







一、决定下一步做什么
当我们运用训练好了的模型来预测未知数据的时候发现有较大的误差,我们下一步可以做什么呢?我们可以采取一些列措施来解决误差较大的问题,如:尝试减少特征的数量,尝试获得更多的特征,尝试增加多项式特征,尝试减少正则化程度 λ \lambda λ,尝试增加正则化程度 λ \lambda λ等,但不能盲目地选择这些方法,否则可能会事倍功半,接下来讨论“机器学习诊断法”,针对不同的情况我们应该采用不同的方式。
二、评估一个假设
评估一个假设模型的好坏,主要是讨论如何避免过拟合和欠拟合的问题。我们在确定假设函数参数的时候,不能认为得到非常小的训练误差是一件小事,因为较小的训练误差很可能是过拟合导致的,如果我们将这个假设模型应用到新的数据集中,显然会带来很大的误差。
对于参数少的假设函数,可以直接绘制假设函数
h
θ
h_{\theta }
hθ,观察图像趋势,但对于跟一般的情况,若含有较多的特征变量,进行画图是不取的,因此需要有另一种方法来判断假设函数是否过拟合。
采用将数据的70%作为训练集,30%作为测试集,注意的是在将数据分类时,一定要做到重新“洗牌”,即保证训练集和数据集中含有各种类型的数据。
我们用训练集的数据计算得到特征变量的值,之后对测试集运用这个模型,计算误差的方式有:
1.针对线性回归模型,利用测试集计算代价函数
J
(
θ
)
J(\theta)
J(θ);
2.针对逻辑回归模型,利用测试集计算代价函数:
J
t
e
s
t
(
θ
)
=
−
1
m
t
e
s
t
∑
i
=
1
m
t
e
s
t
l
o
g
h
θ
(
x
t
e
s
t
(
i
)
)
+
(
1
−
y
t
e
s
t
(
i
)
)
l
o
g
h
θ
(
x
t
e
s
t
(
i
)
)
J_{test}(\theta )=-\frac{1}{m_{test}}\sum_{i=1}^{m_{test}}logh_{\theta }(x_{test}^{(i)})+(1-y_{test}^{(i)})logh_{\theta }(x_{test}^{(i)})
Jtest(θ)=−mtest1i=1∑mtestloghθ(xtest(i))+(1−ytest(i))loghθ(xtest(i))
除此之外,针对逻辑回归模型还可以通过计算误分类比率的方法,对计算结果求平均:
e
r
r
(
h
θ
(
x
)
,
y
)
=
{
1
,
h
(
x
)
⩾
0.5
a
n
d
y
=
0
,
o
r
h
(
x
)
<
0.5
a
n
d
y
=
1
0
,
O
t
h
e
r
w
i
s
e
err(h_{\theta}(x),y)=\left\{\begin{matrix} 1,h(x)\geqslant 0.5\,\,and\,\,y=0,or\,h(x)<0.5\,and\,y=1\\ 0,\,\,Otherwise \end{matrix}\right.
err(hθ(x),y)={1,h(x)⩾0.5andy=0,orh(x)<0.5andy=10,Otherwise
三、模型选择和交叉验证集
针对一组训练集,10 个不同次数的二项式模型之间进行选择:
1.
h
θ
(
x
)
=
θ
0
+
θ
1
x
2.
h
θ
(
x
)
=
θ
0
+
θ
1
x
+
θ
2
x
2
3.
h
θ
(
x
)
=
θ
0
+
θ
1
x
+
⋅
⋅
⋅
+
θ
3
x
3
⋅
⋅
⋅
⋅
⋅
⋅
10.
