







扩散模型
对在复杂网络上展开的扩散现象的分析是一项能够吸引多个研究领域越来越多兴趣的任务。
为了对这种复杂和广泛研究的问题提供一个简明的框架,有可能将相关文献分为两个广泛的、相关的子类:流行病学和舆论动力学(Epidemics and Opinion Dynamics)。
此外,NDlib还支持在不断变化的网络拓扑之上模拟扩散过程:动态网络模型部分是NDlib实现的。
观点动力学
近年来,在考虑到各种社会理论(如有限信心或社会影响)的情况下,人们引入了各种各样的模型,试图解释意见在人群中是如何形成的。
这些模型与在流行病和传播中看到的模型有很多共同之处。一般来说,个体被建模为具有状态的代理,并通过社会网络连接。
社会联系可以用一个完整的图(平均场模型)来表示,也可以用更现实的复杂网络来表示,类似于流行病和传播。
状态通常由变量表示,这些变量可以是离散的(类似于扩展的情况),也可以是连续的,例如表示选择一个选项或另一个选项的概率。个体状态随时间变化,主要通过与邻居的交互,基于一组更新规则。
虽然在许多传播和流行模型中,这种变化是不可逆的(易受感染),但在意见动力学中,状态可以在可能的值之间自由振荡,从而模拟现实中意见的变化。
舆论动态的另一个重要方面是外部信息,它可以被解释为大众媒体的影响。一般来说,外部信息被表示为一个静态的个体,所有其他人都可以与他互动,这也出现在传播模型中。因此,很明显,这两个模型类别有足够多的共同点,可以在一个公共框架下实现,这就是为什么我们在我们的框架中引入这两个模型。
选民模型 Voter model
选民模型是最简单的观点动态模型之一,最初是用来分析物种的竞争,很快就被应用到模型选举。
该模型假设个体的意见是一个离散变量±1。
种群状态的变化基于一个非常简单的更新规则:在每次迭代中,随机选择一个个体,然后他复制一个随机邻居的意见。
从任何初始配置开始,在一个完整的网络上,整个群体都会对两个选项中的一个达成共识。在意见+1上达成一致的概率等于持有该意见的个人的初始分数。
在下面的代码中显示了在随机图上实例化和执行Voter模型模拟的示例:我们将初始感染节点集设置为总体的10%。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as op
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = op.VoterModel(g)
config = mc.Configuration()
config.add_model_parameter('fraction_infected', 0.1)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(200)
Q-Voter模型
是作为离散意见动态模型的推广而引入的。
在这里,N个人持有±1的意见。在每个时间步骤中,选择一组q个邻居,如果它们一致,它们会随机影响一个邻居,即该代理复制该组的意见。如果群体不同意,智能体以ε的概率改变其意见。
很明显,voter模型和Sznajd模型是这个新模型的特殊情况(q = 1,ε = 0和q = 2,ε = 0)。
q≤3时的分析结果验证了特殊情况模型的数值结果,从有序相位(小ε)过渡到无序相位(大ε)。对于q > 3,两相之间出现了一种新型的过渡,它包括通过最终状态取决于初始条件的中间状态。在NDlib中实现ε = 0的模型。
在下面的代码中显示了在随机图上实例化和执行q - voter模型模拟的示例:我们将初始感染节点集设置为总体的10%,影响邻居的数量q等于5。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as op
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = op.QVoterModel(g)
config = mc.Configuration()
config.add_model_parameter("q", 5)
