







Emerging Architectures for LLM Applications
一篇文章,聊聊怎么基于LLM构建应用:Emerging Architectures for LLM Applications | Andreessen Horowitz (a16z.com)
一般来讲,有三种方式来基于LLM来构建应用:
- 基于api来进行构建,就是类似于传统构建应用的方式
- 基于GitHub开源项目来构建
- 基于快速构建工具,例如Vercel AI SDK,直接提供一整套,从api、服务器计算资源、基础软件模板资源来进行构建
所以说,想基于LLM api快速构建出一个类似于聊天机器人等应用已经变得非常简单,但这毕竟是玩具应用,并不能支撑正式的消费级的应用场景。
所以说,这篇文章并不是告诉你怎么构建简单的LLM应用,而是如何构建出正式场景中的LLM应用
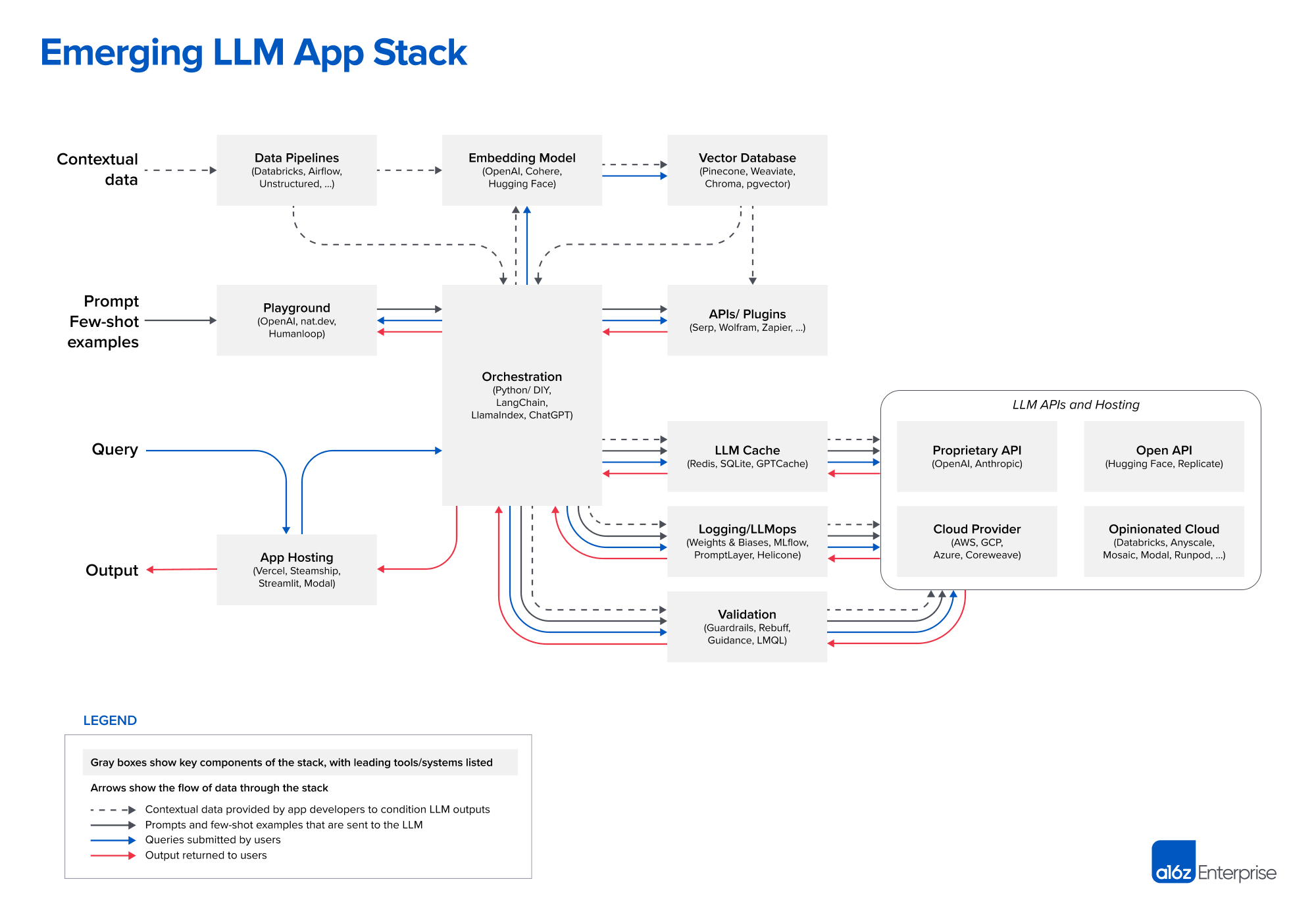
LLM应用中的技术选型
