







神经网络基础
神经网络可以当做是能够拟合任意函数的黑盒子,只要训练数据足够,给定特定的x,就能得到希望的y,结构图如下:
将神经网络模型训练好之后,在输入层给定一个x,通过网络之后就能够在输出层得到特定的y
RNN
RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。首先我们要明确什么是序列数据,摘取百度百科词条:时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系
RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息
RNN之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。
为什么需要RNN(循环神经网络)
其他神经网络只能单独的取处理一个个的输入,前一个输入和后一个输入是完全没有关系的。但是,某些任务需要能够更好的处理序列的信息,即前面的输入和后面的输入是有关系的。
比如,当我们在理解一句话意思时,孤立的理解这句话的每个词是不够的,我们需要处理这些词连接起来的整个序列; 当我们处理视频的时候,我们也不能只单独的去分析每一帧,而要分析这些帧连接起来的整个序列。
我们先来看一个NLP很常见的问题,命名实体识别,举个例子,现在有两句话:
第一句话:I like eating apple!(我喜欢吃苹果!)
第二句话:The Apple is a great company!(苹果真是一家很棒的公司!)
现在的任务是要给apple打Label,我们都知道第一个apple是一种水果,第二个apple是苹果公司,假设我们现在有大量的已经标记好的数据以供训练模型,当我们使用全连接的神经网络时,我们做法是把apple这个单词的特征向量输入到我们的模型中(如下图),在输出结果时,让我们的label里,正确的label概率最大,来训练模型,但我们的语料库中,有的apple的label是水果,有的label是公司,这将导致,模型在训练的过程中,预测的准确程度,取决于训练集中哪个label多一些,这样的模型对于我们来说完全没有作用。问题就出在了我们没有结合上下文去训练模型,而是单独的在训练apple这个单词的label,这也是全连接神经网络模型所不能做到的,于是就有了我们的循环神经网络。
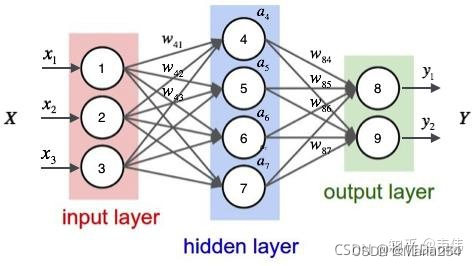
RNN结构
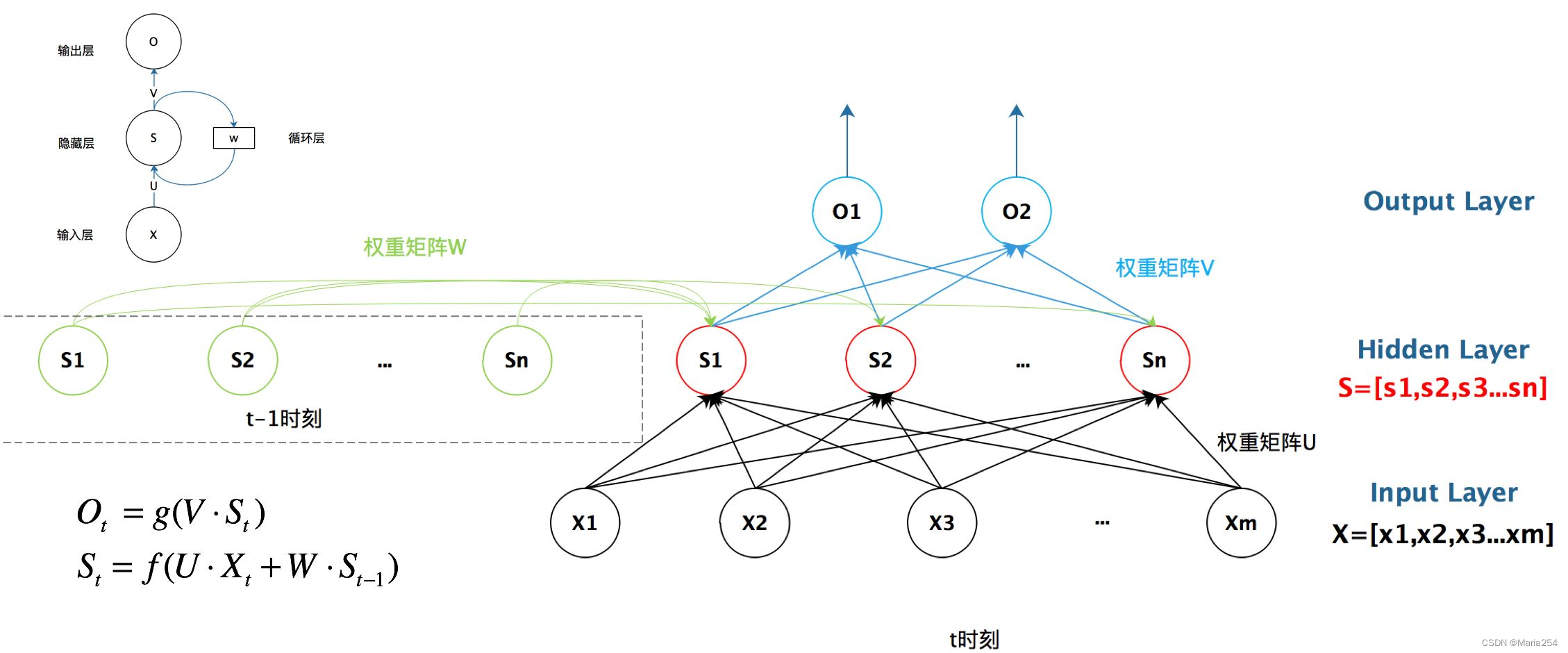
首先看一个简单的循环神经网络如,它由输入层、一个隐藏层和一个输出层组成:
