







目录
一.K-means算法的原理和工作流程
1.算法原理
K-means算法是基于原型的,根据距离划分组的无监督聚类算法,对于给定的样本集,按照样本间的距离大小,将样本划分为K个簇,使得簇内的点尽量紧密相连,而簇间的点距离尽量大。
2.工作流程
step1:随机选取K个点作为聚类中心,即k个类中心向量
step2:分别计算其他样本点到各个类中心向量的距离,并将其划分到距离最近的类
step3:更新各个类的中心向量
step4:判断新的类中心向量是否发生改变,若发生改变则转到step2,若类中心向量不再发生变化,停止并输出聚类结果
二.K-means中常用的距离度量方法
1.欧几里得距离(欧氏距离)
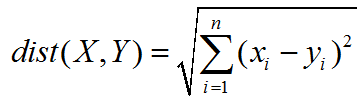
衡量多维空间中的两点间距离,也是最常用的距离度量方法。
2.曼哈顿距离

曼哈顿距离也叫出租车距离,用来标明两个点在标准坐标系上的绝对轴距总和。
3.切比雪夫距离

三.K-means算法中K值的选择
思考:如果我们的数据是关于色彩RGB数据,我们可以直接设置K为3对图片的参数进行聚类分析,这是在我们已知数据基本信息的前提下采取的策略。但是,如果我们并不知道数据的基本信息,怎么分类,分成几类就是我们不得不思考的问题,这时,我们更希望能够从数据的角度出发,判断这一组数据希望自己分成几类,即K为几时分类效果最好。
1.手肘法
1.简单描述手肘法
手肘法是最常用的确定K-means算法K值的方法,所用到的衡量标准是SSE(sum of the squared errors,误差平方和)
主要思想:当k小于真实聚类数时,随着k的增大,会大幅提高类间聚合程度,SSE会大幅下降,当k达到真实聚类数时,随着k的增加,类间的聚合程度不会大幅提高,SSE的下降幅度也不会很大,所以k/SSE的折线图看起
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3203
3203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









