







文章目录
本文记录用python机器学习实现对基于TCP协议的DDOS攻击的流量监测。基本原理是假设将流量包分组,每100个流量包为一组,用一些反应每组流量包整体特征的数据作为依据,判断抓取这组流量包时主机是否遭遇了DDOS攻击。以下是学习的详细记录。
一、Wireshark抓包工具使用以及数据包分析
wireshark可以分析导入的日志记录,也可以实时监控本地接口。其基本使用方法有数据包筛选、数据包搜索、数据包分析等。由于此时使用的是WIFI,故选用WLAN接口。
1.数据包筛选
在显示过滤器中输入以下规则的字符串可以进行数据筛选。
①目的ip筛选:ip.dst = = ip地址
②mac地址筛选:
目标mac地址筛选: eth.dst = =A0:00:00:04:C5:84 ;
mac地址筛选: eth.addr= =A0:00:00:04:C5:84
③端口筛选:
筛选tcp协议的目标端口为80 的流量包:tcp.dstport = = 80
筛选tcp协议的源端口为80 的流量包:tcp.srcport = = 80
筛选udp协议的源端口为80 的流量包:udp.srcport = = 80
④协议筛选:
筛选协议为tcp的流量包:tcp
筛选协议为udp的流量包:udp
筛选协议为arp/icmp/http/ftp/dns/ip的流量包:arp/icmp/http/ftp/dns/ip
⑤包长度筛选:
筛选长度为20的udp流量包:udp.length = =20
筛选长度大于20的tcp流量包:tcp.len >=20
筛选长度为20的IP流量包:ip.len = =20
筛选长度为20的整个流量包:frame.len = =20
⑥http请求筛选:
