






作业是完成一个深度神经网络的实验和观察,网络模型不限。实验数据自选。
我的项目环境
平台:windows 11pro
语言环境:python3.7
编译器:pycharm
GPU:RTX4060ti 16g项目来源
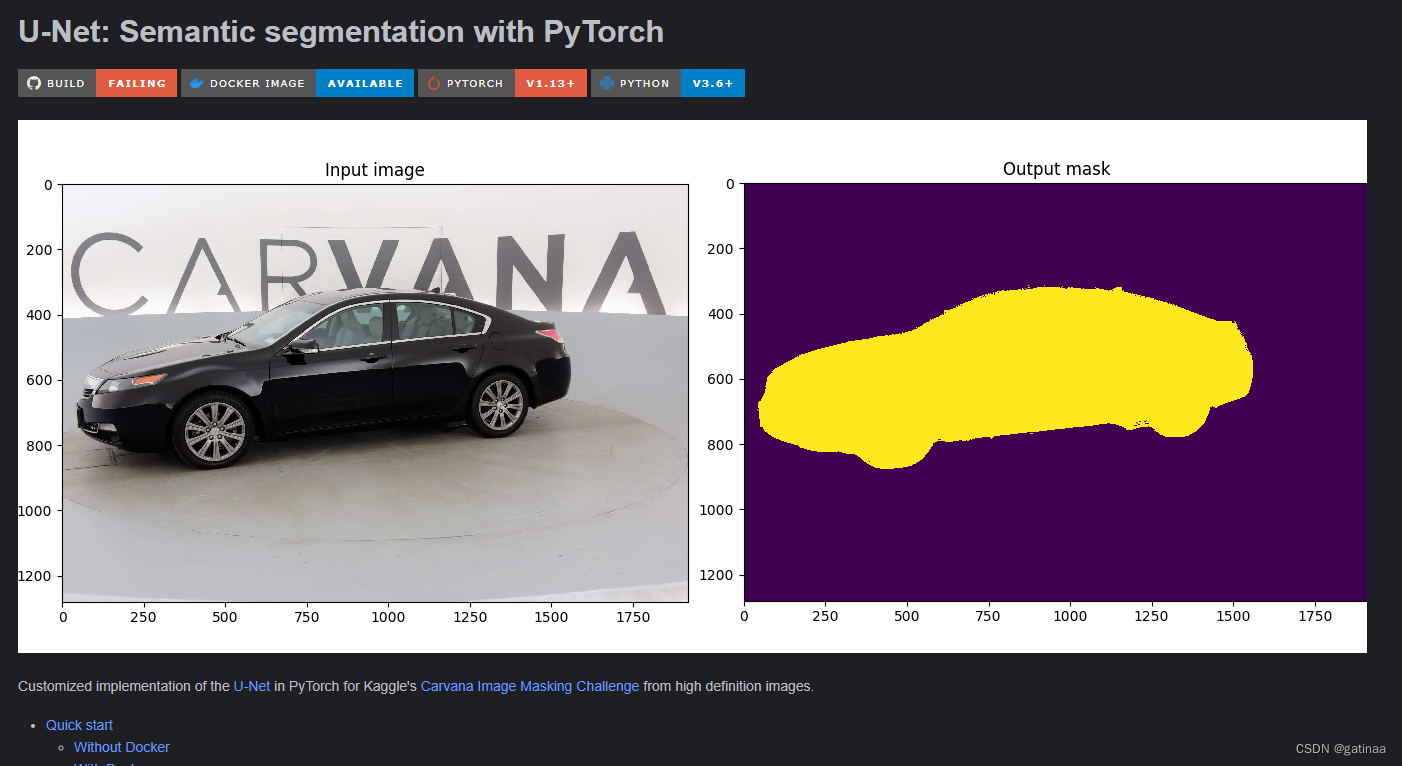
kaggle里的Carvana Image Masking Challenge。

这只队伍从800只队伍中脱颖而出,获得第一名,奖金12000刀,项目在GitHub上开源了。
一、数据集介绍
就不用项目自带的数据集了,挑战一下新的数据集:来自2020年的Kvasir-SEG;
Simula 数据集 - 准 SEG --- Simula Datasets - Kvasir SEG
1.1 数据集的背景
Kvasir-SEG数据集(大小 46.2 MB包含来自 Kvasir 数据集 v2 的 1000 张息肉图像及其相应的 ground truth。Kvasir-SEG中包含的图像的分辨 332x487到1920x1072 像素不等。


二、数据预处理
Kvasir数据跟kaggle提供的数据区别很大,首先数据分辨率大小不一致,需要将图像和掩码数据的分辨率统一为256x256像素,确保在训练过程中数据的一致性。其次掩码数据的channel是3通道的,不同于原有数据集的2通道,需要进行修改。
因为Kavisr的数据量较小,我设置随机旋转变换,增加数据的多样性,提高模型的泛化能力。
由于训练用的loss函数是CrossEntropyLoss,需要在dataload中就配置好标签的限制,确保掩码中的标签值在 [0, num_classes-1] 范围内,避免标签值超出范围。
import numpy as np
import torch
from torch.utils.data import Dataset
from torchvision import transforms
from os import listdir
from os.path import splitext, isfile, join
from pathlib import Path
from PIL import Image
import matplotlib.pyplot as plt
# 定义数据转换
transform = transforms.Compose([
transforms.RandomRotation(5),
transforms.ToTensor(),
])
def keep_image_size_open(path, size=(256, 256)):
img = Image.open(path)
temp = max(img.size)
mask = Image.new('P', (temp, temp))
mask.paste(img, (0, 0))
mask = mask.resize(size)
return mask
def keep_image_size_open_rgb(path, size=(256, 256)):
img = Image.open(path)
temp = max(img.size)
mask = Image.new('RGB', (temp, temp))
mask.paste(img, (0, 0))
mask = mask.resize(size)
return mask
class MyDataset(Dataset):
def __init__(self, images_dir: str, mask_dir: str, scale: float = 1.0, mask_suffix: str = '', num_classes: int = 2):
self.images_dir = Path(images_dir)
self.mask_dir = Path(mask_dir)
self.scale = scale
self.mask_suffix = mask_suffix
self.num_classes = num_classes