| Data pipelines | Embedding model | Vector database | Playground | Orchestration | APIs/plugins | LLM cache |
|---|---|---|---|---|---|---|
| Databricks | OpenAI | Pinecone | OpenAI | Langchain | Serp | Redis |
| Airflow | Cohere | Weaviate | nat.dev | LlamaIndex | Wolfram | SQLite |
| Unstructured | Hugging Face | ChromaDB | Humanloop | ChatGPT | Zapier | GPTCache |
| pgvector |
| Logging / LLMops | Validation | App hosting | LLM APIs (proprietary) | LLM APIs (open) | Cloud providers | Opinionated clouds |
|---|---|---|---|---|---|---|
| Weights & Biases | Guardrails | Vercel | OpenAI | Hugging Face | AWS | Databricks |
| MLflow | Rebuff | Steamship | Anthropic | Replicate | GCP | Anyscale |
| PromptLayer | Microsoft Guidance | Streamlit | Azure | Mosaic | ||
| Helicone | LMQL | Modal | CoreWeave | Modal | ||
| RunPod |
设计模式之 In-context learning
该模式的核心是通过prompt和训练数据来控制LLM的输出
例如:设计一个通晓美国法律的聊天机器人,让它能回答与美国法律相关的问题。
我们没办法将好几本书的内容加上prompt输入给LLM,因为这会超过LLM输入限制的Token数,也会导致LLM推理的时间和效率下降,LLM也不需要好几本书的上下文,它只需要能解决你的问题的上下文