h
θ
(
x
)
=
θ
0
+
θ
1
x
+
⋅
⋅
⋅
+
θ
10
x
10
\\1.h_{\theta }(x)=\theta _{0}+\theta _{1}x \\2.h_{\theta }(x)=\theta _{0}+\theta _{1}x+\theta _{2}x^{2} \\3.h_{\theta }(x)=\theta _{0}+\theta _{1}x+\cdot \cdot \cdot +\theta _{3}x^{3} \\\cdot \cdot \cdot \cdot \cdot \cdot \\10.h_{\theta }(x)=\theta _{0}+\theta _{1}x+\cdot \cdot \cdot +\theta _{10}x^{10}
1.hθ(x)=θ0+θ1x2.hθ(x)=θ0+θ1x+θ2x23.hθ(x)=θ0+θ1x+⋅⋅⋅+θ3x3⋅⋅⋅⋅⋅⋅10.hθ(x)=θ0+θ1x+⋅⋅⋅+θ10x10
显然,次数越高的模型能够很好的适应训练集的数据,但对测试集数据不能做到很好的适应,因此需要使用交叉验证集来帮助选择模型。
重新将数据进行分类:60%的训练集,20%的交叉验证集,20%的测试集。
模型选择的方法为:
1.使用训练集训练出 10 个模型
2.用 10 个模型分别对交叉验证集计算得出交叉验证误差(代价函数的值)
3.选取代价函数值最小的模型
4.用步骤 3 中选出的模型对测试集计算得出推广误差(代价函数的值)
用函数表示如下
训练集误差(Training error):
J
t
r
a
i
n
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
J_{train}(\theta )=\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta }(x^{(i)})-y^{(i)})^{2}
Jtrain(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
交叉验证机误差(Cross Validation error):
J
c
v
(
θ
)
=
1
2
m
c
v
∑
i
=
1
m
(
h
θ
(
x
c
v
(
i
)
)
−
y
c
v
(
i
)
)
2
J_{cv}(\theta )=\frac{1}{2m_{cv}}\sum_{i=1}^{m}(h_{\theta }(x_{cv}^{(i)})-y_{cv}^{(i)})^{2}
Jcv(θ)=2mcv1i=1∑m(hθ(xcv(i))−ycv(i))2
测试集误差(Test error):
J
t
e
s
t
(
θ
)
=
1
2
m
t
e
s
t
∑
i
=
1
m
t
e
s
t
(
h
θ
(
x
c
v
(
i
)
)
−
y
c
v
(
i
)
)
2
J_{test}(\theta )=\frac{1}{2m_{test}}\sum_{i=1}^{m_{test}}(h_{\theta }(x_{cv}^{(i)})-y_{cv}^{(i)})^{2}
Jtest(θ)=2mtest1i=1∑mtest(hθ(xcv(i))−ycv(i))2
四、诊断偏差和方差
如果计算出的模型并不能很好的符合预期,一般是出现两种情况:Ⅰ.偏差较大;Ⅱ.方差较大。偏差较大的情况表现为欠拟合,方差较大的情况表现为过拟合。
 如上图所示,上面三个模型分别表示对数据的欠拟合、正好拟合和过拟合,通常会通过将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来帮助分析,如下图所示。
如上图所示,上面三个模型分别表示对数据的欠拟合、正好拟合和过拟合,通常会通过将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来帮助分析,如下图所示。
 下面对上图进行分析,首先要明确x轴表示模型中最高项次数,y轴表示模型误差;
J
t
r
a
i
n
(
θ
)
J_{train}(\theta )
Jtrain(θ)表示训练集的代价函数,显而易见的是最高项次数越高,模型对训练集拟合的就越好,反应在代价函数中即为误差随
d
d
d的增大而减小;再来分析
J
c
v
(
θ
)
J_{cv}(\theta )
Jcv(θ)表示交叉验证集的代价函数,当