self.ids = [splitext(file)[0] for file in listdir(images_dir) if isfile(join(images_dir, file)) and not file.startswith('.')]
if not self.ids:
raise RuntimeError(f'No input file found in {images_dir}, make sure you put your images there')
logging.info(f'Creating dataset with {len(self.ids)} examples')
def __len__(self):
return len(self.ids)
@staticmethod
def preprocess(pil_img, scale, is_mask):
w, h = pil_img.size
newW, newH = int(scale * w), int(scale * h)
assert newW > 0 and newH > 0, 'Scale is too small, resized images would have no pixel'
pil_img = pil_img.resize((newW, newH), resample=Image.NEAREST if is_mask else Image.BICUBIC)
img = np.array(pil_img, copy=True) # 确保创建一个可写的副本
if is_mask:
img = torch.as_tensor(img).long()
else:
img = torch.as_tensor(img).float().permute(2, 0, 1) / 255.0
return img
def __getitem__(self, index):
segment_name = self.ids[index] + self.mask_suffix
segment_path = self.mask_dir / (segment_name + '.jpg')
image_path = self.images_dir / (self.ids[index] + '.jpg')
segment_image = keep_image_size_open(segment_path)
image = keep_image_size_open_rgb(image_path)
# 转换图像和掩码
image = self.preprocess(image, self.scale, is_mask=False)
segment_image = self.preprocess(segment_image, self.scale, is_mask=True)
# 将掩码中的标签值限制在 [0, num_classes-1] 范围内
segment_image = torch.clamp(segment_image, 0, self.num_classes - 1)
return image, segment_image
if __name__ == '__main__':
data = MyDataset(images_dir=r'', mask_dir=r'', num_classes=2)
print(f'读取到的图像个数: {len(data)}')
img, label = data[55]
plt.figure()
plt.subplot(1, 2, 1)
plt.title('images')
print(img.shape)
plt.imshow(img.permute(1, 2, 0).numpy()) # 转换维度并将图像转换为 NumPy 数组
plt.subplot(1, 2, 2)
plt.title('mask')
print(label.shape)
plt.imshow(label.numpy(), cmap='gray') # 直接转换为 NumPy 数组并显示掩码
plt.savefig('output.png') # 保存图像到文件
#plt.show()
