







文章目录
目前普通RNN存在的问题

记忆存储部分一直在任务中传递,倘若序列较长, 其参数的幂较大,易于出现梯度消失或者梯度爆照的问题。这就造成一般的RNN不能“长期依赖”。
因此我们引入LSTM。
Long Short-Term Memory 长短时记忆网络
引入
序列短时,相关的信息和预测的词位置之间的间隔小,RNN可以学会使用先前的信息;
然而,序列长时,相关信息和当前预测位置之间的间隔大,RNN会丧失学习到连接如此之远的信息的能力;这样一种丧失与记忆容量有关;
此外,序列过长时,会发生梯度爆炸或者梯度消失。
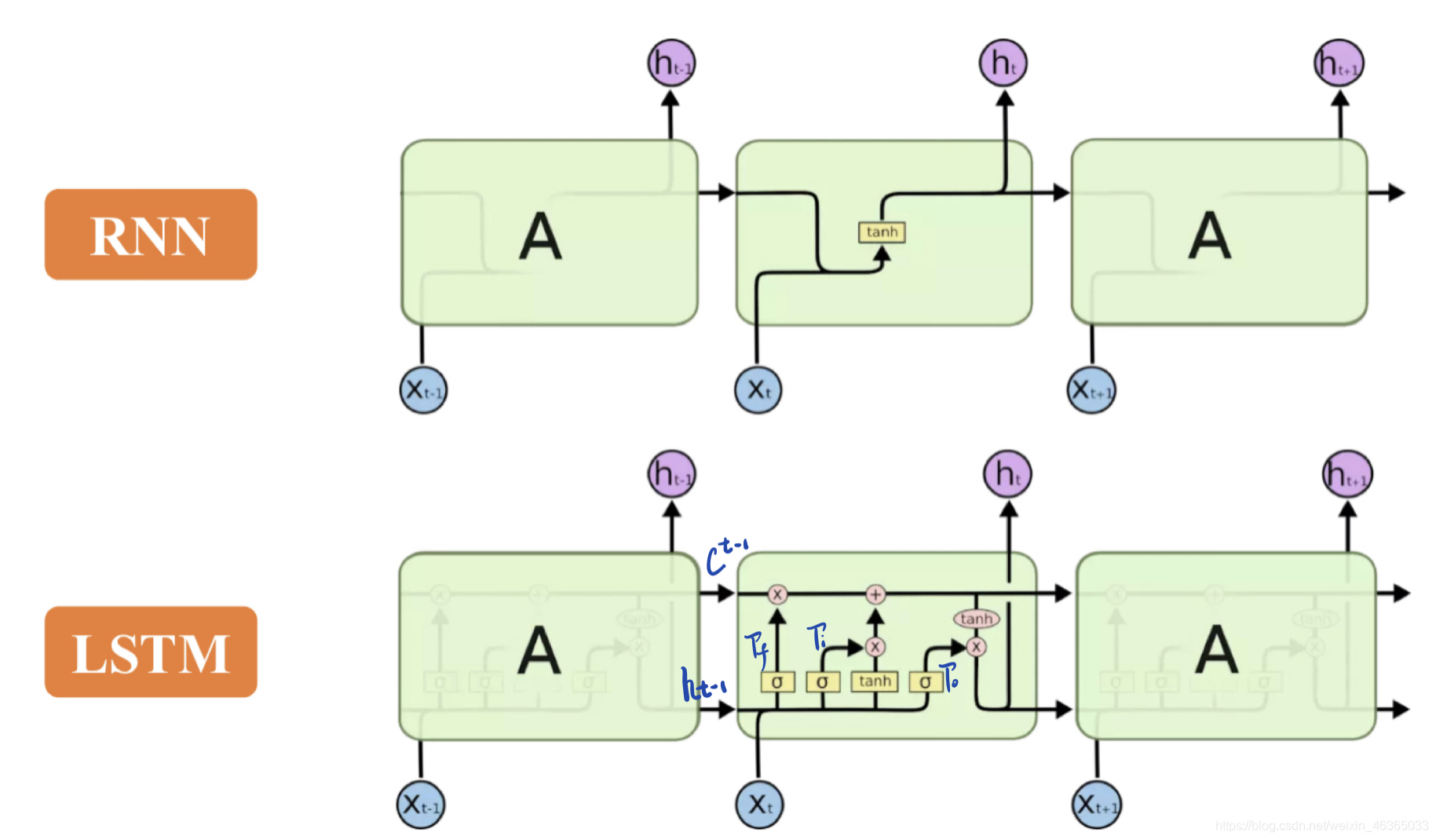
结构
整体结构

