






作业要求:实现BPnet(或RBFnet)。建议采用连续数值的数据做实验,例如iris数据集合。
就不用iris数据集了,试一下MNIST数据集。
数据集介绍
MNIST数据集(Modified National Institute of Standards and Technology database)是一个广泛使用的手写数字图像数据集。
- 图像类型:灰度图像
- 图像大小:28x28像素
- 通道数:1(灰度)
- 类别数:10(数字0-9)
- 训练集:60,000张图像
- 测试集:10,000张图像
下载数据集并解析
保存前100张训练集和测试集图片,备用
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载MNIST训练集和测试集
trainset = datasets.MNIST(root='data', train=True, download=True, transform=transform)
testset = datasets.MNIST(root='data', train=False, download=True, transform=transform)
# 创建数据加载器
trainloader = DataLoader(trainset, batch_size=1, shuffle=False)
testloader = DataLoader(testset, batch_size=1, shuffle=False)
# 创建保存图片的目录
os.makedirs('mnist_images/train', exist_ok=True)
os.makedirs('mnist_images/test', exist_ok=True)
# 保存前100张训练集图像
for i, (images, labels) in enumerate(trainloader):
if i >= 100:
break
# 转换为NumPy数组并还原灰度值范围
image_array = images[0].numpy().squeeze() * 255
image_pil = Image.fromarray(image_array.astype(np.uint8)) # 转换为PIL图像
# 保存图像文件,包含标签在文件名中
label = labels.item()
image_pil.save(f"mnist_images/train/train_image_{i}_label_{label}.png")
print(f"训练集图片 mnist_image_{i}_label_{label}.png 已保存")
# 保存前100张测试集图像
for i, (images, labels) in enumerate(testloader):
if i >= 100:
break
# 转换为NumPy数组并还原灰度值范围
image_array = images[0].numpy().squeeze() * 255
image_pil = Image.fromarray(image_array.astype(np.uint8)) # 转换为PIL图像
# 保存图像文件,包含标签在文件名中
label = labels.item()
image_pil.save(f"mnist_images/test/test_image_{i}_label_{label}.png")
print(f"测试集图片 test_image_{i}_label_{label}.png 已保存")

另存为图片还有一个好处:可以输入图片进入模型,得到直观的预测结果。
BPnet算法原理
BPnet,反向传播神经网络(Backpropagation Neural Network),是一种训练人工神经网络的算法。它是由多层感知机(Multi-Layer Perceptron,简称MLP)和反向传播(Backpropagation)算法组成。
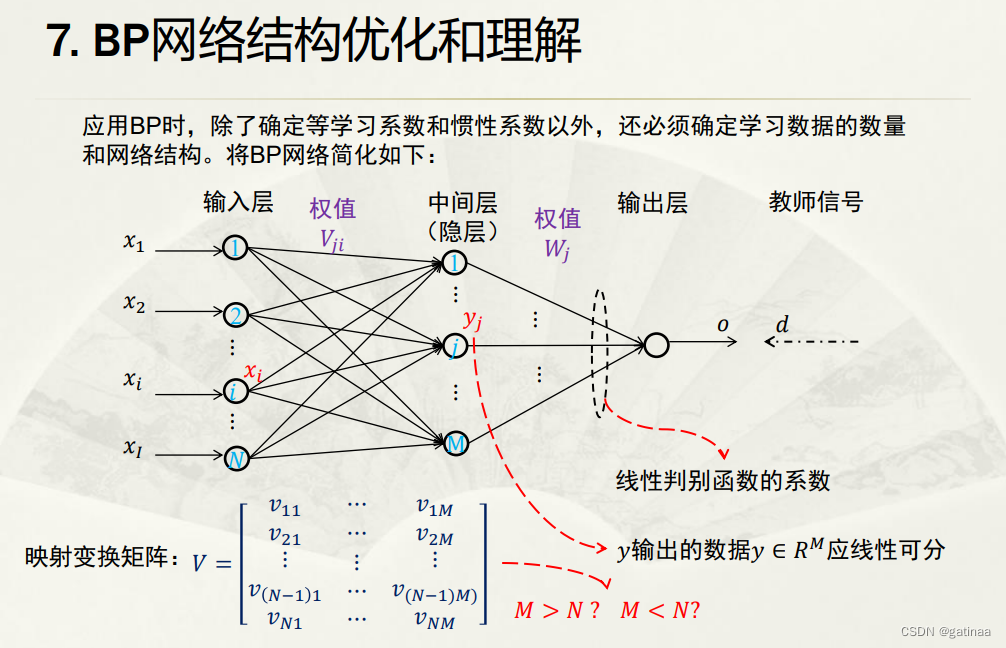
BPnet算法优化
BPnet对初始权重敏感,不同的初始化方法会影响训练结果可能会陷入局部最优解。
课上还提出了BPnet网络容易过拟合,连续学习的能力不行。
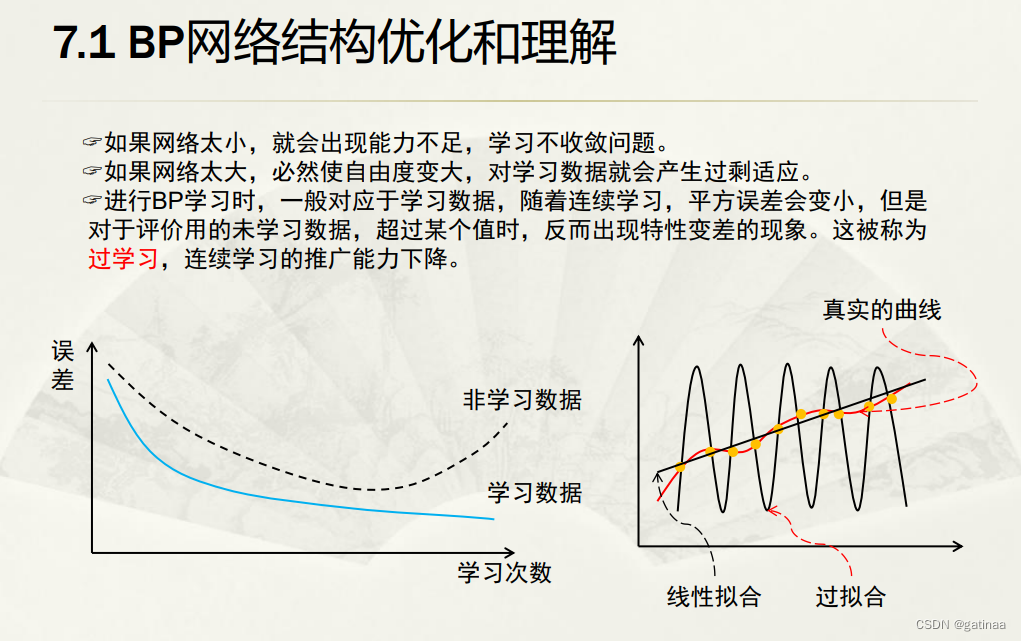
为了解决过拟合问题,老师讲到可以通过改变网络结构的方法来优化。在学习的同时减小网络规模,提升网络的学习能力。

利用VC维数(Vapnik-Chervonenkis dimension)来衡量模型复杂性。
早停法防止过拟合
我选的方法比较简单,利用早停法来防止过拟合。在训练过程中,模型在训练集上的表现逐渐变好,但在验证集或测试集上的表现可能在达到某个最佳点后开始变差。通过监控模型在验证集上的性能(通常是验证损失或验证准确率),在验证集性能不再改善时提前停止训练,从而防止模型在训练集上过度拟合。
# 早停法参数
early_stopping_patience = 5 # 设定容忍度