此外我加了数据可视化,方便调试和追踪数据集的大小等信息


三、构建U-Net模型
U-Net是一种广泛应用于医学图像分割任务的卷积神经网络架构。针对有限数量的训练数据,U-Net具有较高的准确性和效率。
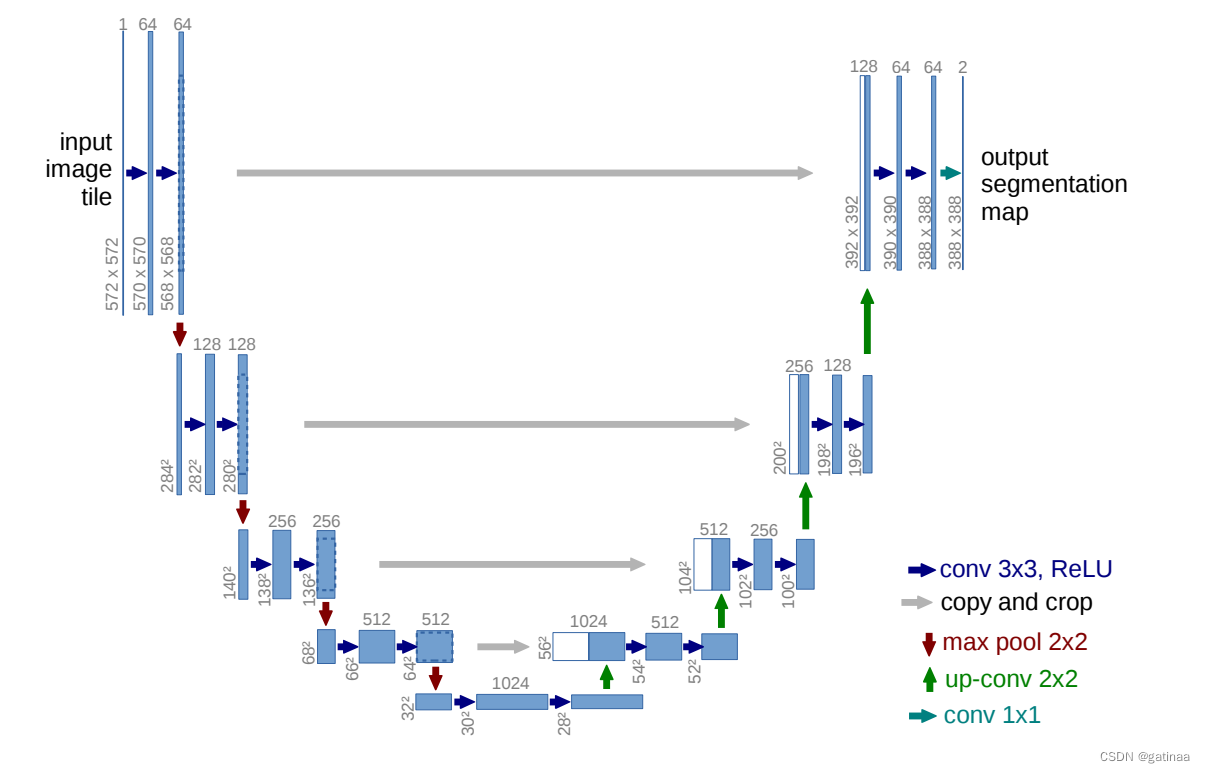
3.1 Unet架构介绍
U-Net的架构可以分为两个主要部分:编码器(Encoder)和解码器(Decoder)。编码器和解码器对称地排列在网络的两侧,形成一个“U”形结构。
编码器(下采样路径)的过程是,先通过每个卷积层使用3x3的卷积核进行卷积操作,并使用ReLU激活函数。通过卷积层之后,利用2x2的最大池化操作将特征图进行下采样,逐步减小特征图的尺寸。
中间跳跃连接层,直接将编码器每层的特征图与对应的解码器层的特征图进行拼接。有利于帮助解码器部分恢复细节信息,避免在上采样过程中丢失空间信息。
解码器(上采样路径)的过程为,先是反卷积层:使用2x2的转置卷积(反卷积)操作进行上采样,将特征图尺寸放大。再利用卷积层,解码器中的卷积层也使用3x3的卷积核和ReLU激活函数。
3.2 代码实现
这个UNet网络在初始化中仅传递num_classes参数,也就是说需要在实例化网络时指定输出的类别数,让输出层需要生成具有num_classes个通道的分割掩码
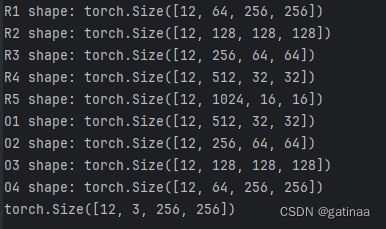
方便调试,我打印出每一层的torch.size来调试
import torch
from torch import nn
from torch.nn import functional as F
#定义卷积块(Conv_Block)
class Conv_Block(nn.Module):
def __init__(self, in_channel, out_channel):
super(Conv_Block, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, 3, 1, 1, padding_mode='reflect', bias=False),
#采用反射填充,减少边缘效应
#偏置(bias)参数是一个可训练的参数,在卷积操作后添加到输出特征图中。有助于提高模型的灵活性。不使用偏置有助于减少模型的参数数量。 且批量归一化层已经通过标准化处理调整了输出。
nn.BatchNorm2d(out_channel),
# 2D 批量归一化
nn.Dropout2d(0.3),
nn.LeakyReLU(),
nn.Conv2d(out_channel, out_channel, 3, 1, 1, padding_mode='reflect', bias=False),
nn.BatchNorm2d(out_channel),
nn.Dropout2d(0.3),
nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class DownSample(nn.Module):
def __init__(self, channel):
super(DownSample, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(channel, channel, 3, 2, 1, padding_mode='reflect', bias=False),
nn.BatchNorm2d(channel),
nn.LeakyReLU()
)
def forward(self, x):
return self.layer(x)
class UpSample(nn.Module):
def __init__(self, channel):
super(UpSample, self).__init__()
self.layer = nn.Conv2d(channel, channel // 2, 1, 1)
def forward(self, x, feature_map):
up = F.interpolate(x, scale_factor=2, mode='nearest')