config.add_model_parameter('fraction_infected', 0.1)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(200)
多数决定规则模型 The Majority Rule model
是一种离散的观点动态模型,被用来描述公开辩论。
代理人采取离散意见±1,就像选民模型。在每一个时间步骤中,随机选择一组r个代理,他们都在组内采取多数意见。
组的大小可以是固定的,也可以是从特定分布的每个时间步取的。如果r是奇数,那么多数意见总是确定的,但是如果r是偶数,就可能出现平局的情况。在这种情况下,为了选择一个流行的观点,引入了一个倾向于一个观点(+1)的偏见。
这个想法的灵感来自于社会惯性的概念。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as op
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = op.MajorityRuleModel(g)
config = mc.Configuration()
config.add_model_parameter('fraction_infected', 0.1)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(200)
Sznajd模型
是采用社会影响理论的spin模型的变体,该模型考虑到具有相同意见的一群人比一个人更能影响他们的邻居这一事实。
在原来的模型中,社会网络是一个二维的格子,但是我们也在任何复杂的网络上实现了变体。
每个代理人都有自己的意见 σ i = ± 1 \sigma_i =±1 σi=±1。在每个时间步中,选择一对相邻的智能体,如果它们的意见一致,则它们的所有邻居都采取该意见。
该模型已被证明收敛到两个一致的平稳状态之一,这取决于向上自旋的初始密度(50%密度的跃迁)。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as op
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = op.SznajdModel(g)
config = mc.Configuration()
config.add_model_parameter('fraction_infected', 0.1)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(200)
认知观点动力学 Cognitive Opinion Dynamics
中引入了认知意见动力学模型,该模型考虑了几个基于认知的变量,对个体的状态进行了建模。
该模型的目的是在外部(机构)信息存在的情况下,模拟对灾难性事件风险的反应。
个人意见被建模为一个连续变量Oi∈[0,1],表示对风险的感知程度(灾难性事件实际发生的可能性有多大)。
这种观点通过与邻居和外部信息的互动而发展,基于每个个体i的四个内部变量:
风险敏感性(Ri∈{−1,0,1}),
告知他人的倾向 (βi∈[0,1]),
对制度的信任(Ti∈[0,1]),和
信任对等体(Πi = 1−Ti)。
这些值是在初始化填充时生成的,并在模拟期间保持固定。
更新规则定义Oi值如何随时间变化。
结果表明,该模型能够较好地再现各种实际情况。特别是,在评估风险情况时,显而易见,风险敏感性比对机构信息的信任更重要。
在下面的代码中显示了在随机图上实例化和执行认知意见动力学模型模拟的示例:我们将初始感染节点集设置为总体的10%,外部信息值设置为015,B和T间隔等于[0,1],阳性/中性/感染的分数等于1/3。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as op
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = op.CognitiveOpDynModel(g)
# Model Configuration
config = mc.Configuration()
config.add_model_parameter("I", 0.15)