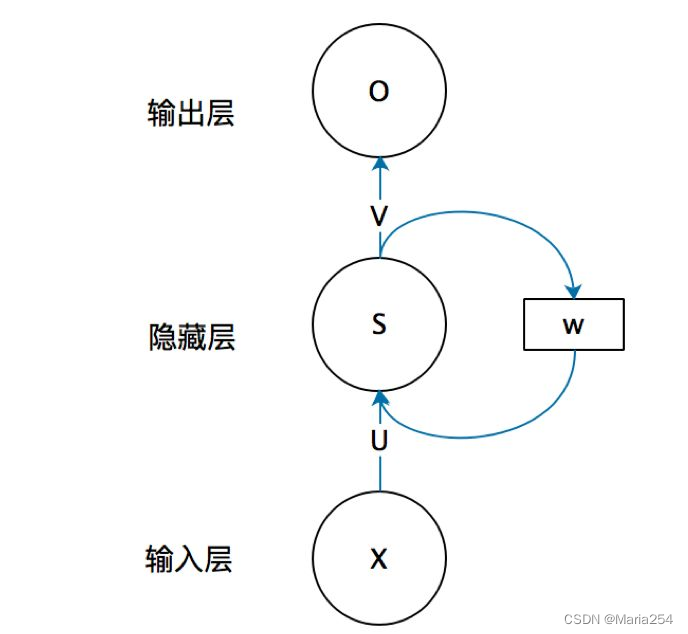
这样来理解,如果把上面有W的那个带箭头的圈去掉,它就变成了最普通的全连接神经网络。x是一个向量,它表示输入层的值(这里面没有画出来表示神经元节点的圆圈);s是一个向量,它表示隐藏层的值(这里隐藏层面画了一个节点,你也可以想象这一层其实是多个节点,节点数与向量s的维度相同);
U是输入层到隐藏层的权重矩阵,o也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。
那么,现在我们来看看W是什么。循环神经网络的隐藏层的值s不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
我们给出这个抽象图对应的具体图:
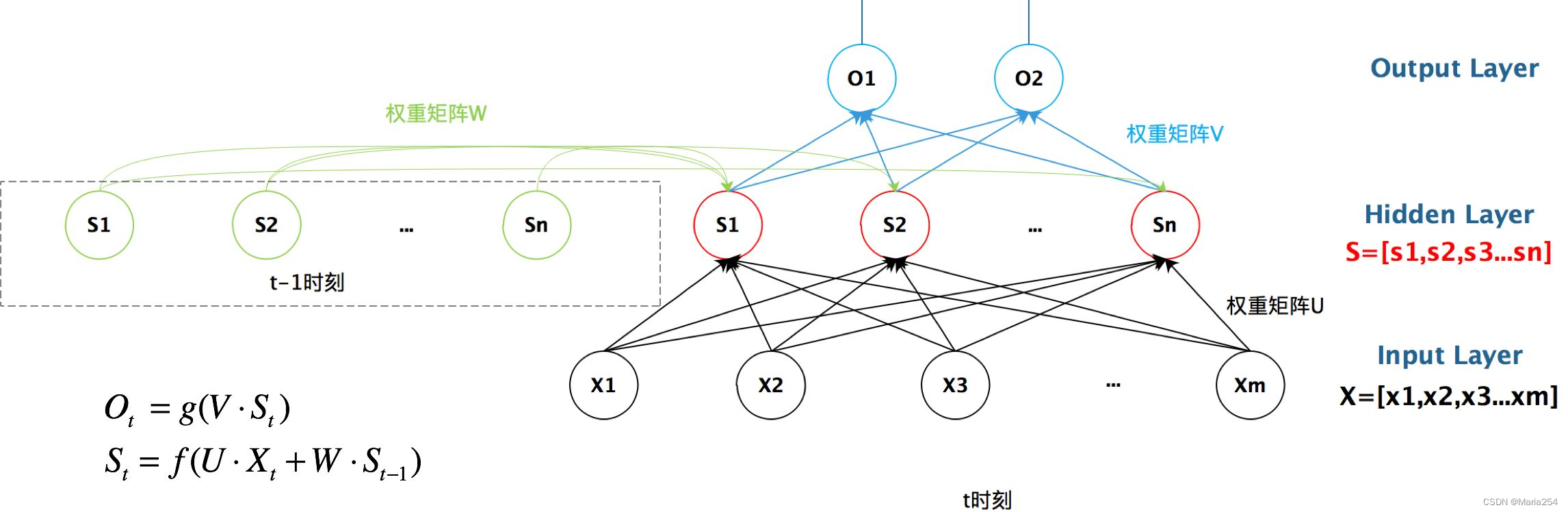
我们从上图就能够很清楚的看到,上一时刻的隐藏层是如何影响当前时刻的隐藏层的。
如果我们把上面的图展开,循环神经网络也可以画成下面这个样子:
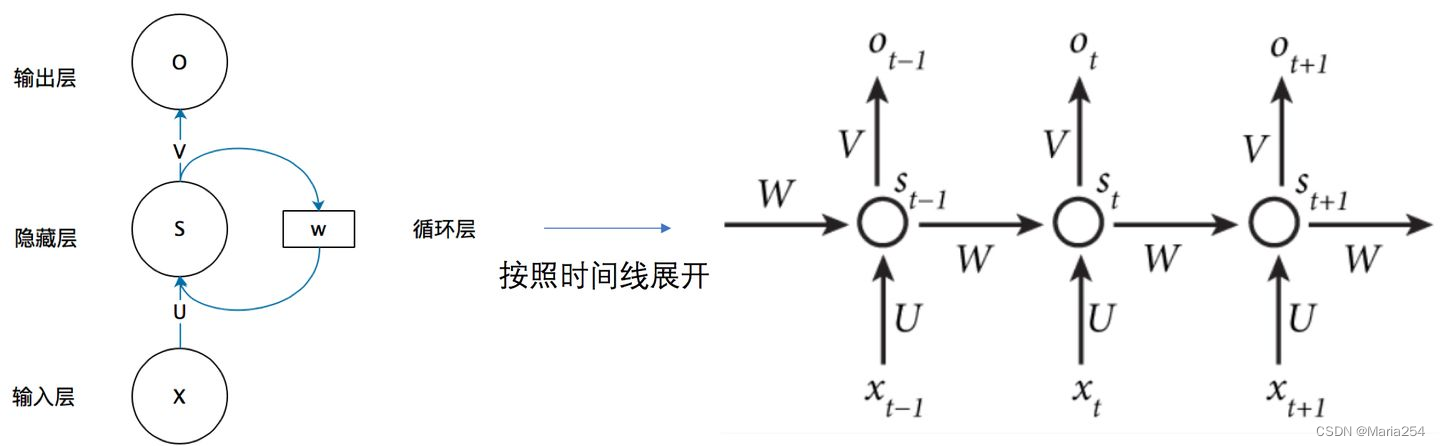 t-1, t, t+1表示时间序列. X表示输入的样本. St表示样本在时间t处的的记忆,St = f(WSt-1 +UXt). W表示输入的权重, U表示此刻输入的样本的权重, V表示输出的样本权重.
