







文章目录
映射和字典
抽象数据类型:计算机科学中具有类似行为的特定类别的数据结构的数学模型。
字典是一种映射(关联数组)。
字典是python中的数据结构。
映射的抽象数据类型
键值对以元组的形式存储。
映射最重要的五类行为:
| 操作 | 作用 |
|---|---|
| M[k] | 如果存在,返回M中与键k相对应的值,否则返回KeyError |
| M[k]=v | 将映射M中的值v与键k建立关联,若存在则替换该值 |
| del M[k] | 从映射中删除键为k的元组,若不存在,则返回KeyError |
| len(M) | 返回在映射M中的元组的数量 |
| iter(m) | 默认地对一个映射迭代生成其中所包含的所有键的序列 |
以上五项展示了映射的核心功能:请求、增加、删除、度量以及输出所有键值对。
以上功能分别用__getitem__,_setitem_,delitem__,__len__,__iter__实现
除此之外,还应实现的功能有12项:
| 操作 | 功能 |
|---|---|
| K in M | 如果映射中包含键为K的元组,则返回True |
| M.get(k,d=None) | 如果再映射中存在键k则返回M[k],否则返回缺省值d |
| M.setdefault(k,d) | 如果在映射M中存在键k,则返回M[k],如果键k不存在,则设置M[k]=d,并返回这个值 |
| M.pop(k,d=None) | 从映射M中删除键为k的元组,并且返回与其对应的值v。如果键k不在映射中,则返回缺省值d |
| M.popitem() | 从映射M中随机删除一个键值对,并返回相应的元组。若映射为空,则抛出KeyError |
| M.clear() | 从映射中删除所有的键值对 |
| M.keys() | 返回键集合 |
| M.values() | 返回值集合 |
| M.items() | 返回键值对集合 |
| M.updata(M2) | 对M2中的每一个键值对进行复制 |
| M == M2 | 判断是否完全相等 |
| M != M2 | 判断是否不等 |
MutableMapping抽象基类
可变映射。
抽象基类:类里定义了纯虚函数的类。
纯虚函数:未实现的函数,由基类的子类实现。
被定义为抽象的方法必须由具体的子类实现。
MutableMapping类为所有的行为提供了具体的实现,但不包含五大核心方法。
也就是说,只要提供了这五大核心方法,就可以将MutableMapping申明为父类来继承所有的衍生行为。
源自于collection模块。
MapBase类
为了更好地实现代码的重用,我们定义了自己的MapBae类,对组成设计模式提供了额外的支持。
创建了键值类,提供了对键的一些操作。
class MapBase:
class _Item(object):
def __init__(self,key,value):
self._key = key
self._value = value
def __eq__(self,other):
return self._key == other._key
def __ne__(self,other):
return not(self==other)
def __It__(self,other):
return self._key < other._key

简单的非有序映射实现
任意顺序存储键值对。
数组实现。
class UnsortedTableMap(MapBase):
def __init__(self):
self._table = []
def _find_item(self,k):
for item in self._table:
if item._key == k:
return item
return None
def __getitem__(self,k):
item = self._find_item(k)
if item == None:
return KeyError('This item does not exist!')
else:
return item._value
def __setitem__(self,k,value):
item = self._find_item(k)
if item == None:
new_item = self._Item(k,value)
self._table.append(new_item)
return new_item
else:
item._value = value
return item
def __delitem__(self,k):
item = self._find_item(k)
if item == None:
raise KeyError('This item does not exist!')
else:
item_index = self._table.index(item)
return self._table.pop(item_index)
def __len__(self):
return len(self._table)
def __iter__(self):
for item in self._table:
yield item._key
以上方法都可以在O(n)时间内完成。
哈希表
实现map的数据结构,dict的实现方式。
最简单的实现:1.对n个元组,创建一个长度为N的数组;2.根据键值整数,对相应的数组索引位置插入元素。