d
d
d较小时,模型拟合程度低,误差较大;但是随着
d
d
d的增长,误差呈现先减小后增大的趋势,转折点即模型开始过拟合训练数据集的时候。
下面对上图进行分析,首先要明确x轴表示模型中最高项次数,y轴表示模型误差;
J
t
r
a
i
n
(
θ
)
J_{train}(\theta )
Jtrain(θ)表示训练集的代价函数,显而易见的是最高项次数越高,模型对训练集拟合的就越好,反应在代价函数中即为误差随
d
d
d的增大而减小;再来分析
J
c
v
(
θ
)
J_{cv}(\theta )
Jcv(θ)表示交叉验证集的代价函数,当
d
d
d较小时,模型拟合程度低,误差较大;但是随着
d
d
d的增长,误差呈现先减小后增大的趋势,转折点即模型开始过拟合训练数据集的时候。
总结如下:
五、正则化和偏差\方差
在训练模型的时候,通常会使用正则化方法防止过拟合现象的发生,但是正则化参数
λ
\lambda
λ的大小也会对模型造成影响,同样也会造成欠拟合和过拟合,如下图所示。
 需要选定一系列想要测试的
λ
\lambda
λ值,通常是 0-10 之间的呈现 2 倍关系的值,如:0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10共12个,同样把数据分为训练集、交叉验证集和测试集。
需要选定一系列想要测试的
λ
\lambda
λ值,通常是 0-10 之间的呈现 2 倍关系的值,如:0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10共12个,同样把数据分为训练集、交叉验证集和测试集。
假定模型:
h
θ
(
x
)
=
θ
0
+
θ
1
x
+
θ
3
x
3
+
θ
4
x
4
h_{\theta }(x)=\theta _{0}+\theta _{1}x+\theta _{3}x^{3}+\theta _{4}x^{4}
hθ(x)=θ0+θ1x+θ3x3+θ4x4
代价函数:
J
(
θ
)
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
2
+
λ
2
m
∑
j
=
1
m
θ
j
2
J(\theta )=\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta }(x^{(i)})-y^{(i)})^{2}+\frac{\lambda }{2m}\sum_{j=1}^{m}\theta _{j}^{2}
J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2+2mλj=1∑mθj2
选择
λ
\lambda
λ的方法为:
1.选用不同的
λ
\lambda
λ的值,使用训练集训练出 12 个不同程度正则化的模型
2.用 12 个模型分别对交叉验证集计算的出交叉验证误差
3.选择得出交叉验证误差最小的模型
4.运用步骤 3 中选出模型对测试集计算得出推广误差,我们也可以同时将训练集和交叉验证集模型的代价函数误差与 λ 的值绘制在一张图表上。
 得出结论:
得出结论:
六、学习曲线
学习曲线是学习算法的一个很好的合理检验( sanity check)。学习曲线是将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数绘制的图表。
先上结论:
当训练较少行数据的时候,训练的模型将能够非常完美地适应较少的训练数据,但是训练出来的模型却不能很好地适应交叉验证集数据或测试集数据。
如何利用学习曲线识别高偏差/欠拟合:作为例子,尝试用一条直线来适应下面的数据,可以看出,无论训练集有多么大误差都不会有太大改观:
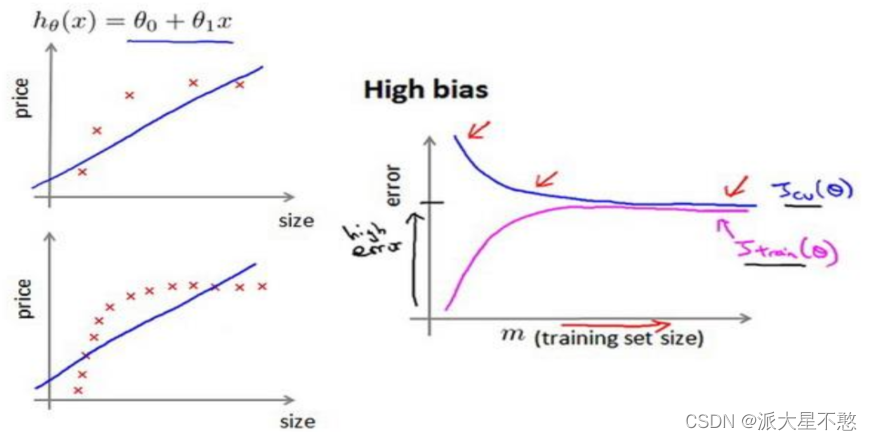
七、决定下一步做什么
1.获得更多的训练实例——解决高方差
2 尝试减少特征的数量——解决高方差
3.尝试获得更多的特征——解决高偏差
4.尝试增加多项式特征——解决高偏差
5.尝试减少正则化程度
λ
\lambda
λ ——解决高偏差
6.尝试增加正则化程度
λ
\lambda
λ ——解决高方差
针对神经网络的偏差,之后再补充,有点没学明白不好表复述。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