筛选HTTP请求方法为GET的流量包:http.request.method==“GET”
筛选HTTP请求方法为POST的流量包:http.request.method==“POST”
筛选URL为/img/logo-edu.gif的流量包:http.request.uri==“/img/logo-edu.gif”
筛选HTTP内容为FLAG的流量包:http contains “FLAG”
2.数据包搜索
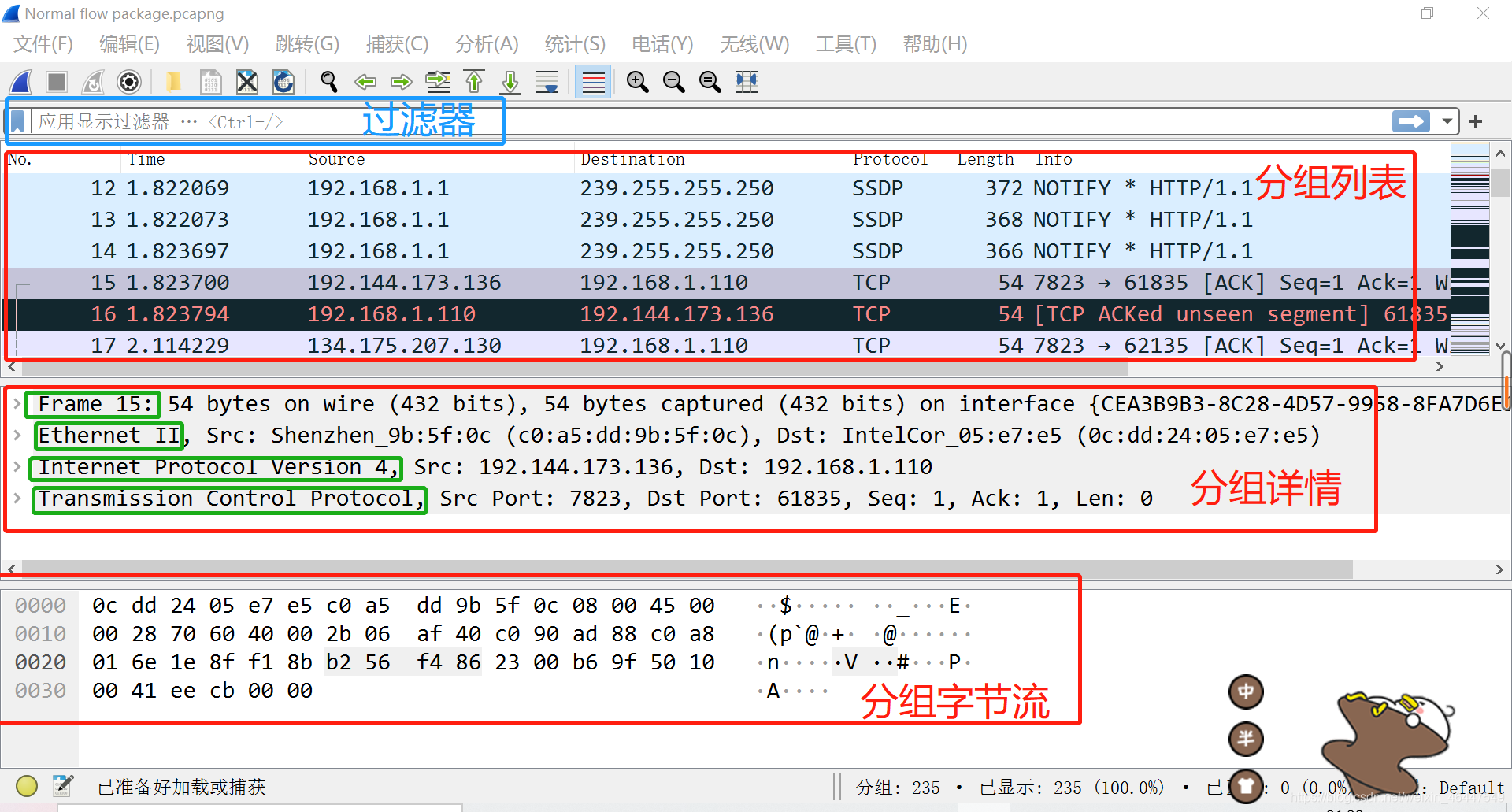
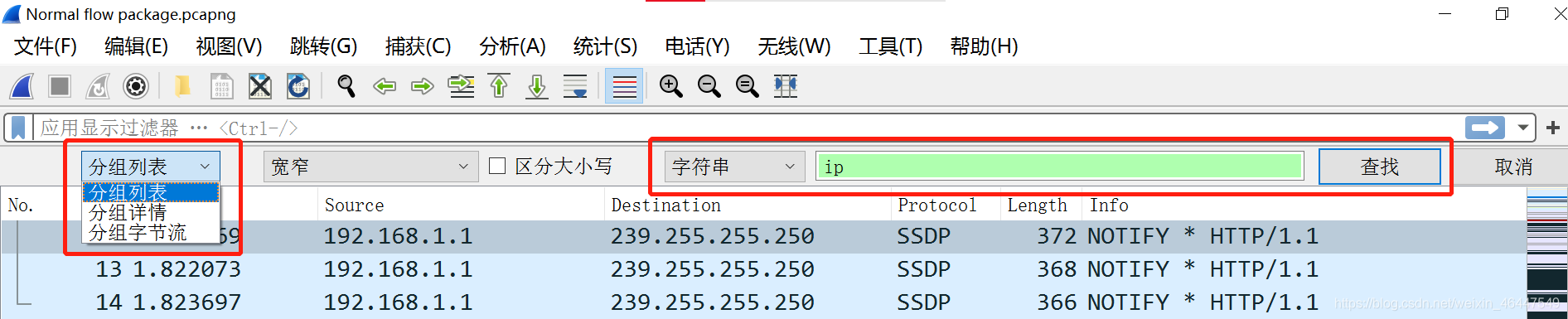
在wireshark界面按“Ctrl+F”,可以进行关键字搜索。搜索栏的左边下拉,有分组列表、分组详情、分组字节流三个选项,分别对应wireshark界面的三个部分,搜索时选择不同的选项以指定搜索区域。
3.数据包分析
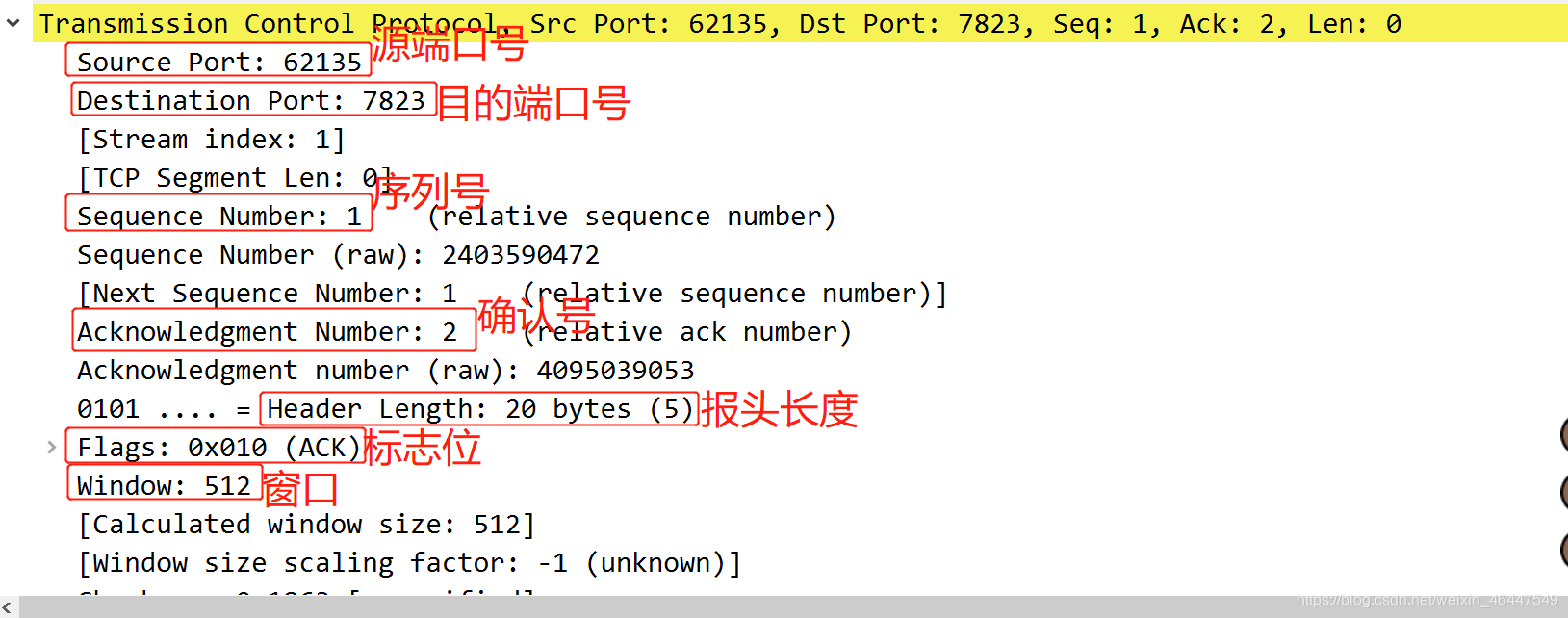
在分组详情一栏中我们可以查看数据包的每一个字段,一般从上至下每行分别为物理层、数据链路层、IP层、运输层、应用层协议的字段。
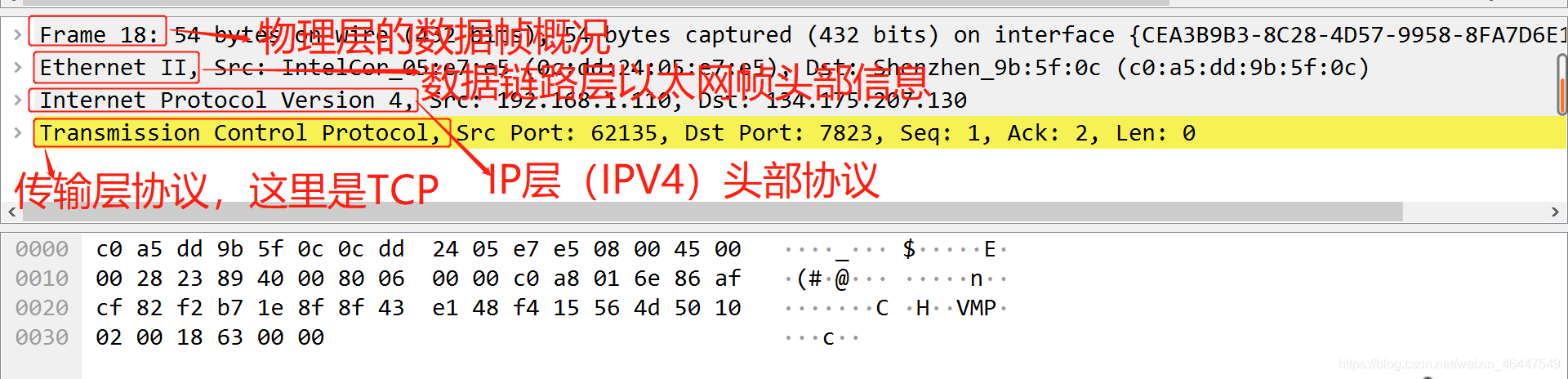
点开每层协议可以看到数据包中的具体字段,以下面的tcp包为例:
二、使用python库进行流量特征提取
1.下载scapy库
打开cmd输入命令pip install scapy即可。
由于代码中需要用到datetime库读取抓取时间,故用同样方法下载datetime库
2.scapy库的使用
【注意:scapy模块必须使用 from scapy.all import * 才能正确调用。】
①读出文件流量包中的全部数据:
#引入库
from scapy.all import rdpcap
