







论文出处:https://dl.acm.org/doi/abs/10.1145/3442381.3450051
Authors: Letian Zhang, Lixing Chen, Jie Xu // University of Miami
Abstract:
- partition a deep neural network (DNN) into a front-end part running on the mobile device and a backend part running on the edge server, with the key challenge being how to locate the optimal partition point to minimize the end-to-end inference delay.
- automatically learn the optimal partition point on-the-fly, closely follow the changes of the system environment by generating new knowledge for adaptive decision making.
1. Introduction:
- mobile device: computing resource limitation
- MEC: the performance is sensitive to bandwidth (collaborative inference rather than 0-1 offloading)→balance the transmission and computation workload
1.1 Numerical Insights
the computing capability of the edge server and the network condition critically affect the collaborative deep inference performance.
① VGG16 is partitioned at different layers: delay histogram
② delay at different partition points under different edge capabilities
③ delay at different partition points under different network conditions
1.2 Why Online Learning?
There are several drawbacks of those existing offline profiling approaches.
① Adaptation to New Environments
② Limited Feedback
③ Layer Dependency: laborioous profiling for very deep layers, neglects the interdependency between layers.
1.3 Contribution
selects, for each frame (or a small batch of video frames), a partition point to perform collaborative deep inference for object detection with the edge server.
① avoids the large overhead incurred in the laborious offline profiling stage.
② provides differentiated service to key frames
③ a novel online learning under the contextual bandit frame work.
2. System Architecture
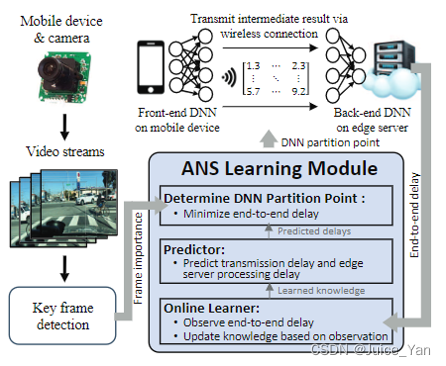
2.1 DNN Partition
Marking Partition Points
Total Inference Delay
2.2 Edge Offloading Delay Prediction
Constructed Contextual Features of Partitions
Linear Prediction Model 对应算法Lin-UCB
2.3 Object Detection in Video Stream——Key Frames (SSIM)
对于连续帧图片,相似度高的图片用来exploration, 相似度低的图片用来exploitation.

3. Autodidactic Neurosurgeon(Algorithm)
3.1 LinUCB and its Limitation
① LinUCB treats each frame equally for the learning purpose without considering the key frame.
② for cut point = 0 or P , the reward does not satisfy the linear prediction model. contextual feature = 0 , being trapped in pure on-device processing
3.2 μLinUCB
① each frame is assigned with a weight depending on whether it is a key frame or not (or the likelihood of being a key frame)
② add randomness in partition point selection: forced sampling
Theoretical Performance Guarantee
Handling Unknown: μLinUCB starts with a large frequency of forced sampling and gradually reduces the frequency as more video frames have been analyzed.
Complexity Analysis
4. Experiment Results
4.1 Implemenntation and Setup
① Testbed ②DL Models and Platforms ③ Video Input and Detection Output ④Benchmark( Oracle/ Pure Edge Offloading/ Pure On-device Processing/ NeuroSurgeon)















 4880
4880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