out = self.layer(up)
return torch.cat((out, feature_map), dim=1)
class UNet(nn.Module):
def __init__(self, num_classes):
super(UNet, self).__init__()
self.c1 = Conv_Block(3, 64)
self.d1 = DownSample(64)
self.c2 = Conv_Block(64, 128)
self.d2 = DownSample(128)
self.c3 = Conv_Block(128, 256)
self.d3 = DownSample(256)
self.c4 = Conv_Block(256, 512)
self.d4 = DownSample(512)
self.c5 = Conv_Block(512, 1024)
self.u1 = UpSample(1024)
self.c6 = Conv_Block(1024, 512)
self.u2 = UpSample(512)
self.c7 = Conv_Block(512, 256)
self.u3 = UpSample(256)
self.c8 = Conv_Block(256, 128)
self.u4 = UpSample(128)
self.c9 = Conv_Block(128, 64)
self.out = nn.Conv2d(64, num_classes, 3, 1, 1)
def forward(self, x):
R1 = self.c1(x)
print("R1 shape:", R1.shape)
R2 = self.c2(self.d1(R1))
print("R2 shape:", R2.shape)
R3 = self.c3(self.d2(R2))
print("R3 shape:", R3.shape)
R4 = self.c4(self.d3(R3))
print("R4 shape:", R4.shape)
R5 = self.c5(self.d4(R4))
print("R5 shape:", R5.shape)
O1 = self.c6(self.u1(R5, R4))
print("O1 shape:", O1.shape)
O2 = self.c7(self.u2(O1, R3))
print("O2 shape:", O2.shape)
O3 = self.c8(self.u3(O2, R2))
print("O3 shape:", O3.shape)
O4 = self.c9(self.u4(O3, R1))
print("O4 shape:", O4.shape)
output = self.out(O4)
print("Output shape:", output.shape)
return output
#测试
if __name__ == '__main__':
x = torch.randn(12, 3, 256, 256)
net = UNet(3)
print(net(x).shape)
打印每一层的输出形状来调试和确认模型是否正确工作;
四、划分测试集、训练集和验证集
由于数据量较小,我划分训练集:测试集:验证集的比例为7:2:1,在训练函数过程中自动划分验证集,就不单独创建文件保存验证集了。
4.1 文件分类代码实现
import os
import shutil
import random
def move_files_with_labels(image_src_dir, mask_src_dir, image_dest_dir, mask_dest_dir, percentage=0.2):
if not os.path.exists(image_src_dir) or not os.path.exists(mask_src_dir):
print(f"Source directories {image_src_dir} and/or {mask_src_dir} do not exist.")
