






 本文探讨了在混合架构下的GCN网络中,如何通过调整组合阶段和聚合阶段的资源分配,利用乘加器实现负载均衡,避免计算停滞。作者提出了一种调度策略,根据输入图节点的特征长度和连接关系动态调整计算核心的使用,以最大化硬件资源的利用率。
本文探讨了在混合架构下的GCN网络中,如何通过调整组合阶段和聚合阶段的资源分配,利用乘加器实现负载均衡,避免计算停滞。作者提出了一种调度策略,根据输入图节点的特征长度和连接关系动态调整计算核心的使用,以最大化硬件资源的利用率。
负载均衡问题
在混合架构下GCN网络中,在其组合阶段与聚合阶段之间存在负载差异,即其中一部分执行结束而另一部分尚未结束整个网络计算过程会发生停滞,从而影响网络工作效率。为解决这一问题,一般论文采用在组合阶段与聚合阶段之间加入buffer的情况,这将极大的改善网络工作效率。但上述过程仍然未能根本的解决计算停滞问题,如果输入的图节点连接关系变化稍大,甚至在同一个图中存在疏密程度相差较大的情况,buffer仍会进入空和满的状态。这里介绍一种我所设计一种用于负载均衡的尝试。
原始论文截图如下:
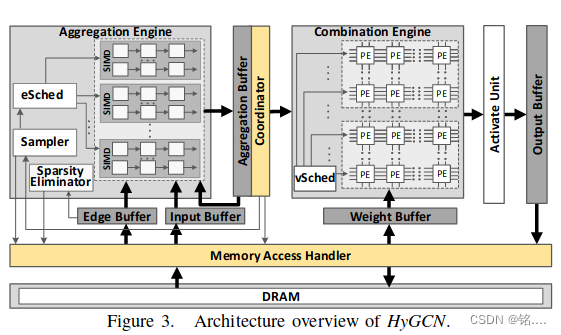
核心思想
在一般的论文中,聚合阶段主要由乘加器进行特征聚合,而在组合阶段类似多层感知机,通常采用脉动阵列进行加速处理。事实上,此处脉动阵列处理的也是一种乘加关系,理论上也可以使用乘加器进行处理,乘加器以模块形式构成。
如果这些乘加器外部包上相应的调用接口,使得如果buffer中数据条数大于某一个值(即组合部分处理能力小于聚合部分),则将聚合部分中计算核心用于组合部分的运算;反之,则将组合部分的计算核心用于聚合部分。理论上只要设计合理,两部分将永远不会出现计算单元停滞的情况,硬件资源将得到充分的利用。为此我希望设计一种调度策略和可供调度的计算核心,用以实现上述思想。
实际操作
在实际图数据中,节点往往是稀疏连接的。相对而言输入节点的特征长度要远远超过一般的节点度大小。(如Cora数据集中,节点原始特征长度为1432,最大节点度为168,且该节点节点度要远远超过一般节点的节点度。)如果聚合阶段中对于因此,本次设计中仅考虑将聚合部分的计算核心调用至组合阶段的情况,反之则不考虑。这里采用一种虚拟核心的思想,设置一些放置乘累加器的盒子,这些盒子中可以装入乘加器等计算核心,也可空置。于是整个过程等价于将聚合阶段计算单元从聚合阶段的盒子挪至组合阶段的盒子中。(此处暂时没画图像,日后补全)
这里确定一种简单的策略:如果buffer(此处用类似fifo的结构来实现)中有效数据到达fifo总量占比的某一定值,则所有聚合阶段的计算核心全部调去完成组合阶段的工作,直至他们完成一次工作,为衡量此处fifo的最小深度,这里可以建立这样一个方程组。
设
i
n
_
p
a
r
a
l
l
e
l
in\_parallel
in_parallel为聚合部分计算核心的并行度,即同时有几个计算核心进行输入部分的并行处理,或者说同时有几个节点在聚合计算;
o
u
t
_
p
a
r
a
l
l
e
l
out\_parallel
out_parallel同理,为处理输出并行的核心数量。
f
e
a
t
u
r
e
_
w
i
d
t
h
feature\_width
feature_width为输入的节点特征宽度,
f
e
a
t
u
r
e
′
_
w
i
d
t
h
feature'\_width
feature′_width为输出层节点特征宽度。同时定义
p
⊂
(
0
,
1
)
p\subset(0,1)
p⊂(0,1),为触发聚合部分计算单元进行组合运算的fifo填充占比,设
k
=
f
e
a
t
u
r
e
_
w
i
d
t
h
/
f
e
a
t
u
r
e
′
_
w
i
d
t
h
k=feature\_width/feature'\_width
k=feature_width/feature′_width。设
f
i
f
o
_
d
fifo\_d
fifo_d是该fifo的深度。
数据填充到
p
⋅
f
i
f
o
_
d
p·fifo\_d
p⋅fifo_d是,开始调用乘加器。此时存在两种极端情况:
-填充后fifo不溢出,对应公式(1)
-调用完后fifo不空,且处理完成后仍有至少一次足够组合阶段继续进行的数据(保证组合阶段不停滞运行)
i
n
_
p
a
r
a
l
l
e
l
+
p
⋅
f
i
f
o
_
d
≤
f
i
f
o
_
d
k
⋅
i
n
_
p
a
r
a
l
l
e
l
+
2
⋅
o
u
t
_
p
a
r
a
l
l
e
l
≤
p
⋅
f
i
f
o
_
d
\begin{align} &in\_parallel + p · fifo\_d \leq fifo\_d \\ &k·in\_parallel + 2·out\_parallel \leq p · fifo\_d \end{align}
in_parallel+p⋅fifo_d≤fifo_dk⋅in_parallel+2⋅out_parallel≤p⋅fifo_d
令
f
i
f
o
_
d
fifo\_d
fifo_d最小,求
p
p
p
f
i
f
o
_
d
≥
m
a
x
{
i
n
_
p
a
r
a
l
l
e
l
1
−
p
,
k
⋅
i
n
_
p
a
r
a
l
l
e
l
+
2
⋅
o
u
t
_
p
a
r
a
l
l
e
l
p
}
\begin{align} &fifo\_d\geq max\{{\frac{in\_parallel}{1-p}},\frac{k·in\_parallel + 2·out\_parallel }{p}\} \end{align}
fifo_d≥max{1−pin_parallel,pk⋅in_parallel+2⋅out_parallel}
二者相等时有极值
p
=
k
⋅
i
n
_
p
a
r
a
l
l
e
l
+
2
⋅
o
u
t
_
p
a
r
a
l
l
e
l
(
1
+
k
)
⋅
i
n
_
p
a
r
a
l
l
e
l
+
2
⋅
o
u
t
_
p
a
r
a
l
l
e
l
\begin{align} p=\frac{k·in\_parallel + 2·out\_parallel}{(1+k)·in\_parallel + 2·out\_parallel} \end{align}
p=(1+k)⋅in_parallel+2⋅out_parallelk⋅in_parallel+2⋅out_parallel
当
k
=
8
k=8
k=8,
i
n
_
p
a
r
a
l
l
e
l
=
2
in\_parallel=2
in_parallel=2,
o
u
t
_
p
a
r
a
l
l
e
l
=
8
out\_parallel=8
out_parallel=8时
有
f
i
f
o
_
d
=
34
fifo\_d=34
fifo_d=34,
p
=
32
/
34
p=32/34
p=32/34
注:对于无法前后特征无法整除的情况,可以在无法整除时将前一级特征补0,补长至可以整除的长度。
以上是本人对于负载均衡的一种想法,在后面几章会对此进行尝试,并完成chisel代码的编写
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