t-1, t, t+1表示时间序列. X表示输入的样本. St表示样本在时间t处的的记忆,St = f(WSt-1 +UXt). W表示输入的权重, U表示此刻输入的样本的权重, V表示输出的样本权重.
在t =1时刻, 一般初始化输入S0=0, 随机初始化W,U,V, 进行下面的公式计算:
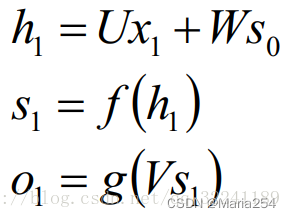
其中,f和g均为激活函数. 其中f可以是tanh,relu,sigmoid等激活函数,g通常是softmax也可以是其他。
时间就向前推进,此时的状态s1作为时刻1的记忆状态将参与下一个时刻的预测活动,也就是:
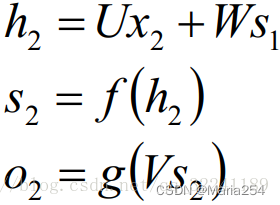
以此类推, 可以得到最终的输出值为:
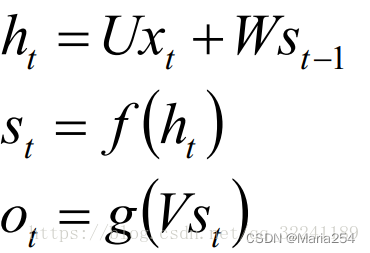
现在看上去就比较清楚了,这个网络在t时刻接收到输入 xt之后,隐藏层的值是st ,输出值是 ot。关键一点是, ot 的值不仅仅取决于xt ,还取决于 st-1 。我们可以用下面的公式来表示循环神经网络的计算方法:
用公式表示如下
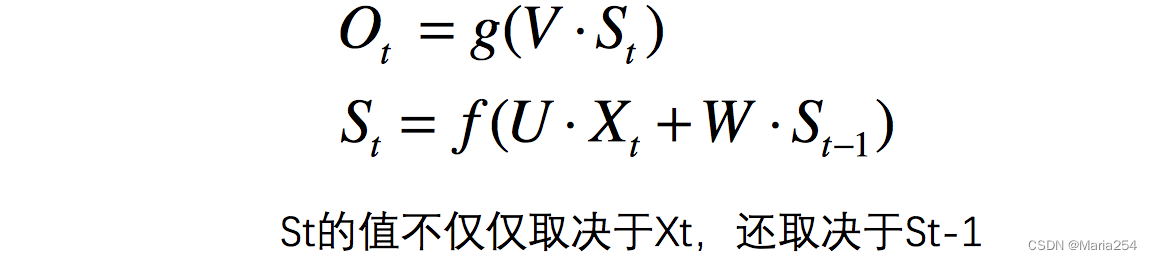
注1.这里的W,U,V在每个时刻都是相等的(权重共享).