return
if not os.path.exists(image_dest_dir):
os.makedirs(image_dest_dir)
if not os.path.exists(mask_dest_dir):
os.makedirs(mask_dest_dir)
# 获取源文件夹中的所有图像文件
image_files = [f for f in os.listdir(image_src_dir) if os.path.isfile(os.path.join(image_src_dir, f))]
num_files_to_move = int(len(image_files) * percentage)
# 随机选择需要移动的文件
files_to_move = random.sample(image_files, num_files_to_move)
for file_name in files_to_move:
image_src_path = os.path.join(image_src_dir, file_name)
mask_src_path = os.path.join(mask_src_dir, file_name)
image_dest_path = os.path.join(image_dest_dir, file_name)
mask_dest_path = os.path.join(mask_dest_dir, file_name)
if os.path.exists(mask_src_path):
shutil.move(image_src_path, image_dest_path)
shutil.move(mask_src_path, mask_dest_path)
print(f"Moved: {file_name} and its mask")
else:
print(f"Mask for {file_name} not found. Skipping this pair.")
if __name__ == "__main__":
image_source_directory = r"Unet-kvasir\data\Kvasir-SEG\images"
mask_source_directory = r"Unet-kvasir\data\Kvasir-SEG\masks"
image_destination_directory = r"Unet-kvasir\data\Kvasir-SEG\test_images"
mask_destination_directory = r"Unet-kvasir\data\Kvasir-SEG\test_masks"
move_files_with_labels(image_source_directory, mask_source_directory, image_destination_directory,
mask_destination_directory)
五、训练函数
evaluate函数处理了二分类情况和多分类情况,确保了真实掩码的索引在 [0, 1] 范围内,并计算了二分类的 Dice 系数和多分类的 Dice 系数。
5.1 dice函数
Dice 系数用于衡量模型预测与真实标签之间的重叠程度,尤其适用于图像分割任务。它反映了模型在目标区域上的预测精度。
import torch
from torch import Tensor
def dice_coeff(input: Tensor, target: Tensor, reduce_batch_first: bool = False, epsilon: float = 1e-6):
# Average of Dice coefficient for all batches, or for a single mask
assert input.size() == target.size()
assert input.dim() == 3 or not reduce_batch_first
sum_dim = (-1, -2) if input.dim() == 2 or not reduce_batch_first else (-1, -2, -3)
inter = 2 * (input * target).sum(dim=sum_dim)
sets_sum = input.sum(dim=sum_dim) + target.sum(dim=sum_dim)
sets_sum = torch.where(sets_sum == 0, inter, sets_sum)
dice = (inter + epsilon) / (sets_sum + epsilon)
return dice.mean()
def multiclass_dice_coeff(input: Tensor, target: Tensor, reduce_batch_first: bool = False, epsilon: float = 1e-6):
# Average of Dice coefficient for all classes
return dice_coeff(input.flatten(0, 1), target.flatten(0, 1), reduce_batch_first, epsilon)
def dice_loss(input: Tensor, target: Tensor, multiclass: bool = False):
# Dice loss (objective to minimize) between 0 and 1
fn = multiclass_dice_coeff if multiclass else dice_coeff
return 1 - fn(input, target, reduce_batch_first=True)
5.2 evaluate代码实现
# -*- coding=utf-8 -*-
import torch
import torch.nn.functional as F
from tqdm import tqdm
from utils.dice_score import multiclass_dice_coeff, dice_coeff
@torch.inference_mode()
def evaluate(model, dataloader, device, amp):
model.eval() # 设置模型为评估模式
num_val_batches = len(dataloader)
dice_score = 0
with torch.autocast(device.type if device.type != 'mps' else 'cpu', enabled=amp):
