









ElasticSearch–全文检索(一)
为什么要用ElasticSearch?它可以解决什么问题?
https://www.elastic.co/cn/elasticsearch/
先讲一下什么是Elasticsearch。
简单说,Elasticsearch 就是一个分布式的搜索与分析引擎。
Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
Elasticsearch 也适用Java开发并使用Lucene作为其核心来实现所有索引和搜索功能,但是它的目的是通过简单的RESTFUL API来隐藏Lucene的复杂性,从而让全文搜索变的简单。
https://www.elastic.co/cn/elasticsearch/features

查询和分析

速度

可扩展性

相关度

弹性

特点和优势:
- 分布式实时文件存储,可将每个字段存入索引,使其可以被检索到。
- 近乎实时分析的分布式搜索引擎
- 分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作。
- 负载再平衡和路由在大多数情况下自动完成
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。也可以运行在单台PC上。
- 支持插件机制,分词插件、同步插件、Hadoop插件、可视化插件等。
用数据库,也可以实现搜索的功能,为什么还需要搜索引擎呢?
就像 Stackoverflow 的网友说的:
A relational database can store data and also index it. A search engine can index data but also store it.
数据库(理论上来讲,ES 也是数据库,这里的数据库,指的是关系型数据库),首先是存储,搜索只是顺便提供的功能,
而搜索引擎,首先是搜索,但是不把数据存下来就搜不了,所以只好存一存。
术业有专攻,专攻搜索的搜索引擎,自然会提供更强大的搜索能力。
1、精确匹配和相关性匹配
在使用数据库搜索时,我们更多的是基于「精确匹配」的搜索。
什么是「精确匹配」?
比如搜订单,根据订单状态,准确搜索。搜「已完成」,就要「精确匹配」「已完成」的订单,搜「待支付」,就要「精确匹配」「待支付」的订单。
这种「精确匹配」的搜索能力,传统关系型数据库是非常胜任的。
和「精确匹配」相比,「相关性匹配」更贴近人的思维方式。
比如我要搜一门讲过「莎士比亚」的课程,我需要在课程的文稿里进行「相关性匹配」,找到对应的文稿,
你可能觉得一条 sql 语句就可以解决这个问题:
select * from course where content like "%莎士比亚%"
然而,这只能算是「模糊查询」,用你要搜索的字符串,去「精确」的「模糊查询」,其实还是「精确匹配」,机械思维。
那么到底什么是「相关性匹配」,什么才是「人的思维」呢?
比如我搜「莎士比亚」,我要的肯定不只是精精确确包含「莎士比亚」的文稿,我可能还要搜「莎翁」、「Shakespeare」、「哈姆雷特」、「罗密欧和朱丽叶」、「威尼斯的商人」…
又比如我输错了,输成「莎士笔亚」,「相关性匹配」可以智能的帮我优化为「莎士比亚」,返回对应的搜索结果。
这就是搜索引擎的强大之处,它似乎可以理解你的真实意图。
2、搜索和分析,不只是搜索,还有分析
“search and analytics engine”,ES 不仅是搜索,还有分析。
原始数据如果只是躺在磁盘里面根本就毫无用处。 —— 《Elasticsearch 权威指南》
躺在磁盘里的数据是没有价值的,而ES则让你存放在里面的数据,拥有了无限的探索力。
Elasticsearch 真正强大之处在于可以从无规律的数据中找出有意义的信息 —— 从“大数据”到“大信息”。 —— 《Elasticsearch 权威指南》
和 mysql 一样,ES 提供了一些简单的聚合操作,avg、sum、min、max等等。
当然,实际的业务场景,很多是无法通过这些聚合操作就能分析出想要的数据的,复杂的处理逻辑,还是要通过写业务代码来实现。
实时计算的一种常见方案,是数据产生后,通过消息队列(比如kafka)推给实时计算平台 storm,计算后,再把数据存到 ES。
貌似es在这里没有提供什么分析能力,然而只要数据存在于es,这些数据的被探索力就比放在数据库里的强,你随时可以在里面挖掘出商机。
令我最为震惊的是,他们竟然不看表面数据,而是从无限数据的机会中寻找核心数据。 这正体现了大数据与传统数据之间最大的不同。以前,我们是“有问题找数据”,而在大数据时代,其最核心的特质则是“用数据找机会” —— 《决战大数据》车品觉
这一切的分析数据的能力,都是建立在快速的查询上的,如果没有快速的查询,分析能力无从谈起。
基础概念