四个输入分别为:存入的记忆以及三个决定门开闭的信号
一个输出为:取出的记忆。
详细结构

图中的公式不考虑上一个隐层的输入。
四个输入,一个输出,五个激活函数点,一个结合点。
说明
1.与一般的神经网络相比,只需要将神经元变成LSTM的结构即可,同层神经元之间有了连接,但是不同层之间只是单个连接。
2.LSTM不仅仅是更新
c
<
t
>
c^{<t>}
c<t>,其实还会把输出作为输入,把记忆也作为输入(变种):
其中 h t ≠ y t h_t \not =y_t ht=yt。这与SRN类似,但多了一个记忆单元。
3.其中,输入 x t x^t xt经过四个transform转化为三个信号一个输入数据,用以运行LSTM,每一个input都是一个向量,控制多个LSTM。
4.能够解决梯度消失的情况。只要遗忘门开启,之前的影响也一直在,不存在记忆单元有限的问题。(不能解决梯度爆炸问题,记忆单元有限和梯度消失其实是类似的)
- 打开门;
- 计算候选隐藏状态;
- 更新记忆单元;
- 得到隐藏状态。
为什么LSTM能解决梯度问题?
原本:
ω
1
(
ω
1
⋅
x
1
+
x
2
)
\omega_1(\omega_1\cdot x_1 + x_2)
ω1(ω1⋅x1+x2)
LSTM:
c
<
2
>
=
Γ
i
c
^
<
2
>
+
Γ
f
c
<
1
>
c^{<2>} =\Gamma_i\widehat{c}^{<2>} + \Gamma_fc^{<1>}
c<2>=Γic
<2>+Γfc<1>
导致梯度爆炸/梯度消失的罪魁祸首是递归的导数一直大于1,或者一直在0和1之间,而LSTM的递归导数在不同的情况下,控制门控取值,从而抑制梯度消失或者爆炸,保持梯度。
公式
无peephole。