这样会带来两个问题:
1.如果N远大于n,那么我们不希望将数组表分配给这个映射;
2.一般不会要求键必须为整数。
哈希函数
哈希函数的目标就是把每个键映射到[0,N-1]区间内的整数。
在实践中可能会出现,不同的键被映射到同一索引上,因此,我们又称表为桶数组。
A
[
h
(
k
)
]
=
(
k
,
v
)
A[h(k)]=(k,v)
A[h(k)]=(k,v)
哈希冲突:两个集以上的键有相同的哈希值。
哈希函数的组成为:哈希码和压缩函数。
哈希码:将一个键映射到一个整数;
压缩函数:将哈希码映射到桶数组的一个索引。
哈希码
计算得到的整数不需要在[0,N-1]内,甚至可以是负数,希望能尽可能避免哈希冲突。
将位作为整数处理
整型在计算机中的存储为32位的二进制。
浮点型为64位表示。
字符串的每一个字符是16位表示。
我们可以统一为32位表示,采取异或操作,输出新的32位的值,并转化为整数。
多项式哈希码
上述方法没有考虑位置关系,比如“temp01”和“temp10”会当做同一整数处理。
我们可以采用多项式表示来区分不同的位置。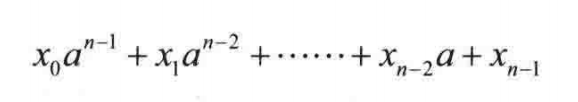
循环移位哈希码
用一定数量的位循环位移得到的部分和来代替乘以a。
可通过>>或<<来实现。
Python中的哈希码
python中计算哈希码的标准机制是一个内置的签名函数
h
a
s
h
(
x
)
hash(x)
hash(x)。
该函数将返回一个整型值作为对象x的哈希码。
在Python中,只有不可变的数据是可哈希的。
比如:int、float、str、tuple和frozen set。
用户可以采用__hash__定义自己的哈希函数。
压缩函数
通常,键k的哈希码不会直接适合使用一个桶数组,因为整数哈希码可能是负的或者可能超过桶数组的容量。需要把整数映射到[0,N-1]的区间上。
划分方法
i
m
o
d
N
i mod N
imodN
如果N不为素数,有很大风险会造成冲突。
MAD(Multiply-Add-and-Divide)方法
[
(
a
i
+
b
)
m
o
d
p
]
m
o
d
N
[(ai+b)modp]modN
[(ai+b)modp]modN
对i进行映射,N是桶数组大小,p是比N大的素数,a和b是从区间[0,p-1]任意选择的整数。
该函数使得任意两个不同键的冲突概率变成了1/N。
冲突处理方法
分离链表
每个桶
A
[
j
]
A[j]
A[j]存储其自身的二级容器。

对二级容器构造一个映射。
单独一个桶的操作时间与桶的大小成正比。
假设我们使用一个比较合适的哈希函数来在容量为N的哈希桶中索引map中的n个元组。
桶的理想大小为
n
N
\frac{n}{N}
Nn。
给定一个合适的哈希函数,核心map的操作时间为
O
[
⌈
n
N
⌉
]
O[\lceil\frac{n}{N}\rceil]
O[⌈Nn⌉]。
λ
=
n
N
\lambda=\frac{n}{N}
λ=Nn
被称为哈希表的负载因子,最好不大于1。
n不能超过N,不然必然会发生冲突。
开放寻址
分离链表有一点不足,需要使用一个链表作为辅助的数据结构来保存键值冲突的元组。
我们可以采用将每个元组直接存储到一个小的列表插槽中作为代替的方法。
线性探测及其变种
使用开放寻址处理冲突的一个简单方法是线性探测。
这种方法是对一级容器进行处理。
== 流程==
1.插入元组(k.v),依据j=h(k),插入A[j]处;
2.若A[j]被占用,插入到A[(j+1)modN]中。
3.若也被占用,插入至A[(j+2)modN]中。
4.直到找到合适的位置。

== 二次探测==
线性探测的问题:倾向于将一个映射的元组集中且连续地存储,可能会造成重叠。这样一种运行方式会导致搜索速度大大下降。
我们在此提出另一种开放寻址的策略——二次探测。
探测索引值为
(
h
(
k
)
+
f
(
i
)
)
m
o
d
N
,
其
中
f
(
i
)
=
i
2
(h(k)+f(i))mod N,其中f(i)=i^2
(h(k)+f(i))modN,其中f(i)=i2
说白了,就是插入的时候,随便找空位置,这样速度更快一些。
负载因子、重新哈希和效率
负载因子就是数据数量与桶个数的比值。负载因子接近1时,冲突发生的概率会急剧增加。
使用分离链表时,我们一般令负载因子小于0.9。
在开放寻址的方法中,负载因子过大还会导致聚集效应增强,使得找空位的时间大幅度增加。
因此,我们应该让负载因子小于0.5。
重新哈希
如果哈希表的插入操作引起了负载因子超过了指定的阈值,那么我们需要调整表的大小。将所有对象重新插入表总。
哈希码不用改变,但需要重新设计一个新的压缩函数。
新数组的大小至少为之前的一倍,通常设为两倍。
哈希表的效率
重新哈希会导致__setitem__与__getitem__摊销所增加的时间复杂度为O(1)
好的哈希函数,所有元组均匀分布。
坏的哈希函数,将所有元组映射到一个桶中,这将导致,无论是使用开放寻址还是分离链表,操作的开销都是线性增长的。