2. 隐藏状态可以理解为: S=f(现有的输入+过去记忆总结)
最后给出RNN的总括图:
RNN的反向传播
前面我们介绍了RNN的前向传播的方式, 那么RNN的权重参数W,U,V都是怎么更新的呢?
每一次的输出值Ot都会产生一个误差值Et, 则总的误差可以表示为:.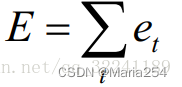
则损失函数可以使用交叉熵损失函数也可以使用平方误差损失函数.
由于每一步的输出不仅仅依赖当前步的网络,并且还需要前若干步网络的状态,那么这种BP改版的算法叫做Backpropagation Through Time(BPTT) , 也就是将输出端的误差值反向传递,运用梯度下降法进行更新
也就是要求参数的梯度:
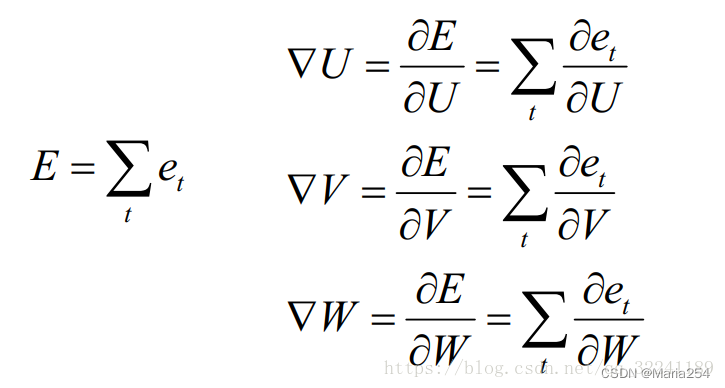
首先我们求解W的更新方法, 由前面的W的更新可以看出它是每个时刻的偏差的偏导数之和.
在这里我们以 t = 3时刻为例, 根据链式求导法则可以得到t = 3时刻的偏导数为: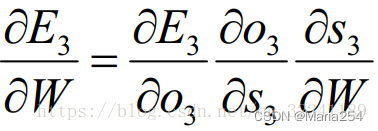
此时, 根据公式
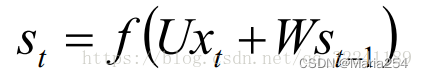
我们会发现, S3除了和W有关之外, 还和前一时刻S2有关.
对于S3直接展开得到下面的式子
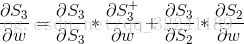
对于S2直接展开得到下面的式子:
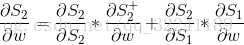
将上述三个式子合并得到:
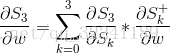
这样就得到了公式:
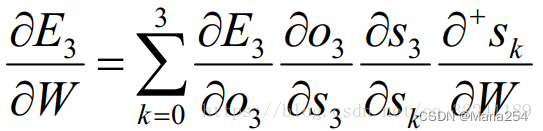
这里要说明的是: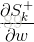
表示的是S3对W直接求导, 不考虑S2的影响.(也就是例如y = f(x)*g(x)对x求导一样)
其次是对U的更新方法. 由于参数U求解和W求解类似,这里就不在赘述了,最终得到的具体的公式如下:
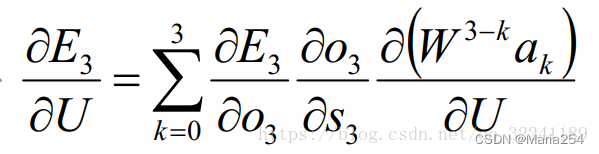
最后,给出V的更新公式(V只和输出O有关):
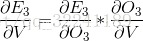















 190
190











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