config.add_model_parameter("B_range_min", 0)
config.add_model_parameter("B_range_max", 1)
config.add_model_parameter("T_range_min", 0)
config.add_model_parameter("T_range_max", 1)
config.add_model_parameter("R_fraction_negative", 1.0 / 3)
config.add_model_parameter("R_fraction_neutral", 1.0 / 3)
config.add_model_parameter("R_fraction_positive", 1.0 / 3)
config.add_model_parameter('fraction_infected', 0.1)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(200)
算法偏差模型 The Algorithmic Bias
考虑个体的总体,其中每个个体在区间[0,1]中持有一个连续的观点。个体通过社会网络相互联系,并以离散的时间步成对地相互作用。相互作用的对在每个时间点从总体中选择,以这样一种方式,具有接近意见值的个体被更多地选择,以模拟算法偏差。参数 γ \gamma γ控制了这种效应的大小。具体来说,交互对中的第一个个体是随机选择的,而第二个个体的选择是基于与第一个个体的观点的距离越远,概率越小,即与距离的 γ \gamma γ次方成正比。
相互作用后,两种观点可能会改变,这取决于所谓的有界置信度参数。这可以被看作是一个群体中个体思想开放程度的衡量标准。它定义了两个个体观点之间距离的阈值,超过这个阈值,个体之间就不可能因为观点冲突而进行交流。因此,如果所选个体的意见之间的距离小于 ϵ \epsilon ϵ,则两个个体采用他们的平均意见。否则什么都不会发生。
注意:设置 γ = 0 \gamma=0 γ=0会重现Deffuant模型的结果。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as op
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = op.AlgorithmicBiasModel(g)
# Model configuration
config = mc.Configuration()
config.add_model_parameter("epsilon", 0.32)
config.add_model_parameter("gamma", 1)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(200)
吸引-排斥加权Hegselmann-Krause模型 Attraction-Repulsion Weighted Hegselmann-Krause model
吸引-排斥加权H-K模型是由Toccaceli等人在2020年引入的。
该模型是加权Hegselmann-Krause (WHK)模型的一种变体。该模型考虑了成对交互。为了模拟意见的吸引和排斥,在每次迭代中,一个代理i和它的一个邻居j被随机选择,不考虑柱柱的相互作用。一旦确定了成对的相互作用,就计算出i和j意见之间的差值的绝对值。该方法有四种不同的变体:
- 基本情况:如果计算出的差值小于
ϵ
\epsilon
ϵ,则更新规则变为:
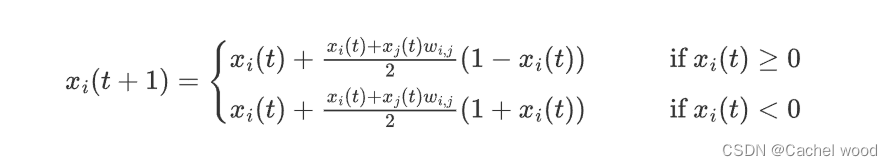
- 吸引 Attraction:如果计算出的差值小于住所的
ϵ
\epsilon
ϵ,则应用以下更新规则:
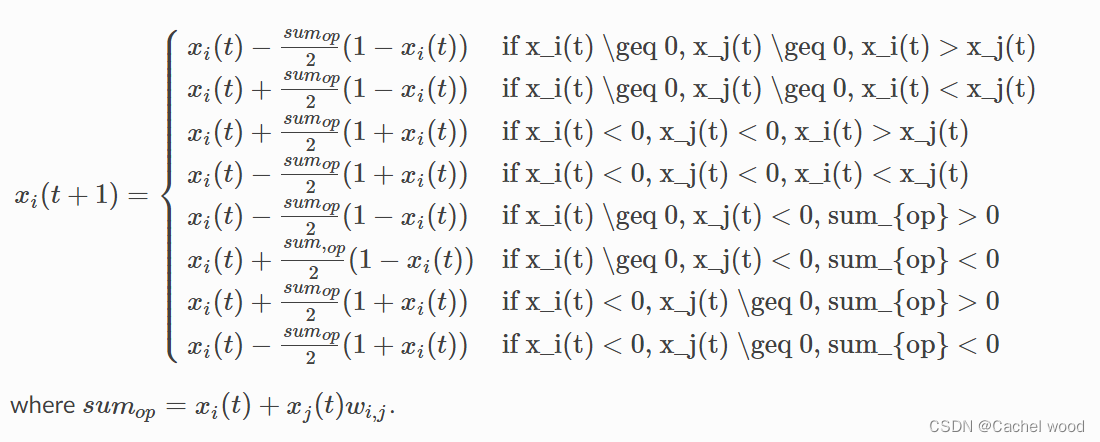
- 排斥 Repulsion:如果
x
i
(
t
)
x_i(t)
xi(t)和
x
j
(
t
)
x_j(t)
xj(t)之间的差超过了
ϵ
\epsilon
