






在看《大型网站系统及Java中间件实践》这本书的时候,作者在书中提出了一个简单的问题
在使用Hashmap进行多线程计数时,程序是这样的
public class TestClass{
private HashMap<Integer,Integer> map = new HashMap<>();
private Synchronized void add(int key){
Integer value = map.get(key);
if(value == null){
map.put(key,1);
}else{
map.put(key,value+1);
}
}
}在使用ConcurrentHashMap时,程序是这样的
public class TestClass{
private ConcurrentHashMap<Integer,Integer> map = new ConcurrentHashMap<>();
private void add(int key){
Integer value = map.get(key);
if(value == null){
map.put(key,1);
}else{
map.put(key,value+1);
}
}
}写一个测试程序来测试一下后面这个方法的正确性
import java.util.HashMap;
import java.util.Map.Entry;
import java.util.Random;
import java.util.concurrent.*;
public class ConHashMapTest {
private static ConcurrentHashMap<Integer,Integer> map = new ConcurrentHashMap<Integer, Integer>();
private static int[] array;
static void generate(){
array = new int[10000];
for(int i=0;i<10000;i++){
array[i] = new Random().nextInt(10);
}
}
public static void main(String[] args) throws InterruptedException {
generate();
System.out.println("array size:"+array.length);
System.out.println("single thread");
for(int i : array){
Integer value = map.get(i);
if(value == null){
map.put(i,1);
}else{
map.put(i,value+1);
}
}
for(Entry<Integer,Integer> entry : map.entrySet()){
System.out.println(entry.getKey()+":"+entry.getValue());
}
map.clear();
System.out.println("\nmulti thread");
ThreadPoolExecutor service = (ThreadPoolExecutor)Executors.newFixedThreadPool(100);
for (int str : array) {
Thread thread = new Thread(new MyTask(str));
service.execute(thread);
}
while(! service.getQueue().isEmpty()){}
service.shutdown();
for(Entry<Integer,Integer> entry : map.entrySet()){
System.out.println(entry.getKey()+":"+entry.getValue());
}
}
static class MyTask implements Runnable{
int key;
public MyTask(int key) {
this.key = key;
}
@Override
public void run() {
Integer value = map.get(key);
if(null == value){
map.put(key, 1);
}else{
map.put(key, value + 1);
}
}
}
}运行结果是如下
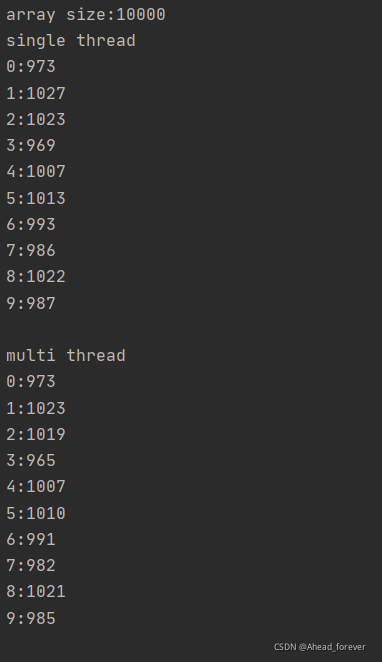
可以明显的看到,在多线程情形下,计数的结果比单线程的少,说明这种对ConcurrentHashMap的使用是存在问题的。
下面对问题进行分析
熟悉多线程的使用的大嘎们都知道,在多线程的情况下,取出一个数,再对数进行比较,接着再赋值,这个过程中可能会有其他线程加入进来。线程A和B,A先获取了数,在A进行更新操作之前B也获取了数,A对数进行更新后,B根据自己获取的数进行+1操作,这个操作覆盖了A的更新,所以本来应该+2的,结果变成了+1 ,这就是多线程环境下计数会比正确结果少的原因。如果数组里面的相同值频率很高的话,与正确结果的偏差会越大。
所以在线程的run方法上,应该对读取和更新操作加锁,修改如下,其余代码不需要更改
public void run() {
synchronized (map){
Integer value = map.get(key);
if(null == value){
map.put(key, 1);
}else{
map.put(key, value + 1);
}
}
}加了synchronized关键字后,在同一时间就只能有一个线程对map进行更新,这样做从感觉上来说就失去了并发包下的类的目的——尽量的提高并发度,提高多线程环境下的效率。在加了synchronized关键字后,其实使用线程不安全的HashMap也具有同样的功能,同样能够得出正确的结果。
在这个场景下,计数需要对数进行读取,比较进而再赋值,天然的就不具有原子性,这样的一个过程必须要加锁。
ConcurrentHashMap适合于直接对值进行修改,在ConcurrentHashMap的内部使用CAS保证了更新操作的原子性,在同一时间只有一个线程能够完成对值的更新,在这种情形下是能够确保更新操作的正确性的。
后面的对于错误原因的分析和ConcurrentHashMap的使用是出于个人的见解,如果有什么不正确的地方,还请CSDN的各位大佬指正,欢迎评论区交流。

















 1771
1771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