for batch in tqdm(dataloader, total=num_val_batches, desc='Validation round', unit='batch', leave=False):
# 解包批次数据
if isinstance(batch, (tuple, list)):
images, true_masks = batch
else:
images, true_masks = batch['image'], batch['mask']
images = images.to(device=device, dtype=torch.float32, memory_format=torch.channels_last)
true_masks = true_masks.to(device=device, dtype=torch.long)
# 预测掩码
masks_pred = model(images)
if model.num_classes == 1:
assert true_masks.min() >= 0 and true_masks.max() <= 1, 'True mask indices should be in [0, 1]'
masks_pred = (F.sigmoid(masks_pred) > 0.5).float()
dice_score += dice_coeff(masks_pred, true_masks, reduce_batch_first=False)
else:
assert true_masks.min() >= 0 and true_masks.max() < model.num_classes, 'True mask indices should be in [0, num_classes)'
true_masks = F.one_hot(true_masks, model.num_classes).permute(0, 3, 1, 2).float()
masks_pred = F.one_hot(masks_pred.argmax(dim=1), model.num_classes).permute(0, 3, 1, 2).float()
dice_score += multiclass_dice_coeff(masks_pred[:, 1:], true_masks[:, 1:], reduce_batch_first=False)
model.train() # 重新设置模型为训练模式
return dice_score / max(num_val_batches, 1)
六、训练函数
6.1 训练函数结构和方法
原项目这个训练函数设计的非常全面,里面包含了数据处理、优化器设置、损失函数选择、模型评估与保存等步骤,适用于深度学习中的图像分割任务,细细学习,收获良多。
优化器
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate, weight_decay=weight_decay, momentum=momentum, foreach=True)
RMSprop优化函数,能够自适应调整学习率和防止梯度爆炸。适合处理非平稳目标。RMSprop能够自适应学习率真的解放双手。
参数更新的公式:

梯度缩放器:
grad_scaler = torch.cuda.amp.GradScaler(enabled=amp)
GradScaler 它能够平衡损失值,防止梯度下溢或溢出,从而提高训练效率并减少显存使用于混合精度训练,能够自动缩放损失以防止数值溢出,提高训练速度和节省显存。但是有可能会影响模型的性能和精度。并且如果缩放因子设置不合适,可能会导致训练不稳定或者梯度更新过小,影响模型收敛。
损失函数:
criterion = nn.CrossEntropyLoss() if model.out.in_channels > 1 else nn.BCEWithLogitsLoss()
如果模型的输出通道数大于1(即多分类问题),使用交叉熵损失 CrossEntropyLoss。
如果模型的输出通道数等于1(即二分类问题),使用带有逻辑回归的二值交叉熵损失 BCEWithLogitsLoss
此外还使用 logging 模块记录训练的各种参数,包括迭代次数、批处理大小、学习率、数据集大小、设备类型、图像缩放比例和是否使用混合精度等信息
由于数据集比较小,所以我在项目原有基础上增加了早停法,忍耐值为7,在多次训练的基础上防止过拟合。
class EarlyStopping:
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt'):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 06.2 训练函数代码
dir_img = Path(r'data\Kvasir-SEG\images')
dir_mask = Path(r'data\Kvasir-SEG\masks')
dir_checkpoint = Path('./checkpoints/')
class EarlyStopping:
def __init__(self, patience=7, verbose=False, delta=0, path='checkpoint.pt'):
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.path = path
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
if self.verbose:
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), self.path)
self.val_loss_min = val_loss
def train_model(
model,
device,
epochs: int = 100,
batch_size: int = 2,
learning_rate: float = 1e-5,
val_percent: float = 1/8, #800*1/8
save_checkpoint: bool = True, # 保存权重
img_scale: float = 1,
amp: bool = False,
weight_decay: float = 1e-8,
momentum: float = 0.999,
gradient_clipping: float = 1.0,
patience: int = 7,
):