best_val_loss = float('inf') # 初始化最佳验证损失
patience_counter = 0 # 容忍度计数器
# 早停法检查
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
patience_counter = 0
torch.save(model.state_dict(), model_path) # 保存最好的模型
else:
patience_counter += 1
if patience_counter >= early_stopping_patience:
print("早停法生效,停止训练")
breakavg_val_loss < best_val_loss:是早停法的关键条件,它用于检查当前epoch的验证损失是否比之前记录的最佳验证损失更低。
在每个epoch结束时,模型会在验证集上进行评估,计算出当前的验证损失 avg_val_loss
早停法原理
如果 avg_val_loss 比 best_val_loss 更低,说明模型在当前epoch上的性能得到了提升;如果 avg_val_loss 不比 best_val_loss 更低,说明模型性能没有进一步提升;如果 patience_counter 达到设定的容忍度 early_stopping_patience,则停止训练,避免过拟合。
BPnet代码实现
# 定义BP神经网络
class BPnet(nn.Module):
def __init__(self):
super(BPnet, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28 * 28, 512)
self.bn1 = nn.BatchNorm1d(512)
self.fc2 = nn.Linear(512, 256)
self.bn2 = nn.BatchNorm1d(256)
self.fc3 = nn.Linear(256, 10)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.flatten(x)
x = torch.relu(self.bn1(self.fc1(x)))
x = self.dropout(x)
x = torch.relu(self.bn2(self.fc2(x)))
x = self.dropout(x)
x = self.fc3(x)
return xBPnet模型训练
训练时为了增强模型的鲁棒性。我进行了
- 数据增强:在训练数据变换中增加了随机旋转和裁剪。提高模型的泛化能力
'''随机地将图像旋转-10到+10度之间的角度。'''
transforms.RandomRotation(10)
'''先将图像四周填充4个像素,然后随机裁剪出一个28x28的区域。模拟不同的手写位置'''
transforms.RandomCrop(28, padding=4)
- 学习率调度:引入了学习率调度器,每5个epoch将学习率减小到原来的10%。
'''提高模型性能:在训练后期使用较小的学习率可以帮助模型在最优解附近更精确地调整参数,从而提高模型性能。
防止震荡和过拟合:通过逐渐减小学习率,可以减少参数更新的幅度,防止模型参数在最优解附近震荡,进而提高模型的泛化能力。'''
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)- 早停法: 防止过拟合
# 初始化模型
model = BPnet()
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 模型路径
model_path = 'bpnet_mnist_v3.pth' # 使用新的模型路径
# 早停法参数
early_stopping_patience = 5 # 设定容忍度
best_val_loss = float('inf') # 初始化最佳验证损失
patience_counter = 0 # 容忍度计数器
all_losses = [] # 用于存储每个epoch的训练损失
val_losses = [] # 用于存储验证集每个epoch的损失
# 如果存在模型则加载,否则训练模型
if os.path.exists(model_path):
try:
model.load_state_dict(torch.load(model_path))
print(f'模型已加载自 {model_path}')
except RuntimeError as e:
print(f'加载模型时出错: {e}')
print('重新训练模型...')
else:
# 训练循环
for epoch in tqdm(range(20)): # 设定一个较大的epoch数量,使用早停法提前停止
running_loss = 0.0
model.train() # 设置模型为训练模式
