






YOLOV3
网络结构照比YOLOV2改进:
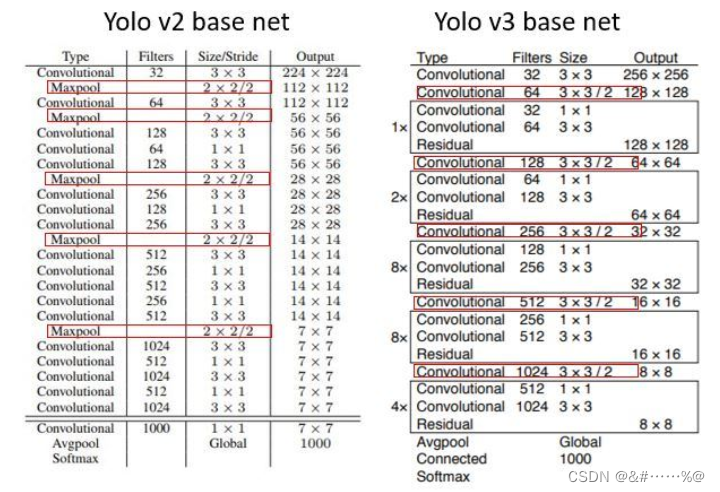
Darknet-19 升级为Darknet-53
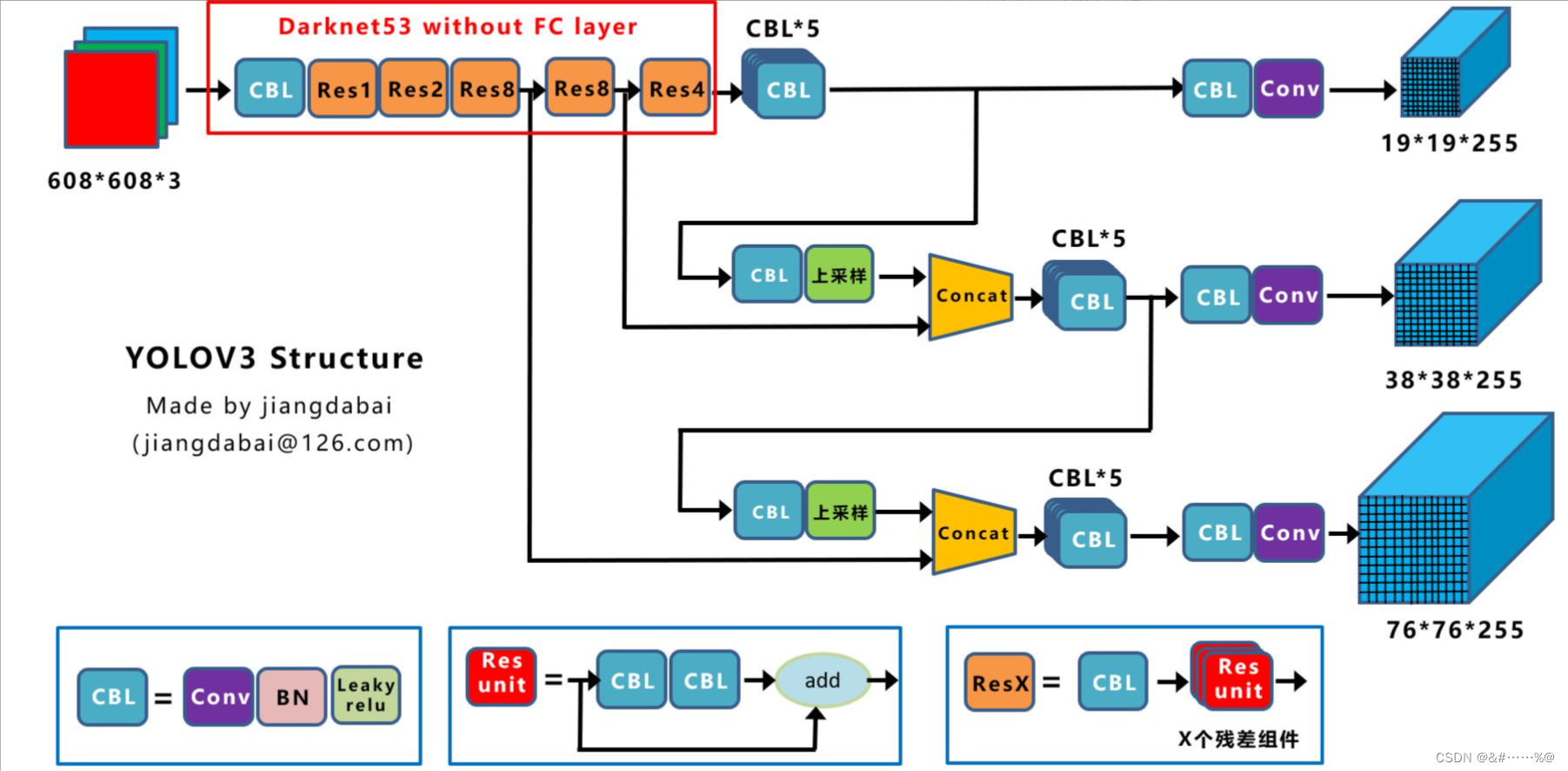
CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
整个v3结构里面,是没有池化层和全连接层的。前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现的,比如stride=(2, 2),这就等于将图像边长缩小了一半(即面积缩小到原来的1/4)。在yolo_v2中,要经历5次缩小,会将特征图缩小到原输入尺寸的1 / 2 5 1/2^51/2
5,即1/32。输入为416x416,则输出为13x13(416/32=13)。
YOLOV3预测
借鉴了FPN,不同于之前的SSD多级检测的是,YOLOV3对深层网络输出的特征图使用上采样操作,然后与浅层网络进行融合,使得来自于不同尺度的细节信息和语义信息得到了有效的融合。
在每个特征图上,YOLOv3在每个网格处放置3个先验框。由于YOLOv3一共使用3个尺度,因此,YOLOv3一共设定了9个先验框,这9个先验框仍旧是使用kmeans聚类的方法获得的。在COCO上,这9个先验框的宽高分别是(10, 13)、(16, 30)、(33, 23)、(30, 61)、(62, 45)、(59, 119)、(116, 90)、(156, 198)、(373, 326)。