就像你有一个问题,你想解决这个问题就去看书,你没必要看完整本书,你只需要翻书到对应的章节,阅读对应章节的部分,就可以解决你的问题,LLM回答某个专业领域的问题的思考逻辑也是这样
为什么使用向量数据库:因为数据相关性搜索其实是向量运算
为什么使用embedding:相比 fine-tuning 最大的优势就是,不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次,并且各方面成本要比 fine-tuning 低很多。
LLM回答问题的流程分为三个阶段:
- data embedding:将专业数据通过嵌入模型转换成向量,存储到向量数据库中
- 提示构造和检索:当用户提交查询时,应用程序会构造prompt,包括:提示模板、few-shots、从向量数据库中检索到的相关文档等
- 执行prompt:将prompt提交给LLM api或者自训练模型(这个过程还可以包括日志记录、缓存和验证等部分)
Data embedding
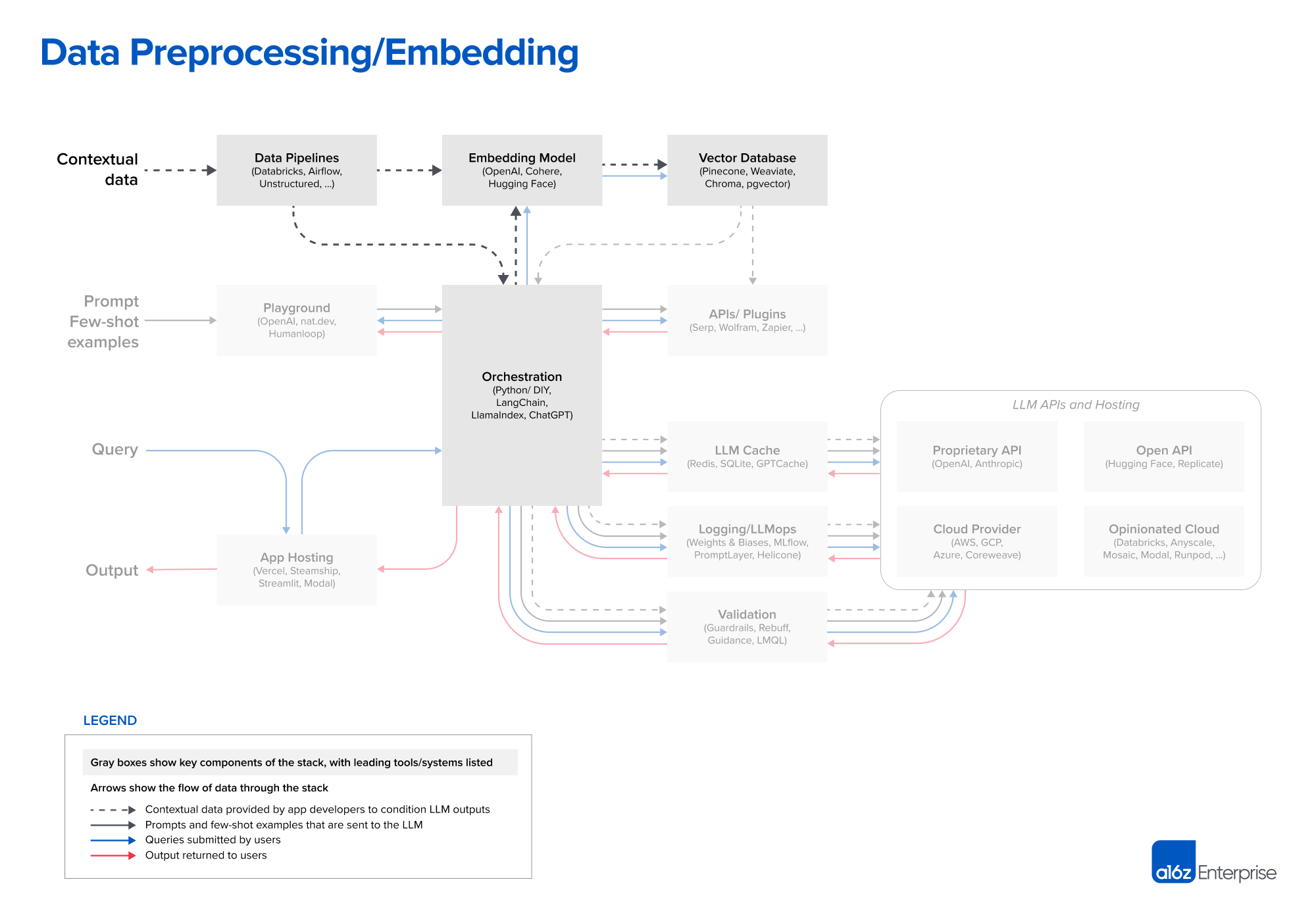
-