for images, labels in trainloader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
all_losses.append(avg_loss)
print(f'Epoch {epoch + 1}, Training Loss: {avg_loss}')
# 验证集评估
val_loss = 0.0
model.eval() # 设置模型为评估模式
with torch.no_grad():
for images, labels in valloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
avg_val_loss = val_loss / len(valloader)
val_losses.append(avg_val_loss)
print(f'Epoch {epoch + 1}, Validation Loss: {avg_val_loss}')
# 早停法检查
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
patience_counter = 0
torch.save(model.state_dict(), model_path) # 保存最好的模型
else:
patience_counter += 1
if patience_counter >= early_stopping_patience:
print("早停法生效,停止训练")
break
scheduler.step()主函数
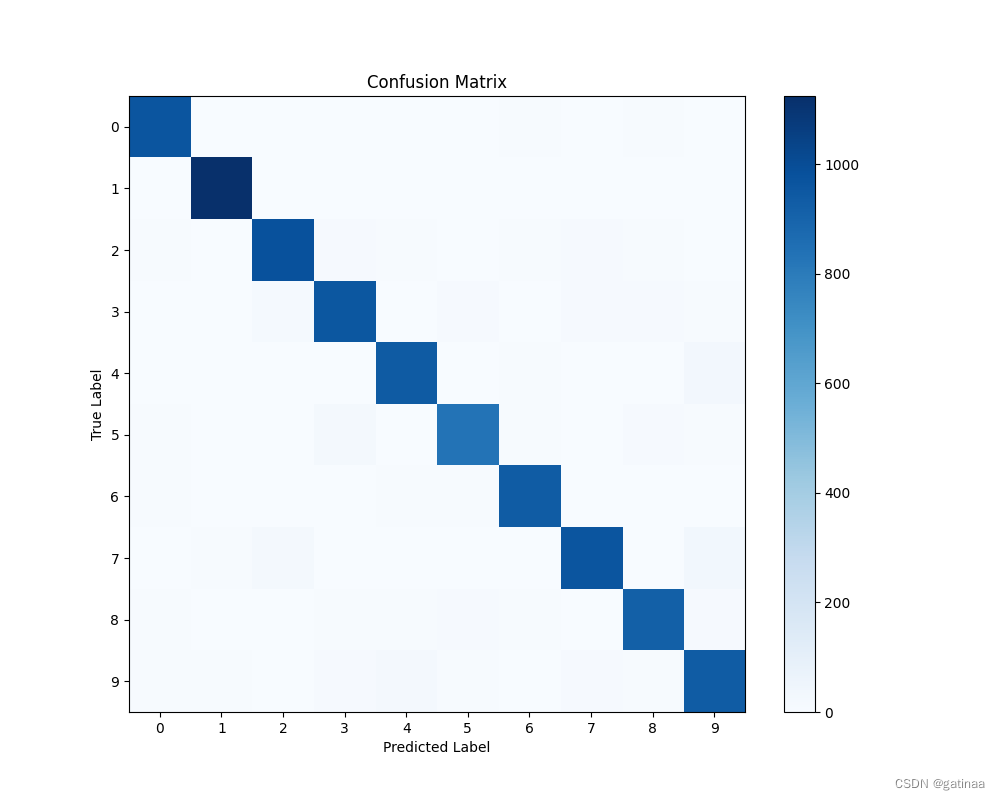
评估模型精度,画出混淆矩阵
if __name__ == "__main__":
correct = 0
total = 0
all_labels = []
all_preds = []
model.eval() # 设置模型为评估模式
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
all_labels.extend(labels.cpu().numpy())
all_preds.extend(predicted.cpu().numpy())
print(f'网络在10000张测试图片上的准确率: {100 * correct / total}%')
# 打印分类报告
print(classification_report(all_labels, all_preds, digits=4))
# 混淆矩阵
cm = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(10, 8))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.colorbar()
tick_marks = np.arange(10)
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.show()Loss函数
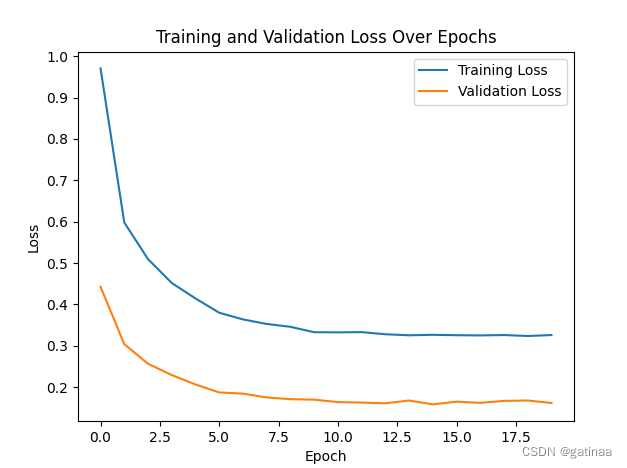
结果
![]()
输出单张测试集图片进行测试
def predict(image_path):
model = BPnet()
model.load_state_dict(torch.load(model_path))
model.to(device)
model.eval()
image = Image.open(image_path).convert('L')
image = image.resize((28, 28))
image = transform(image)
image = image.unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs.data, 1)
return predicted.item()
test_image_path = r"test_image_6_label_4.png"
prediction = predict(test_image_path)
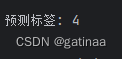
print(f'预测标签: {prediction}')
输入手写体图片,预测标签正确。(实话说我感觉这个写的好丑,真是4吗。。。)

完整代码
# -*- coding=utf-8 -*-
import os
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, random_split
from PIL import Image
from tqdm import tqdm
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix, classification_report