#调用库函数读取数据
packets = rdpcap('Normal flow package.pcapng')
#数据输出(.mysummary让数据易读)
for data in packets:
print(data.mysummary)
因为数据过多运行结果不再全部展示,此处截取前三条,可以发现:每条记录都是由数据链路层协议(Ether)、网络层协议(IP)、运输层协议(如UDP)、网络层数据组成。

②读pcap中的某个包。当scapy读入pcap文件时,实则是读入一个列表。因为pcap文件中包含了很多个数据包,所以读进来的packets代表所有pcap包中包含的数据,而packets[i]表示在pcap中的第i条数据。
③读每条数据包的具体格式,可通过show()函数进行结构的展示。
④提取每条数据包中具体网络属性的值,利用如下代码即可访问。
pkts[ i ] [ 对应的协议].属性名称
例如以下代码:
#引入库
from scapy.all import rdpcap
#调用库函数读取数据
a = rdpcap('Normal flow package.pcapng')
#显示第一条记录的数据包结构
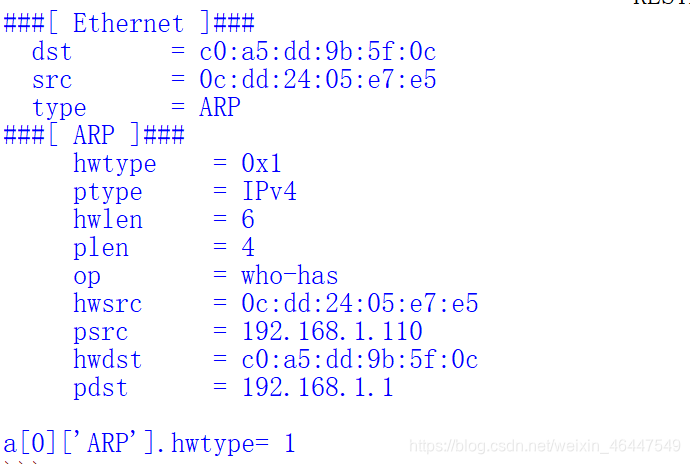
a[0].show()
#输出第一条记录的ip层arp协议的hwtype字段
print("a[0]['ARP'].hwtype=",a[0]['ARP'].hwtype)
运行结果如下:
3.csv库的使用(数据写入.csv文件)
①CSV即逗号分隔值(Comma-Separated Values),有时也称为字符分隔值,因为分隔字符也可以不是逗号,其文件以纯文本形式存储表格数据(数字和文本)。纯文本意味着该文件是一个字符序列,不含必须像二进制数字那样被解读的数据。
②CSV文件由任意数目的记录组成,记录间以某种换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。通常都是纯文本文件。建议使用WORDPAD或是记事本来开启,再则先另存新档后用EXCEL开启,也是方法之一。
③CSV文件的写入和读取均可用字典或列表的形式,具体要看数据在python文件中的保存形式,以下例子中假设data1为列表的列表,data2为字典的列表。
(1)列表写入:
#表头(列表)
head1 = ["姓名","年龄","分数"]
#数据(列表的列表,列表的一个元素是一行)
data1 =[["李四",23,90],
["刘二麻子",13,20]]
#创建写入器对象
with open("text.csv","w",encoding="utf-8") as f:
#调用csv库
writer = csv.writer(f)
#写入标题,写入单行用writerow()
writer.writerow(head1)
#写入数据,写入多行用writerows()
writer.writerows(data1)
(2)字典写入:
#表头和数据
head2 = ["姓名", "年龄", "分数"]
data2 =[{
"姓名":"李四","年龄":23,"分数":90},
{
"姓名":"王五","年龄":19,"分数":100},
{
"姓名":"刘二麻子","年龄":13,"分数":20}]
#创建写入器对象
with open("text2.csv","w",encoding 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









