namenode-importCheckpoint,系统将检查副本数据,并将其复制到dfs.namenode.name.dir所指示的路径当中。
5.5 子节点添加与删除
大数据业务要求数据被不断采集、不断积累,需要分布式存储和NoSQL数据库等实现方便的横向扩展(scale out)。HDFS可以很方便的进行Datanode节点添加和删除。
1.静态添加/删除Datanode的方法
- 利用stop-dfs.sh命令停止整个集群
- 在namenode节点上的slaves配置文件中添加新的节点,或删掉旧的节点。添加新节点时,要确保新节点和其他节点之间主机名和IP地址可以相互访问,可以实现SSH无密码访问等。
- 利用start-dfs.sh重新启动集群,在新节点配置正确的情况下,会随命令启动Datanode角色,并和Namenode连接。
- 可以执行hdfs balancer命令,在节点之间进行手动的数据平衡。删除节点之后,namenode会自动检查副本数量,并选择新的节点存储不足的副本。
2.动态添加Datanode的方法
- HDFS集群保持运行状态
- 在namenode节点上的slaves配置文件中添加新的节点。
- 在新节点执行hadoop-daemon.sh start datanode ,启动Datanode角色
- 在主节点执行hdfs dfsadmin -refreshNodes,刷新节点列表,Namenode会根据新列表和子节点建立联系。
3.动态删除Datanode的方法
- HDFS集群保持运行状态
- 提前在hdfs-site.xml中配置dfs.hosts.exclude属性,内容为一个本地文本文件的路径,该文件可以称为exclude文件,其结构和slave文件的相同,即为每行一个节点主机名的列表。 记录在exclude文件中的主机,会在刷新之后被记作禁用状态,并在界面上看到这个状态。
- 在主节点执行hdfs dfsadmin -refreshNodes,刷新节点列表。
- 在节点写入exclude文件,并执行hdfs dfsadmin -refreshNodes,刷新节点列表。
添加/删除Datanode完成之后,可以通过两种手段查看结果。
- 在命令行执行hdfs dfsadmin -report 查看节点列表信息。
- 通过web界面,切换到Datanodes标签,可以查看子节点的列表,in operation表示正在使用的节点,decommissinoning,表示目前禁用的节点。
5.6 HDFS文件系统操作
可以通过执行hdfs dfs指令来进行各类操作,包括建立、删除目录、HDFS上的文件复制、移动和改名、本地文件系统和HDFS系统之间的文件相互复制等、文件的权限操作等。
- hdfs dfs -ls / ----查看文件目录状态
- hdfs dfs -lsr / ----递归查看hdfs的根目录下的内容的
- hdfs dfs -mkdir /d1 ----在hdfs上创建文件夹d1
- hdfs dfs -put ----把数据从linux[本地文件]上传到hdfs的特定路径中[HDFS文件或路径]
- hdfs dfs -get ----把数据从hdfs下载到linux的特定路径下
- hdfs dfs -mv/-cp —在HDFS系统中进行文件移动或复制,参数为HDFS的源地址和目的地址。
- hdfs dfs -text <hdfs文件> —将序列号文件转换成文本显示出来。
- hdfs dfs -rm <hdfs文件> ----删除文件或空目录
- hdfs dfs -rmr <hdfs文件> ----递归删除文件或空目录
5.7文件的权限与所属用户修改
#修改/alluxio的所属用户为hadoop
[hadoop@clu00 bin]$ hdfs dfs -chown -R hadoop /alluxio
#修改/alluxio的权限
[hadoop@clu00 bin]$ hdfs dfs -chmod 777 /alluxio
5.8 HDFS中将普通用户增加到超级用户组supergroup
Hadoop本身的用户和组的关系,都是同步Linux系统中的,但是HDFS和Linux的超级用户组又有一点差别,HDFS中的超级用户组是supergroup,但是Linux中默认是没有supergoup这个组,这个时候只需要在Linux中增加supergroup这个组,然后将要在HDFS中加入到supergroup中的用户加到这个组中,再同步HDFS用户和组即可。
#增加用户组
[hadoop@clu00 bin]$ sudo groupadd supergroup
#将hadoop用户加入到supergroup
[hadoop@clu00 bin]$ sudo usermod -a -G supergroup hadoop
#将root用户加入到supergroup
[hadoop@clu00 bin]$ sudo usermod -a -G supergroup root
#查看supergroup用户组下的所有成员
[hadoop@clu00 bin]$ grep 'supergroup' /etc/group
supergroup:x:1004:hadoop,root
#同步权限信息到HDFS
[hadoop@clu00 bin]$ su - hadoop -s /bin/bash -c "hdfs dfsadmin -refreshUserToGroupsMappings"















 2641
2641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