ϵ,那么下面的更新规则将被应用:
吸引与排斥:当计算出的差值小于 ϵ \epsilon ϵ,则相互吸引,反之则相互排斥。 - 吸引与排斥:当计算出的差值小于 ϵ \epsilon ϵ时,则相互吸引,反之则相互排斥。
在下面的代码中显示了在随机图上实例化和执行ARWHK模型模拟的示例:我们将epsilon值赋为0.32,顽固度的百分比等于0.2,顽固度的分布等于0,所有边的权重等于0.2。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as opn
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = opn.ARWHKModel(g)
# Model Configuration
config = mc.Configuration()
config.add_model_parameter("epsilon", 0.32)
config.add_model_parameter("perc_stubborness", 0.2)
config.add_model_parameter("option_for_stubbornness", 0)
config.add_model_parameter("method_variant", 2)
# Setting the edge parameters
weight = 0.2
if isinstance(g, nx.Graph):
edges = g.edges
else:
edges = [(g.vs[e.tuple[0]]['name'], g.vs[e.tuple[1]]['name']) for e in g.es]
for e in edges:
config.add_edge_configuration("weight", e, weight)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(20)
Weighted Hegselmann-Krause
加权Hegselmann-Krause由Milli等人于2021年提出。
该模型是著名的Hegselmann-Krause (HK)模型的变体。在每次交互过程中,随机选择一个代理,并确定其邻居的集合
Γ
ϵ
\Gamma_{\epsilon}
Γϵ,其意见在最多的
ϵ
(
d
i
,
j
=
∣
x
i
(
t
)
−
x
j
(
t
)
∣
≤
ε
)
\epsilon(d_{i,j}=|x_i(t)−x_j(t)|≤ε)
ϵ(di,j=∣xi(t)−xj(t)∣≤ε)。此外,为了解释智能体对之间交互频率的异质性,WHK利用了边缘权重,从而捕捉到现实中不同社会纽带的强度/信任的影响。在这种情况下,每条边
(
i
,
j
)
∈
E
(i,j)∈E
(i,j)∈E,携带一个值
w
i
,
j
∈
[
0
,
1
]
w_{i,j}∈[0,1]
wi,j∈[0,1]。然后更新规则变成:
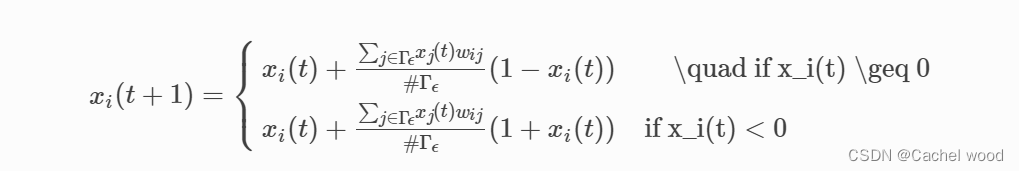
WHK公式背后的思想是,代理人i在时间t+1的意见,将由他之前的信念和其所选的ϵ-neighbor加权的平均意见的综合效应给出,其中
w
i
,
j
w_{i,j}
wi,j说明了i对j的感知影响力/信任。
在下面的代码中显示了在随机图上实例化和执行WHK模型模拟的示例:我们的epsilon值为0.32,所有边的权重为0.2。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as opn
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = opn.WHKModel(g)
# Model Configuration
config = mc.Configuration()
config.add_model_parameter("epsilon", 0.32)
# Setting the edge parameters
weight = 0.2
if isinstance(g, nx.Graph):