index(索引)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库。
动词,相当于MySQL中的insert。
名词,相当于MySQL中的DataBase。
Type(类型)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。类比传统的关系型数据库领域来说,类型相当于“表”。
在Index(索引)中,可以定义一个或多个类型。
类似于MySQL中的 Table ,每一种类型的数据放在一起。
特别注意的是,根据官网信息:在Elasticsearch 6.0.0或更高版本中创建的索引只能包含一个映射类型。在5.x中创建的具有多种映射类型的索引将继续像在Elasticsearch 6.x中一样工作。类型将在Elasticsearch 7.0.0中的API中弃用,并在8.0.0中完全删除。
Document(文档)
保存在某个索引(index)下,某种类型(Type)的一个数据(Document),文档是JSON 格式的,Docunment 就像是MySQL中的某个 Table 里面的内容。
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。相当于mysql表中的row。
映射(Mapping)
映射是定义文档及其包含的字段如何存储和索引的过程。
例如,使用映射来定义:
- 哪些字符串字段应该被视为全文字段。
- 哪些字段包含数字、日期或地理位置。
- 文档中所有字段的值是否应该被索引到catch-all _all字段中。
- 日期值的格式。用于控制动态添加字段的映射的自定义规则。
每个索引都有一个映射类型,它决定了文档的索引方式。
与 mysql 的对比

REST请求头

倒排索引机制

环境部署
Elasticsearch
Elasticsearch - Official Image | Docker Hub
docker pull elasticsearch:7.17.3

#进行挂载
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
#配置外部访问
echo "http.host:0.0.0.0">>/mydata/elasticsearch/config/elasticsearch.yml

启动容器:
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.17.3
以后在外面装好插件重启即可。
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" 测试环境下,设置es的初始内存和最大内存,否则导致过大启动不了ES。

出现的小插曲:

看了日志,问题不大。

中间应该是空格。
sudo docker start elasticsearch
sudo docker ps
又出幺蛾子。

也就是说这个目录没有读写权限。
chmod 777 /mydata/elasticsearch/**
docker start elasticsearch
docker ps



Kibana
Kibana - Official Image | Docker Hub 可视化的


docker pull kibana:7.17.3


#进行挂载
mkdir -p /mydata/kibana/config/
#配置
vim /mydata/kibana/config/kibana.yml
#
# ** THIS IS AN AUTO-GENERATED FILE **
# 根据自己的IP地址来配
#
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://192.168.31.190:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
#启动
docker run -d \
--name=kibana \
--restart=always \
-p 5601:5601 \
-v /mydata/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
kibana:7.17.3
#查看日志
docker logs kibana

如果跟着雷丰阳老师没有做出来,可以移除kibana的容器和镜像。
可以参考:Docker 如何删除及清理镜像_huayang183的博客-CSDN博客_删除镜像
至此,已经全部安装成功。
初步检索
_cat
# 查看所有的节点
get /_cat/nodes
# 查看es的健康状况
get /_cat/health
# 查看注解点
get /_cat/master
# 查看所有的索引
get /_cat/indices show databases;
索引一个文档(保存)
保存一个数据,保存在那个索引的那个的类型下,制定用那个唯一标识
#在customer下的external类型下保存1号数据
put customer/external/1
{
"name":"uin"
}