GRU(Gated Recurrent Unit)
门控循环单元,LSTM的简化版。
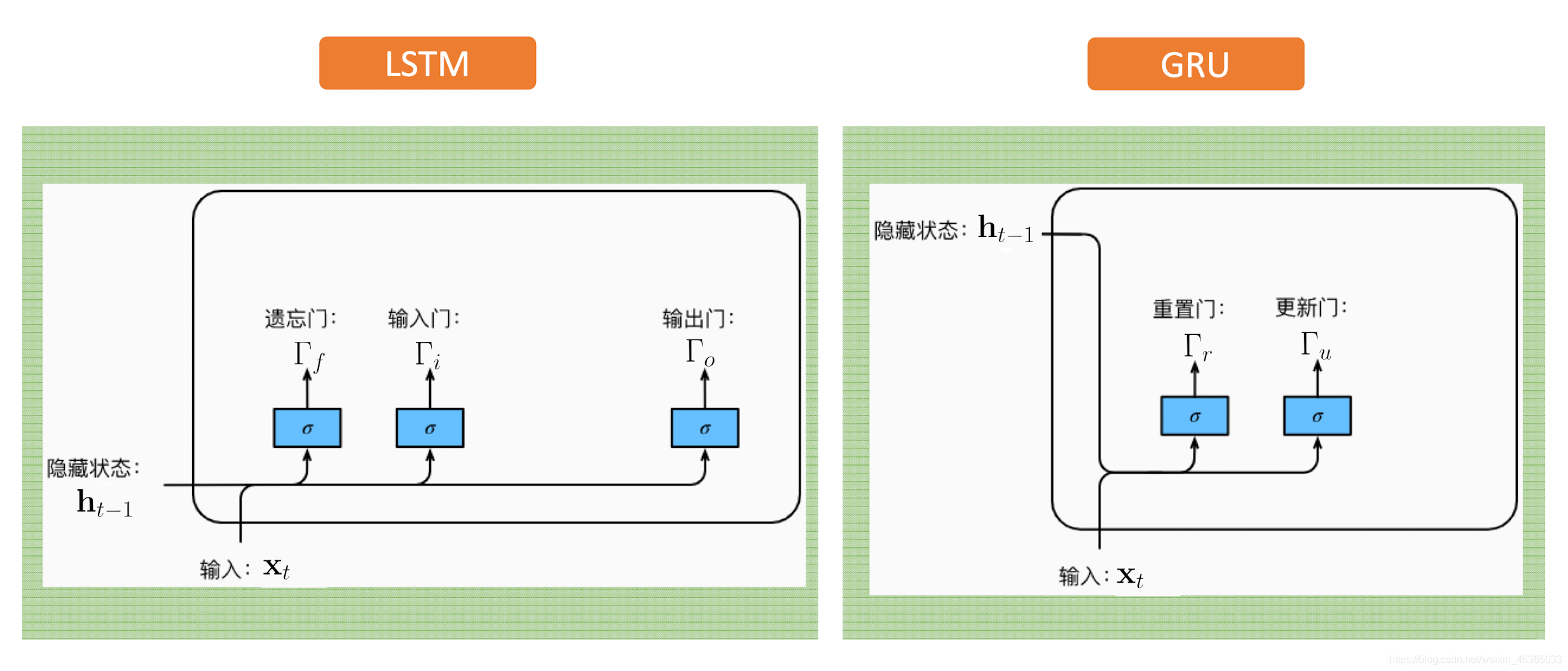
结构与公式
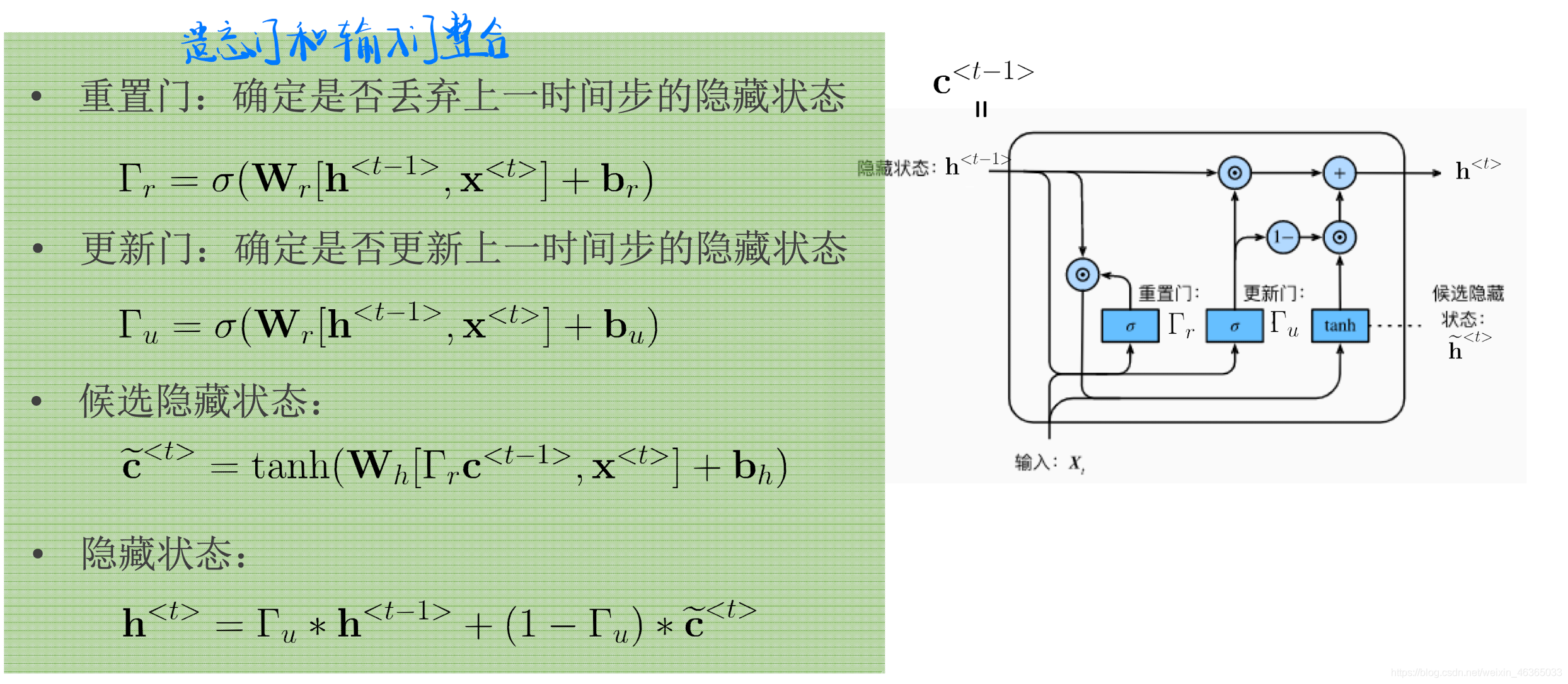