edges = g.edges
else:
edges = [(g.vs[e.tuple[0]]['name'], g.vs[e.tuple[1]]['name']) for e in g.es]
for e in edges:
config.add_edge_configuration("weight", e, weight)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(20)
Hegselmann-Krause
Hegselmann-Krause模型是Hegselmann, Krause等人在2002年提出的。
在每次交互过程中,随机选择一个代理,并确定其邻居的集合
Γ
ϵ
\Gamma_{\epsilon}
Γϵ,其意见在最多的
ε
(
d
i
,
j
=
∣
x
i
(
t
)
−
x
j
(
t
)
∣
≤
ε
)
ε(d_{i,j}=|x_i(t)−x_j(t)|≤ε)
ε(di,j=∣xi(t)−xj(t)∣≤ε)。所选代理i根据以下更新规则更改其意见:
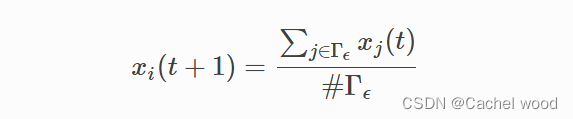
WHK公式背后的思想是,智能体i在时间t+1的意见,将由其所选ϵ-neighbor的平均意见给出。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as opn
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = opn.HKModel(g)
# Model Configuration
config = mc.Configuration()
config.add_model_parameter("epsilon", 0.32)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(20)
可视化 Visualization
扩散的趋势 Diffusion Trend
扩散趋势图比较了测试的扩散模型允许的所有状态的趋势。
每条趋势线描述了一次又一次迭代给定状态下节点数量的变化。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.epidemics as ep
from ndlib.viz.mpl.DiffusionTrend import DiffusionTrend
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = ep.SIRModel(g)
# Model Configuration
cfg = mc.Configuration()
cfg.add_model_parameter('beta', 0.001)
cfg.add_model_parameter('gamma', 0.01)
cfg.add_model_parameter("fraction_infected", 0.01)
model.set_initial_status(cfg)
# Simulation execution
iterations = model.iteration_bunch(200)
trends = model.build_trends(iterations)
# Visualization
viz = DiffusionTrend(model, trends)
viz.plot("diffusion.pdf")
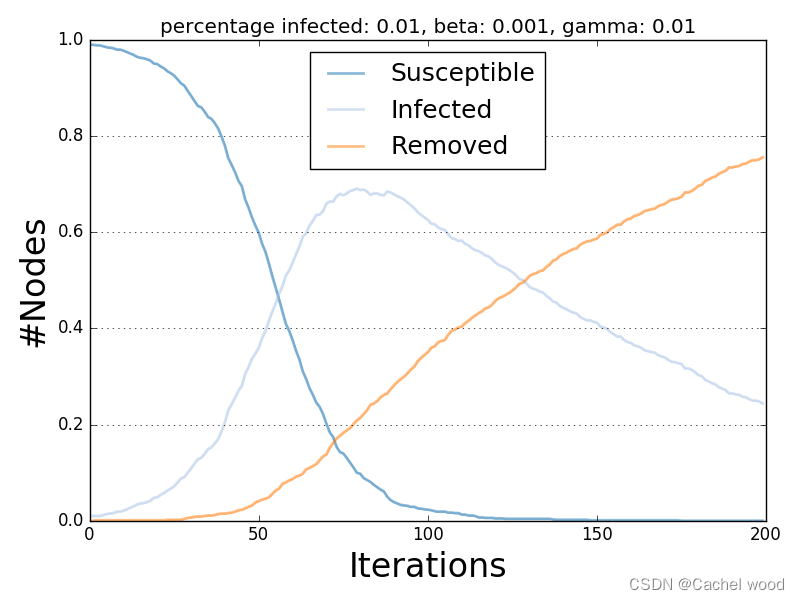
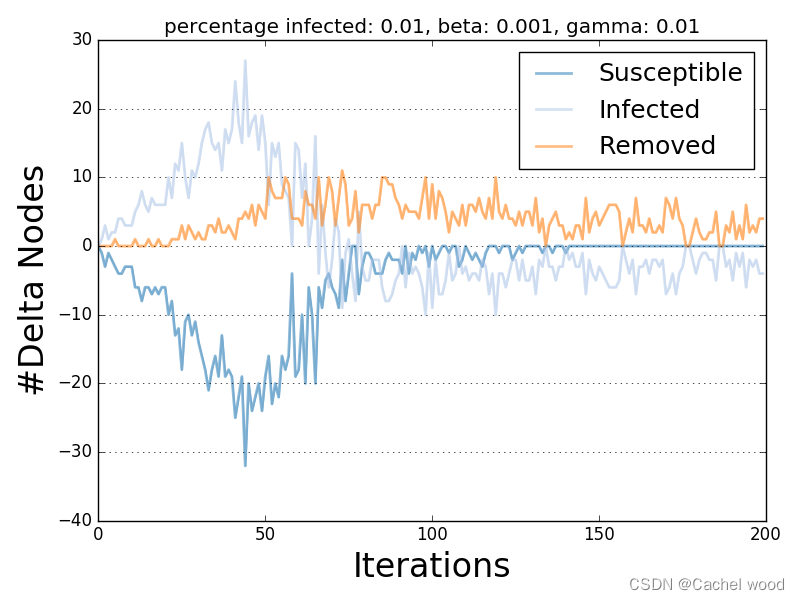
扩散流行率 Diffusion Prevalence
扩散流行率图比较了测试的扩散模型允许的所有状态的delta-趋势。
每条趋势线描述了给定状态迭代后节点数量的增量。
下面是SIR模型的扩散流行度描述和可视化示例。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.epidemics as ep
