










 本文详细描述了如何使用Python和BeautifulSoup库从高德地图API抓取特定城市的地铁站点名称和坐标数据,通过分析URL结构并解析HTML获取城市ID,进而构造请求获取JSON格式的地铁数据,最后将数据整理为DataFrame输出。
本文详细描述了如何使用Python和BeautifulSoup库从高德地图API抓取特定城市的地铁站点名称和坐标数据,通过分析URL结构并解析HTML获取城市ID,进而构造请求获取JSON格式的地铁数据,最后将数据整理为DataFrame输出。
获取各城市地铁站点及位置坐标-Python
1、基本介绍
我们的目标是编写一个 Python 函数,用于获取指定城市的地铁站数据,包括其名称和坐标
首先,高德地图提供了各城市地铁站点的数据,我们可以直接访问得到,可以通过下图发现,直接访问这个链接就可以得到某个城市的地铁的json数据
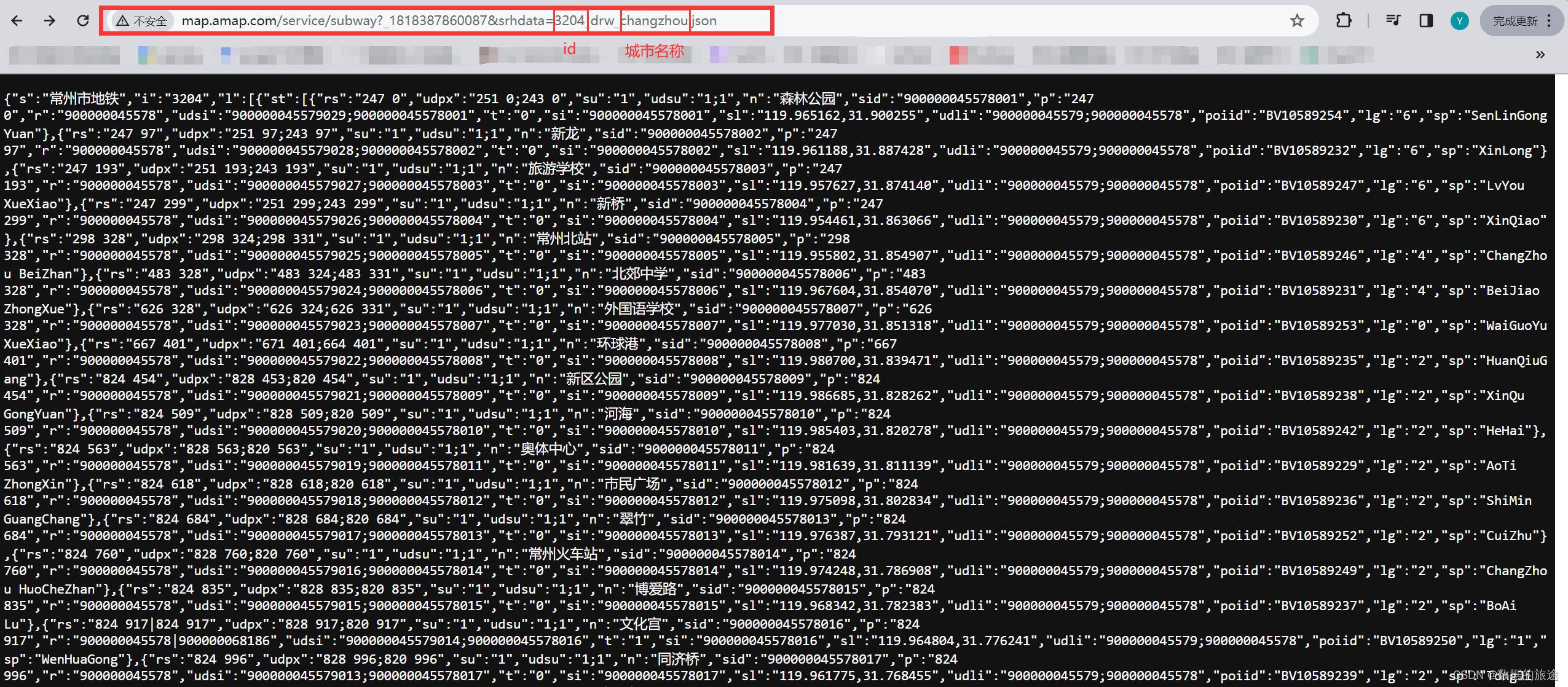
通过分析,我们发现这个链接是具有一定的规律的:
常州:http://map.amap.com/service/subway?_1708930872179&srhdata=3204_drw_changzhou.json
南京:http://map.amap.com/service/subway?_1708930872179&srhdata=3201_drw_nanjing.json
因此,url可以表示为下面这个格式
http://map.amap.com/service/subway?_1708930872179&srhdata={cityid}_drw_{cityname}.json
我们的目标是得到每个城市的ID,将{cityid}和{cityname}替换为对应的城市id及名称就OK
2、获取网页
这一步是通过高德地图得到每个城市的名称及对应的ID
url = 'http://map.amap.com/subway/index.html'
response = requests.get(url)
response_content = response.content.decode('utf-8')
response_content是通过请求网页所得到的高德地图html页面数据,接下来就是通过分析html页面,来得到存储每个城市的标签及属性
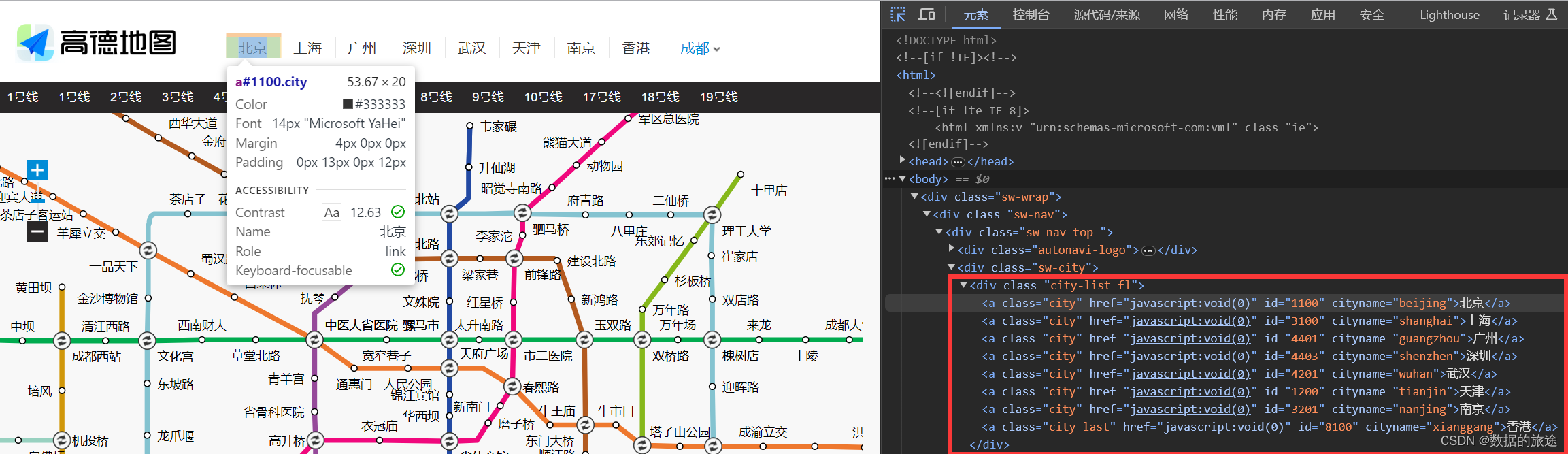