import numpy as np
# 定义数据变换,增加数据增强
transform = transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomCrop(28, padding=4),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 检查是否有可用的GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 指定根目录保存数据
root = './data'
os.makedirs(root, exist_ok=True)
# 下载并加载训练数据
trainset = torchvision.datasets.MNIST(root=root, train=True, download=True, transform=transform)
# 将训练集划分为训练集和验证集
train_size = int(0.8 * len(trainset))#划分验证集,一是用于监控训练过程,帮助识别过拟合和欠拟合现象。
val_size = len(trainset) - train_size #二是为了后面的早停法
train_dataset, val_dataset = random_split(trainset, [train_size, val_size])
trainloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
valloader = DataLoader(val_dataset, batch_size=64, shuffle=False)
# 下载并加载测试数据
testset = torchvision.datasets.MNIST(root=root, train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=64, shuffle=False)
# 定义BP神经网络
class BPnet(nn.Module):
def __init__(self):
super(BPnet, self).__init__()
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(28 * 28, 512)
self.bn1 = nn.BatchNorm1d(512)
self.fc2 = nn.Linear(512, 256)
self.bn2 = nn.BatchNorm1d(256)
self.fc3 = nn.Linear(256, 10)
self.dropout = nn.Dropout(0.5)
def forward(self, x):
x = self.flatten(x)
x = torch.relu(self.bn1(self.fc1(x)))
x = self.dropout(x)
x = torch.relu(self.bn2(self.fc2(x)))
x = self.dropout(x)
x = self.fc3(x)
return x
# 初始化模型
model = BPnet()
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# 模型路径
model_path = 'bpnet_mnist_v3.pth' # 使用新的模型路径
# 早停法参数
early_stopping_patience = 5 # 设定容忍度
best_val_loss = float('inf') # 初始化最佳验证损失
patience_counter = 0 # 容忍度计数器
all_losses = [] # 用于存储每个epoch的训练损失
val_losses = [] # 用于存储验证集每个epoch的损失
# 如果存在模型则加载,否则训练模型
if os.path.exists(model_path):
try:
model.load_state_dict(torch.load(model_path))
print(f'模型已加载自 {model_path}')
except RuntimeError as e:
print(f'加载模型时出错: {e}')
print('重新训练模型...')
else:
# 训练循环
for epoch in tqdm(range(20)): # 设定一个较大的epoch数量,使用早停法提前停止
running_loss = 0.0
model.train() # 设置模型为训练模式
for images, labels in trainloader:
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
avg_loss = running_loss / len(trainloader)
all_losses.append(avg_loss)