数据处理:数据的格式很多,word、pdf、csv、txt等等,目前并没有绝对合适的数据加载和转换方案,但可以参考LangChain等
-
embedding:推荐使用openai的 text-embedding-ada-002模型,因为它易于使用、价格合适且与openAI的其它产品兼容较好
-
向量数据库:
- 云数据库:推荐Pinecone,功能多且容易上手(仅适用于AWS、Google cloud、Azure)
- 开源数据库:Weaviate、Vespa、Qdrant、Chroma 、Faiss
向量数据库这块的选择,可以看看GitHub开源项目中的数据库选型
(目前,大部分开源向量数据库都在开发云数据库产品)
提示构造和检索
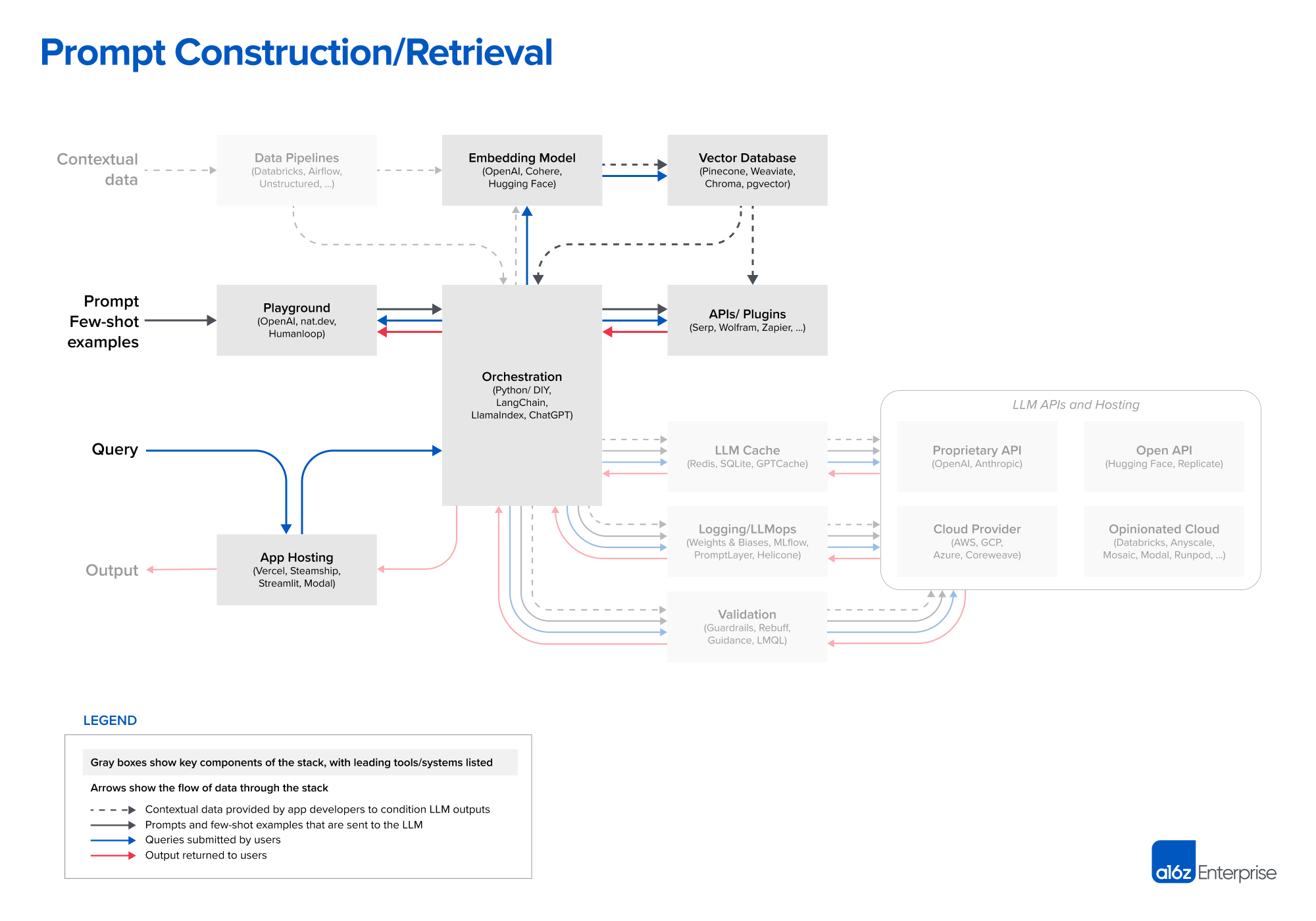
推荐使用LangChain进行提示构造
执行prompt
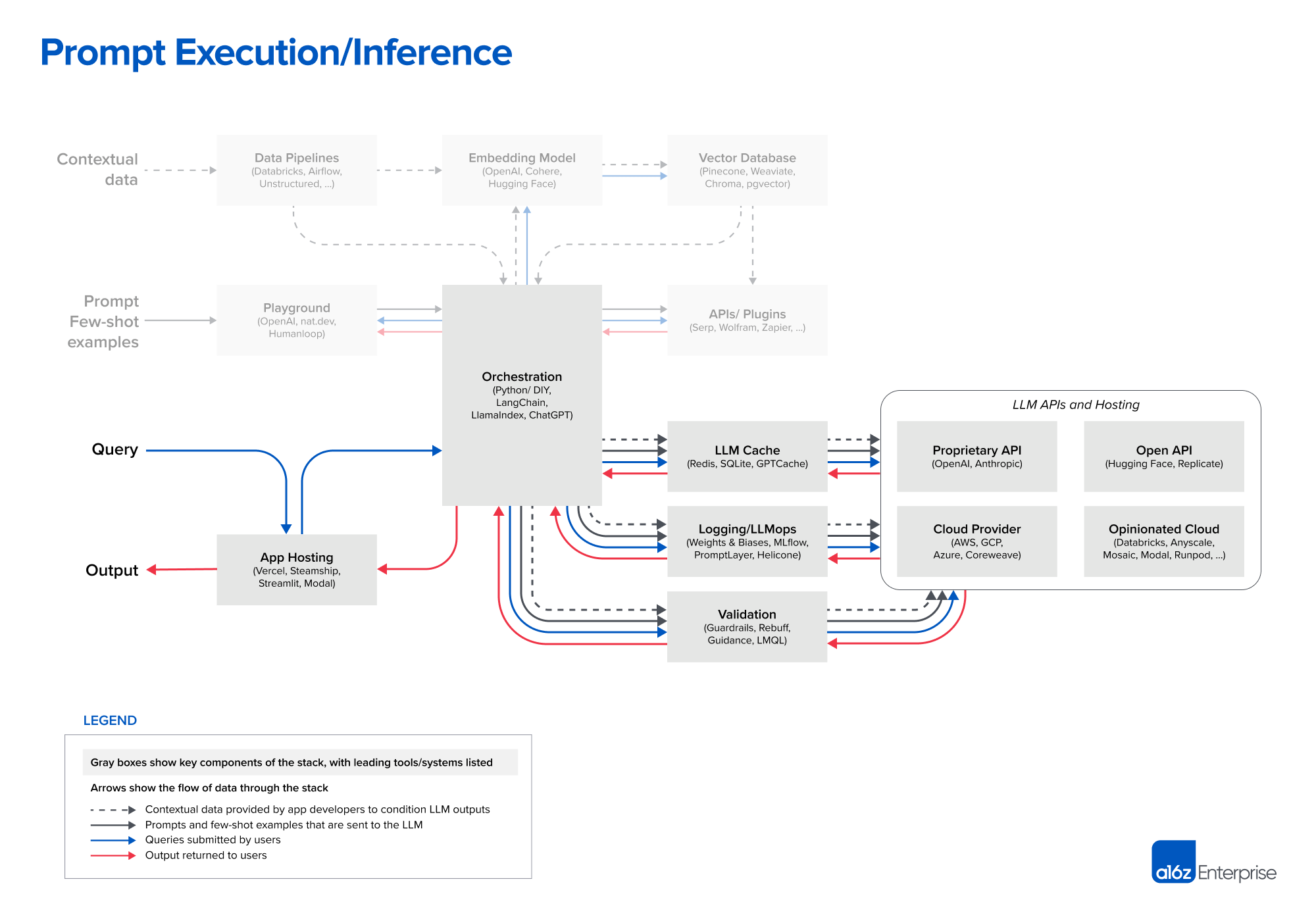















 102
102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