put请求是新增和更新操作二合一。PUT请求必须带id,也就是唯一标识符。

POST请求也是新增操作,可以带id,也可以不带id。

查询文档(查询)
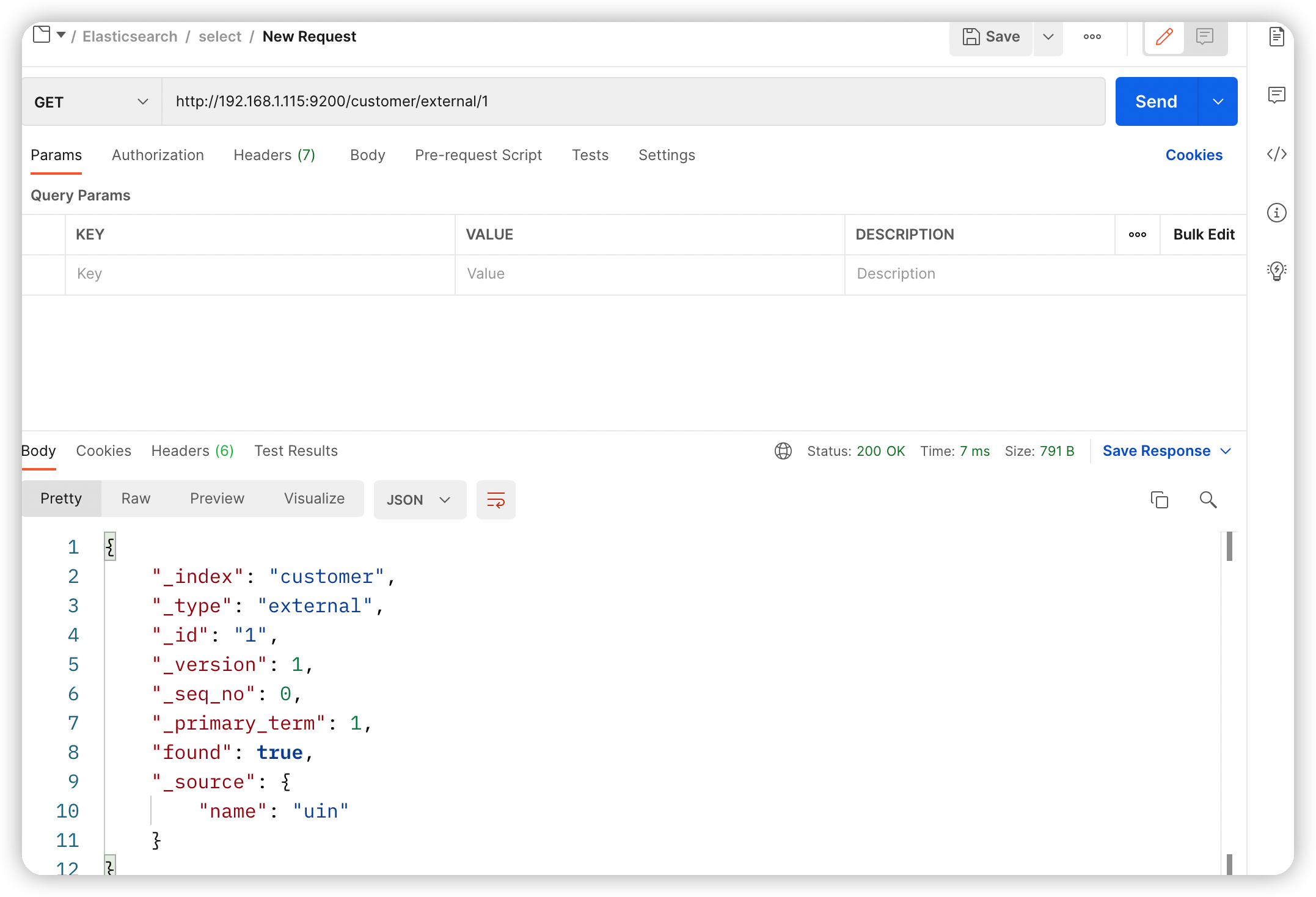
get customer/external/1
{
"_index": "customer",//在哪个索引上
"_type": "external",//在那个类型上
"_id": "1",//唯一标识符
"_version": 1,//版本号
"_seq_no": 0, //乐观锁 并发控制手段,每次更新加一,用来做版本控制
"_primary_term": 1, //分片
"found": true,
"_source": {
"name": "uin"
}
}
实现并发控制:乐观锁修改操作
PUT http://192.168.1.115:9200/customer/external/1?if_seq_no=0&if_primary_term=1
更新文档
POST customer/external/1
or
PUT customer/external/1
{
"_index": "customer",
"_type": "external",
"_id": "1",
"_version": 5,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 9,
"_primary_term": 1
}


put请求可以不带doc。
删除文档
DELETE customer/external/1
DELETE customer

bulk批量API
POST customer/external/_bulk
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"My first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"My second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"My update blog post"}}
POST customer/external/_bulk
{"index":{"_id":"1"}}
{"name":"ui1n"}
{"index":{"_id":"2"}}
{"name":"bearbrick0"}
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"My first blog post"}
{"index":{"_index":"website","_type":"blog"}}
{"title":"My second blog post"}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"My update blog post"}}
POST /bank/account/_bulk
https://gitee.com/xlh_blog/common_content/blob/master/es%E6%B5%8B%E8%AF%95%E6%95%B0%E6%8D%AE.json#















 706
706











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