- 先打开门;
- 计算候选隐藏状态;
- 得到更新隐藏状态。
优势
参数少,过拟合风险小:
LSTM的参数量是Navie RNN的四倍,参数量过多就会存在过拟合的风险,而GRU只用两个门控开关就达到了和LSTM接近的结果,参数量不过是Naive RNN的三倍。
循环神经网络的应用与实践
词嵌入、情感分类、语音识别、Seq2Seq、Auto-encoder、图像加字幕、音乐生成。
注意力模型
机器翻译的问题:
文本序列越长,机器翻译的准确率越低。这是由于RNN无法记忆整个长句子。
机器翻译网络由encoder和decoder组成,decoder只接受encoder的最后一个输出,作为encoder的输入。这一个输入承载着网络对整句话的记忆,显然,要想记明白是比较困难的。
因此,引入了记忆力机制:与其输入最后一个隐藏层的状态,不如使用encoder过程中的所有隐藏层编码。
Attention Model的具体做法是:通过一个RNN网络为每个时刻生成一个分数(基于不同时刻的隐状态),然后这些分数经过一个softmax得到一个概率分布,这些概率代表着分配多少注意力。
之后呢,根据Attention给出的权重将encoder的所有隐状态结合起来,就是我们得到的上下文向量。
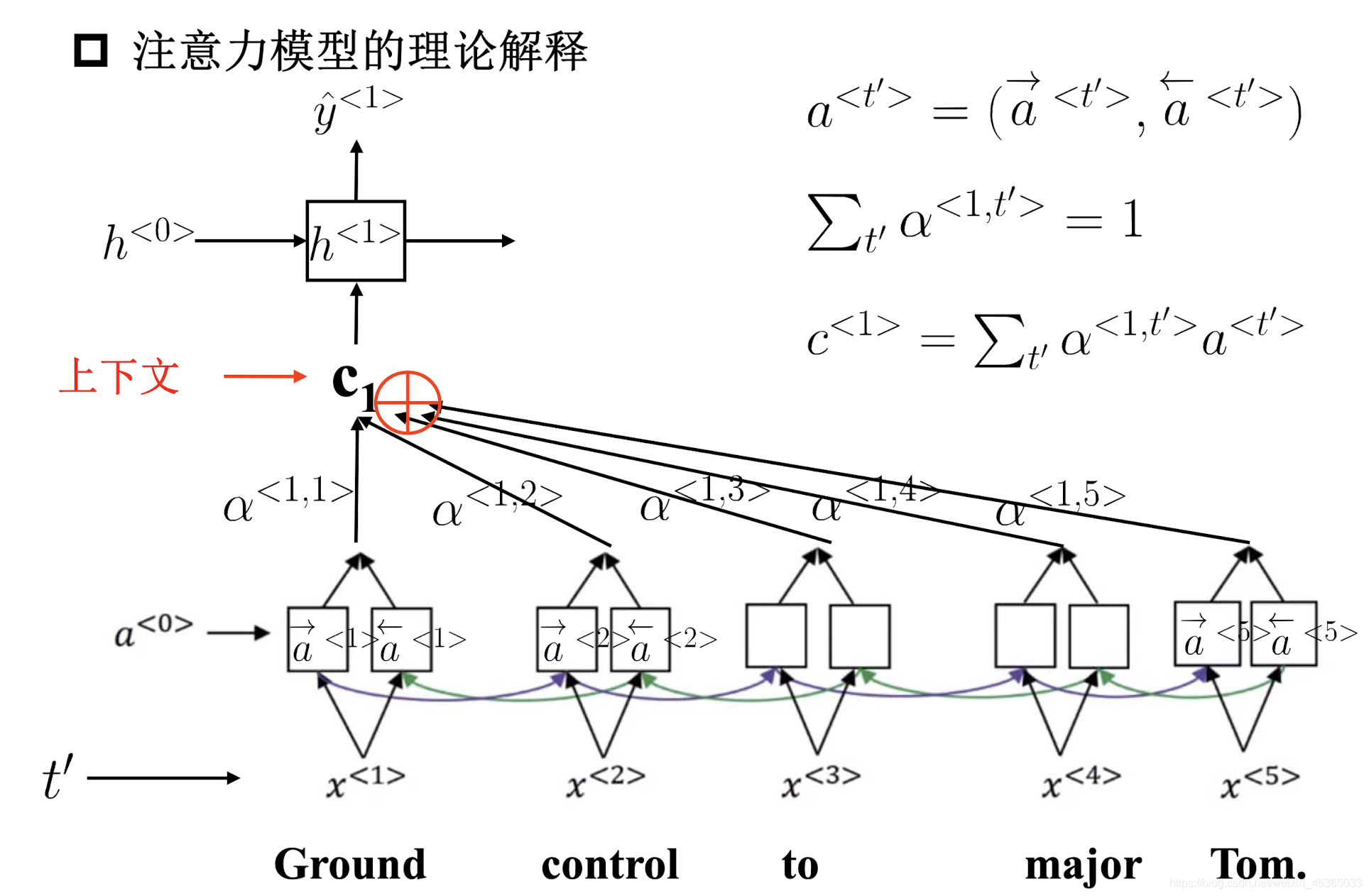
a
<
t
′
>
a^{<t'>}
a<t′>是“encoder”中的隐藏层状态,
a
<
1
,
2
>
a^{<1,2>}
a<1,2>是预测第一个单词时,分配给第二个单词的注意力。
c
<
1
>
c^{<1>}
c<1>是第一个单词的上下文向量。我们作为翻译RNN Model的输入。
Bleu得分