可以看到城市分为直接显示的,以及点击更多后所显示的

第一部分是页面直接显示的,保存在div标签中,class为city-list,同时可以看见城市的id就存储在a标签的id中,因此我们的目的就是取出每个a标签和其对应的id
第二部分是点击“更多”后显示的城市,保存在class为more-city-list的div标签中,其存储方式与上面类似
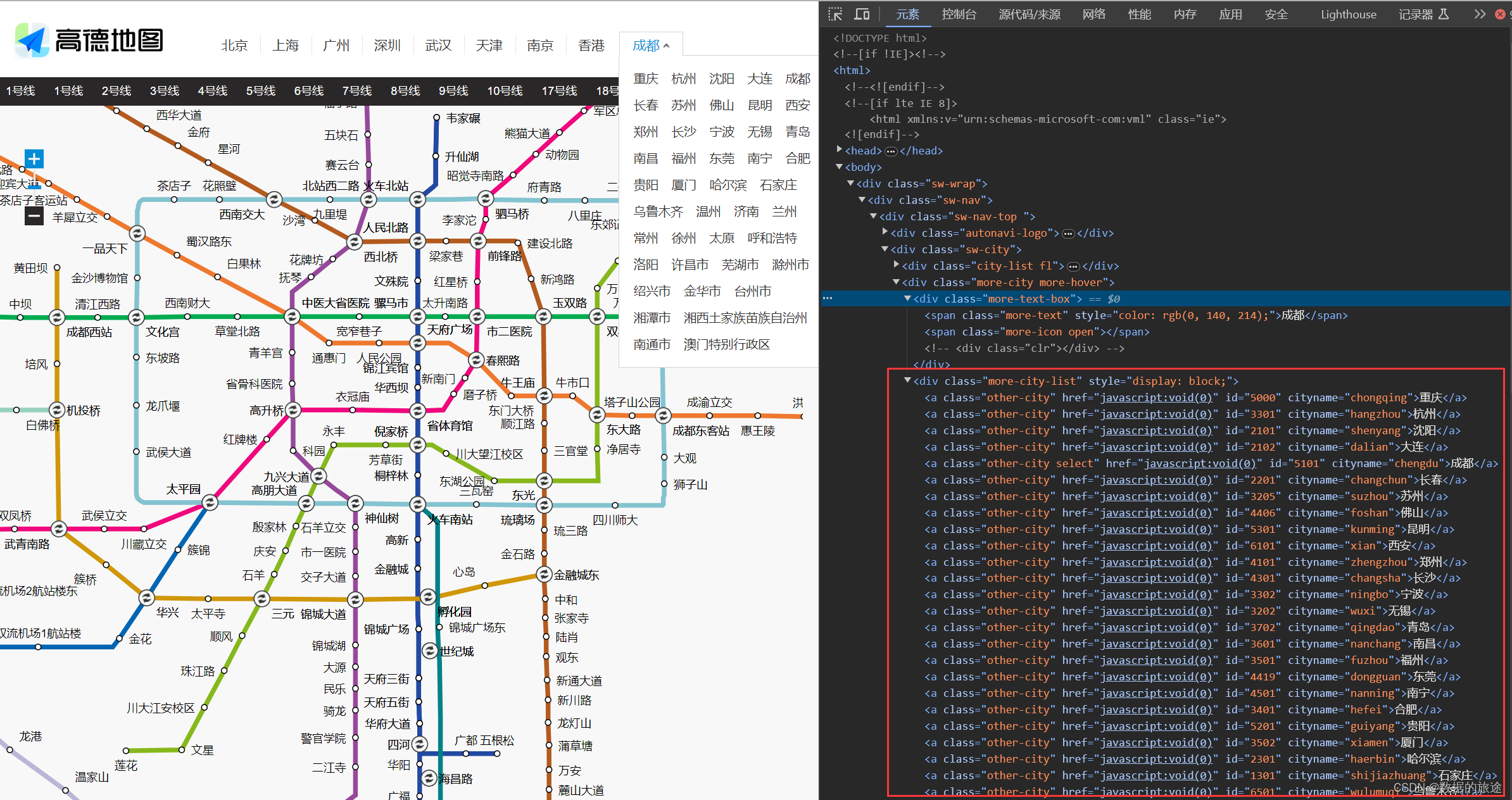
通过分析,我们可以发现每个城市的名称及对应的id均保存至<a>标签的cityname属性和id
3、获取城市及城市ID
接下来,我们就对BeautifulSoup对HTML进行解析,解析就是提取出我们所需要的内容
soup = BeautifulSoup(response_content, 'html.parser') # 创建BeautifulSoup解析对象
city_elements = soup.find_all('a', {'cityname': True, 'id': True}) # 在html文档中,搜索具有'cityname'和'id'的a标签,返回值:若干个a标签构成的列表
city_info = {el['cityname']: el['id'] for el in city_elements} # 使用字典推导式,保存城市及其对应的ID
4、获取地铁数据
获得城市 ID 后,我们就可以基于城市的名称及ID构建 URL 来获取 JSON 格式的地铁数据:
if city_name not in city_info:
return "City not found"
city_id = city_info[city_name] # 给定城市的名称,例如:chengdu,返回该城市的ID
subway_url = f'http://map.amap.com/service/subway?_1708930872179&srhdata={city_id}_drw_{city_name}.json' # json数据
subway_response = requests.get(subway_url) # 可以基于上述链接直接访问,也可以利用requests请求得到
subway_data = subway_response.json() # 格式化为json类型
5、提取站点数据
获得了包含地铁站点的json数据,我们需要根据该json数据的格式,提取站点的数据