注意,YOLOv3的先验框尺寸不同于YOLOv2,后者是除以了32,而前者是在原图尺寸上获得的,没有除以32。每个尺度的网格都放置3个先验框,且每个先验框的预测仍旧是包括置信度、类别和位置参数(换言之,输出共包括objectness+class+bbox三部分输出),因此,每个尺度所预测的张量的通道数都是3×(1+C+4)。以416的输入尺寸为例,YOLOv3最终会输出52×52×3(1+C+4)、26×26×3(1+C+4)和13×13×3(1+C+4)三个预测张量,然后将这些预测结果汇总到一起,进行后处理,得到最终的检测结果。
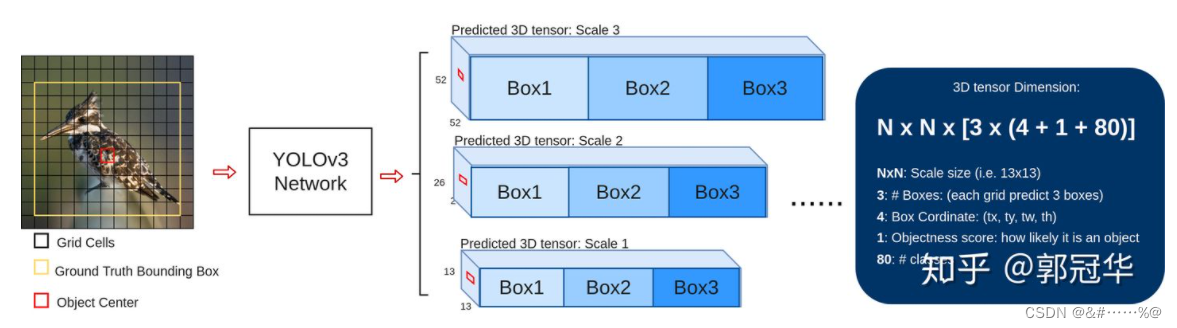
在训练过程中对于每幅输入图像,YOLOv3会预测三个不同大小的3D tensor,对应着三个不同的scale。设计这三个scale的目的就是为了能够检测出不同大小的物体。在这里我们以13x13的tensor为例做一个简单讲解。对于这个scale,原始输入图像会被分成分割成13x13的grid cell,每个grid cell对应着3D tensor中的1x1x255这样一个长条形voxel。255这个数字来源于(3x(4+1+80)),其中的数字代表bounding box的坐标,物体识别度(objectness score),以及相对应的每个class的confidence















 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