print(f'Epoch {epoch + 1}, Training Loss: {avg_loss}')
# 验证集评估
val_loss = 0.0
model.eval() # 设置模型为评估模式
with torch.no_grad():
for images, labels in valloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
avg_val_loss = val_loss / len(valloader)
val_losses.append(avg_val_loss)
print(f'Epoch {epoch + 1}, Validation Loss: {avg_val_loss}')
# 早停法检查
if avg_val_loss < best_val_loss:
best_val_loss = avg_val_loss
patience_counter = 0
torch.save(model.state_dict(), model_path) # 保存最好的模型
else:
patience_counter += 1
if patience_counter >= early_stopping_patience:
print("早停法生效,停止训练")
break
scheduler.step()
# 可视化训练和验证损失
plt.plot(all_losses, label='Training Loss')
plt.plot(val_losses, label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.title('Training and Validation Loss Over Epochs')
plt.savefig("loss.png")
plt.show()
# 定义预测函数
def predict(image_path):
model = BPnet()
model.load_state_dict(torch.load(model_path))
model.to(device)
model.eval()
image = Image.open(image_path).convert('L')
image = image.resize((28, 28))
image = transform(image)
image = image.unsqueeze(0).to(device)
with torch.no_grad():
outputs = model(image)
_, predicted = torch.max(outputs.data, 1)
return predicted.item()
if __name__ == "__main__":
correct = 0
total = 0
all_labels = []
all_preds = []
model.eval() # 设置模型为评估模式
with torch.no_grad():
for images, labels in testloader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
all_labels.extend(labels.cpu().numpy())
all_preds.extend(predicted.cpu().numpy())
print(f'网络在10000张测试图片上的准确率: {100 * correct / total}%')
# 打印分类报告
print(classification_report(all_labels, all_preds, digits=4))
# 混淆矩阵
cm = confusion_matrix(all_labels, all_preds)
plt.figure(figsize=(10, 8))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('Confusion Matrix')
plt.colorbar()
tick_marks = np.arange(10)
plt.xticks(tick_marks, tick_marks)
plt.yticks(tick_marks, tick_marks)
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.show()
# 示例预测
test_image_path = r"test_image_6_label_4.png"
prediction = predict(test_image_path)
print(f'预测标签: {prediction}')
















 5028
5028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