from ndlib.viz.mpl.DiffusionPrevalence import DiffusionPrevalence
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = ep.SIRModel(g)
# Model Configuration
cfg = mc.Configuration()
cfg.add_model_parameter('beta', 0.001)
cfg.add_model_parameter('gamma', 0.01)
cfg.add_model_parameter("fraction_infected", 0.01)
model.set_initial_status(cfg)
# Simulation execution
iterations = model.iteration_bunch(200)
trends = model.build_trends(iterations)
# Visualization
viz = DiffusionPrevalence(model, trends)
viz.plot("prevalence.pdf")
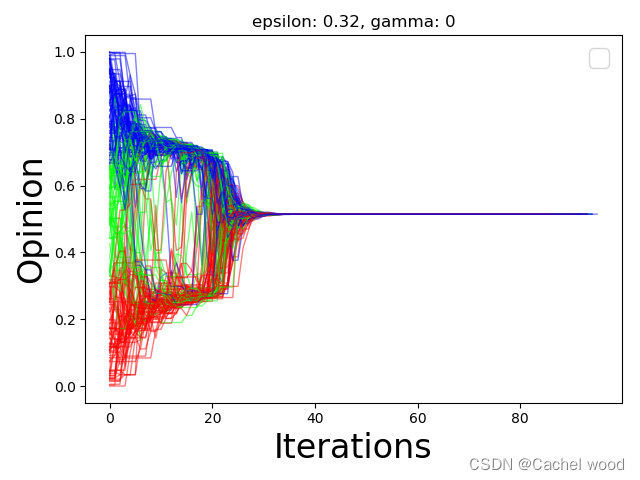
观点进化 Opinion Evolution
观点演化图显示了连续状态模型中节点的观点演化。
下面是算法偏差模型的观点进化描述和可视化示例。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.opinions as op
from ndlib.viz.mpl.OpinionEvolution import OpinionEvolution
# mMean field scenario
g = nx.complete_graph(100)
# Algorithmic Bias model
model = op.AlgorithmicBiasModel(g)
# Model configuration
config = mc.Configuration()
config.add_model_parameter("epsilon", 0.32)
config.add_model_parameter("gamma", 0)
model.set_initial_status(config)
# Simulation execution
iterations = model.iteration_bunch(100)
viz = OpinionEvolution(model, iterations)
viz.plot("opinion_ev.pdf")
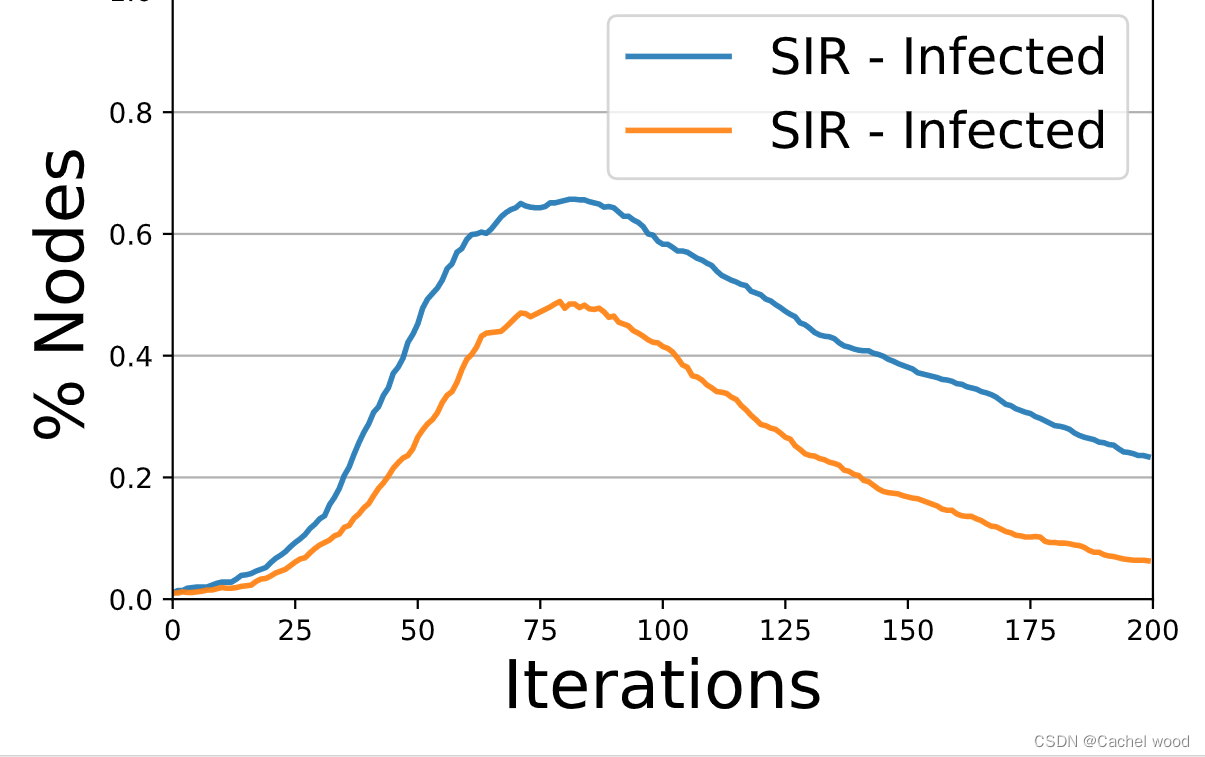
扩散趋势比较图 Diffusion Trend Comparison
比较测试扩散模型允许的所有状态的趋势。
每条趋势线描述了一次又一次迭代给定状态下节点数量的变化。
下面是SIR模型的扩散趋势描述和可视化示例。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.epidemics as ep
from ndlib.viz.mpl.TrendComparison import DiffusionTrendComparison
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = ep.SIRModel(g)
# Model Configuration
cfg = mc.Configuration()
cfg.add_model_parameter('beta', 0.001)
cfg.add_model_parameter('gamma', 0.01)
cfg.add_model_parameter("fraction_infected", 0.01)
model.set_initial_status(cfg)
# Simulation execution
iterations = model.iteration_bunch(200)