stations_list = [
{
'Station Name': station['n'],
'Latitude': float(station['sl'].split(',')[1]),
'Longitude': float(station['sl'].split(',')[0]),
'Line': station['ln']
}
for line in subway_data['l'] for station in line['st'] if 'sl' in station
]
6、将数据作为 DataFrame 返回
df = pd.DataFrame(stations_list)
return df
完整的代码:
输入(Input):正确的城市的英文小写拼写(例如:chengdu、shanghai)
输出(Output):该城市地铁的站点以及经纬度
def get_subway_data(city_name:str):
url = 'http://map.amap.com/subway/index.html'
response = requests.get(url)
response_content = response.content.decode('utf-8')
soup = BeautifulSoup(response_content, 'html.parser')
city_elements = soup.find_all('a', {'cityname': True, 'id': True}) # Find all <a> tags with cityname and id attributes
# Extract city info
city_info = {el['cityname']: el['id'] for el in city_elements}
if city_name not in city_info:
return "City not found"
city_id = city_info[city_name]
subway_url = f'http://map.amap.com/service/subway?_1708930872179&srhdata={city_id}_drw_{city_name}.json'
subway_response = requests.get(subway_url)
subway_data = subway_response.json()
# Extract stations and their coordinates
stations_list = [
{'Station Name': station['n'],
'Latitude': float(station['sl'].split(',')[1]),
'Longitude': float(station['sl'].split(',')[0]),
'line':station['ln']
}
for line in subway_data['l'] for station in line['st'] if 'sl' in station
]
df = pd.DataFrame(stations_list)
return df
测试用例:
# Example usage
city_name = "chengdu" # Replace "chengdu" with the city you're interested in
stations_list = get_subway_data(city_name)
print(stations_list)
输出:
| Station Name | Latitude | Longitude | |
|---|---|---|---|
| 0 | 五根松 | 30.502041 | 104.081369 |
| 1 | 广都 | 30.510752 | 104.075713 |
| 2 | 四河 | 30.516133 | 104.070125 |
| 3 | 华府大道 | 30.525746 | 104.069836 |
| 4 | 天府五街 | 30.537107 | 104.069510 |
| ... | ... | ... | ... |
| 371 | 温泉大道 | 30.672593 | 103.855175 |
| 372 | 凤溪河 | 30.686109 | 103.843043 |
| 373 | 市五医院 | 30.698739 | 103.829423 |
| 374 | 黄石 | 30.721646 | 103.813977 |
| 375 | 金星 | 30.756182 | 103.794066 |
376 rows × 3 columns

















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