有序映射
除了标准映射的所有行为,还包含了
| 操作 | 作用 |
|---|---|
| M.find_min | 用最小键返回键值对,如果映射为空,则返回None |
| M.find_max | 用最大键返回键值对,如果映射为空,则返回None |
| M.find_It(k) | 用严格小于k的最大键返回键值对,如果映射为空,则返回None |
| M.find_Ie(k) | 用严格小于等于k的最大键返回键值对,如果映射为空,则返回None |
| M.find_gt(k) | 用严格大于k的最小键返回键值对,如果映射为空,则返回None |
| M.find_ge(k) | 用严格大于等于k的最小键返回键值对,如果映射为空,则返回None |
| M.find_range(start,stop) | 用start ≤ \le ≤键 ≤ \le ≤stop迭代遍历所有键值,一个为None,意味着一边为头 |
| iter(M) | 根据自然顺序从最小到最大,迭代遍历映射中的所有键 |
| reversed(M) | 根据逆序迭代映射中的所有键 |
排序检索表
class SortedTableMap(MapBase):
#二分查找 升序排序
def _find_index(self,key,low,high):
if high < low:
return high + 1 #low == high + 1
else:
mid = (high + low) // 2
if key == self._table[mid]._value:
return mid
elif key < self._table[mid]._value:
high = mid - 1
return self._find_index(key,low,high)
else:
low = mid + 1
return self._find_index(key,low,high)
def __init__(self):
self._table = []
def __getitem__(self,key):
index = self._find_index(key,0,len(self._table)-1)
if index == len(self._table) or self._table[index]._key != key:
return KeyError('This item does not exist!')
return self._table[index]._value
def __setitem__(self,key,value):
index = self._find_index(key,0,len(self._table)-1)
if index == len(self._table) or self._table[index]._key != key:
self._table[index].insert(index,self._Item(key,value))
else:
self._table[index]._value = value
def __delitem__(self,key):
index = self._find_index(key,0,len(self._table)-1)
if index == len(self._table) or self._table[index]._key != key:
return KeyError('This item does not exist!')
del self._table[index]
def __len__(self):
return len(self._table)
def __iter__(self):
for item in self._table:
yield item._key
def __reversed__(self):
for item in reversed(self._table):
yield item._key
def find_min(self):
if len(self._table) > 0:
return (self._table[0]._key,self._table[0]._value)
else:
return None
def find_max(self):
if len(self._table) > 0:
return (self._table[-1]._key,self._table[-1]._value)
else:
return None
def fine_It(self,key):
index = self._find_index(key,0,len(self._table)-1)
if index == 0 or index == len(self._table) or self._table[index]._key != key:
return None
else:
return (self._table[index-1]._key,self._table[index-1]._value)
def find_Ie(self,key):
index = self._find_index(key,0,len(self._table)-1)
if index == len(self._table) or self._table[index]._key != key:
return None
else:
return (self._table[index]._key,self._table[index]._value)
def find_gt(self,key):
index = self._find_index(key,0,len(self._table)-1)
if index >= len(self._table)-1 or self._table[index]._key != key:
return None
else:
return (self._table[index+1]._key,self._table[index+1]._value)
def find_ge(self,key):
index = self._find_index(key,0,len(self._table)-1)
if index == len(self._table) or self._table[index]._key != key:
return None
else:
return (self._table[index]._key,self._table[index]._value)
def find_range(self,start,stop):
if start is None:
index = 0
else:
index = self._find_index(start,0,len(self._table)-1)
while index < len(self._table) and (stop is None or self._table[index]._key<stop):
yield (self._table[index]._key,self._table[index]._value)
index += 1
跳跃表
实现排序映射ADT的数据结构。
关于搜索,排序数组允许以二分查找,所需时间为
O
(
l
o
g
n
)
O(logn)
O(logn);然而,采用链表结构的话,则在最坏情况下,需要
O
(
n
)
O(n)
O(n)。
关于更新,排序数组更新在最坏的情况下,时间复杂度为
O
(
n
)
O(n)
O(n),而链表则非常有效地支持更新操作。
跳跃表,则是一个折衷的方法以有效地支持查找与更新。
映射M的跳跃表S包含一列表序列。
每个列表依照键的升序存储着M的一个元组子集。
用两个标注为-∞和+∞的哨兵键追加元组。
列表S还需满足的条件有:
1.列表
S
0
S_0
S0包含映射M中的每一项(含∞);
2.对于
S
i
S_i
Si包含
S
i
−
1
S_{i-1}
Si−1;
3.列表
S
h
S_h
Sh仅包含无穷。

















 3151
3151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