trends = model.build_trends(iterations)
# 2° Model selection
model1 = ep.SIRModel(g)
# 2° Model Configuration
cfg = mc.Configuration()
cfg.add_model_parameter('beta', 0.001)
cfg.add_model_parameter('gamma', 0.02)
cfg.add_model_parameter("fraction_infected", 0.01)
model1.set_initial_status(cfg)
# 2° Simulation execution
iterations = model1.iteration_bunch(200)
trends1 = model1.build_trends(iterations)
# Visualization
viz = DiffusionTrendComparison([model, model1], [trends, trends1])
viz.plot("trend_comparison.pdf")
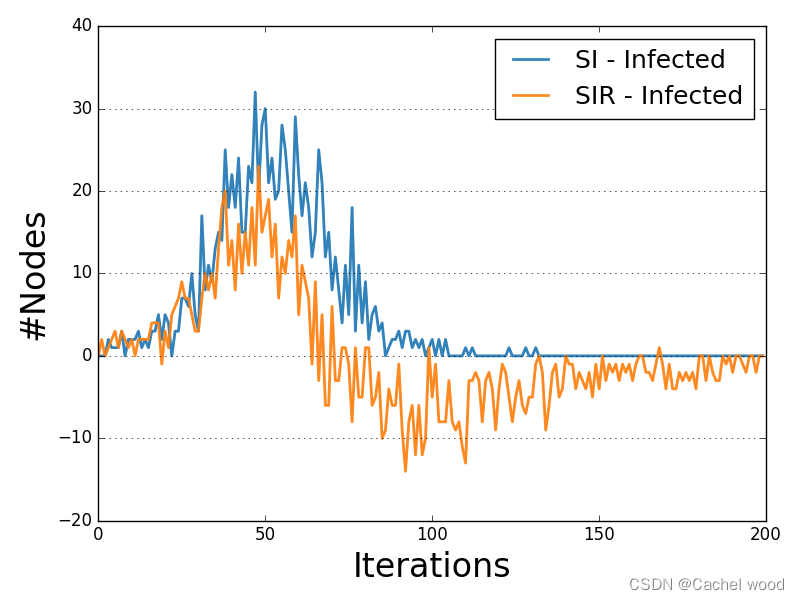
扩散流行率比较 Diffusion Prevalence Comparison
扩散流行率图比较了测试的扩散模型允许的所有状态的delta-趋势。
每条趋势线描述了给定状态迭代后节点数量的增量。
下面是SIR模型的两个实例的扩散流行描述和可视化示例。
import networkx as nx
import ndlib.models.ModelConfig as mc
import ndlib.models.epidemics as ep
from ndlib.viz.mpl.PrevalenceComparison import DiffusionPrevalenceComparison
# Network topology
g = nx.erdos_renyi_graph(1000, 0.1)
# Model selection
model = ep.SIRModel(g)
# Model Configuration
cfg = mc.Configuration()
cfg.add_model_parameter('beta', 0.001)
cfg.add_model_parameter('gamma', 0.02)
cfg.add_model_parameter("fraction_infected", 0.01)
model.set_initial_status(cfg)
# Simulation execution
iterations = model.iteration_bunch(200)
trends = model.build_trends(iterations)
# 2° Model selection
model1 = ep.SIModel(g)
# 2° Model Configuration
cfg = mc.Configuration()
cfg.add_model_parameter('beta', 0.001)
cfg.add_model_parameter("fraction_infected", 0.01)
model1.set_initial_status(cfg)
# 2° Simulation execution
iterations = model1.iteration_bunch(200)
trends1 = model1.build_trends(iterations)
# Visualization
viz = DiffusionPrevalenceComparison([model, model1], [trends, trends1])
viz.plot("trend_comparison.pdf")

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