该得分是用来评估机器翻译系统的。
P
r
e
c
i
s
i
o
n
n
=
∑
c
∈
c
a
n
d
i
d
a
t
e
s
∑
n
−
g
r
a
m
∈
c
C
o
u
n
t
c
l
i
p
(
n
−
g
r
a
m
)
∑
c
′
∈
c
a
n
d
i
d
a
t
e
s
∑
n
−
g
r
a
m
′
∈
c
′
C
o
u
n
t
(
n
−
g
r
a
m
′
)
Precision_n=\frac{\sum_{c\in candidates}\sum_{n-gram\in c}Count_{clip}(n-gram)}{\sum_{c'\in candidates}\sum_{n-gram'\in c'}Count(n-gram')}
Precisionn=∑c′∈candidates∑n−gram′∈c′Count(n−gram′)∑c∈candidates∑n−gram∈cCountclip(n−gram)
candidate是神经网络生成的句子,reference是标准译文;
分子部分:
第一个求和符号是统计所有的candidate,翻译给出的可能不止一句话;
第二个求和符号是统计一条candidate中的所有n-gram,n-gram是n元词组;
C
o
u
n
t
c
l
i
p
(
n
−
g
r
a
m
)
Count_{clip}(n-gram)
Countclip(n−gram)表示某一个n-gram在reference中的个数。
分母部分:
前两个求和符号的含义一致;
C
o
u
n
t
(
n
−
g
r
a
m
′
)
Count(n-gram')
Count(n−gram′)表示n-gram’在candidate中的个数。
下图中的bleu应改为
P
r
e
c
i
s
i
o
n
i
Precision_i
Precisioni

Precision
BP(Brevity penalty 简短惩罚):惩罚简短的输出。

B l e u = B P × e 1 4 ∑ n = 1 4 P r e c i s i o n i Bleu=BP\times e^{\frac{1}{4}\sum_{n=1}^4Precision_i} Bleu=BP×e41∑n=14Precisioni
Bleu
越大越好。















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