dataset = MyDataset(dir_img, dir_mask, scale=img_scale)
n_val = int(len(dataset) * val_percent)
n_train = len(dataset) - n_val
train_set, val_set = random_split(dataset, [n_train, n_val], generator=torch.Generator().manual_seed(0))
loader_args = dict(batch_size=batch_size, num_workers=os.cpu_count(), pin_memory=True)
train_loader = DataLoader(train_set, shuffle=True, **loader_args)
val_loader = DataLoader(val_set, shuffle=False, drop_last=True, **loader_args)
logging.info(f'''开始训练:
迭代次数: {epochs}
批处理大小: {batch_size}
学习率: {learning_rate}
训练集大小: {n_train}
验证集大小: {n_val}
保存检查点: {save_checkpoint}
设备: {device.type}
图像缩放比例: {img_scale}
混合精度: {amp}
早停法容忍度: {patience}
''')
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate, weight_decay=weight_decay, momentum=momentum, foreach=True)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'max', patience=5) # 目标: 最大化 Dice score
grad_scaler = torch.cuda.amp.GradScaler(enabled=amp)
criterion = nn.CrossEntropyLoss() if model.out.in_channels > 1 else nn.BCEWithLogitsLoss()
global_step = 0
early_stopping = EarlyStopping(patience=patience, verbose=True, path=str(dir_checkpoint / 'checkpoint_early_stopping.pth'))
for epoch in range(1, epochs + 1):
model.train()
epoch_loss = 0
with tqdm(total=n_train, desc=f'迭代 {epoch}/{epochs}', unit='img') as pbar:
for batch in train_loader:
images, true_masks = batch
assert images.shape[1] == 3, \
f'网络定义了 3 个输入通道, 但加载的图像有 {images.shape[1]} 个通道。请检查图像是否正确加载。'
images = images.to(device=device, dtype=torch.float32, memory_format=torch.channels_last)
true_masks = true_masks.to(device=device, dtype=torch.long).squeeze(1)
print(f'Max label value in batch: {true_masks.max().item()}')
with torch.autocast(device.type if device.type != 'mps' else 'cpu', enabled=amp):
masks_pred = model(images)
if model.out.in_channels == 1:
loss = criterion(masks_pred.squeeze(1), true_masks.float())
loss += dice_loss(F.sigmoid(masks_pred.squeeze(1)), true_masks.float(), multiclass=False)
else:
true_masks_one_hot = F.one_hot(true_masks, num_classes=args.classes).permute(0, 3, 1, 2).float()
loss = criterion(masks_pred, true_masks)
loss += dice_loss(
F.softmax(masks_pred, dim=1).float(),
true_masks_one_hot,
multiclass=True
)
optimizer.zero_grad(set_to_none=True)
grad_scaler.scale(loss).backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), gradient_clipping)
grad_scaler.step(optimizer)
grad_scaler.update()
pbar.update(images.shape[0])
global_step += 1
epoch_loss += loss.item()
pbar.set_postfix(**{'损失 (每批)': loss.item()})
division_step = (n_train // (0.9 * batch_size))
if division_step > 0:
if global_step % division_step == 0:
val_score = evaluate(model, val_loader, device, amp)
scheduler.step(val_score)
logging.info('验证 Dice 得分: {}'.format(val_score))
val_score = evaluate(model, val_loader, device, amp)
early_stopping(val_score, model)
if early_stopping.early_stop:
logging.info("早停法触发,停止训练")
break
if save_checkpoint:
Path(dir_checkpoint).mkdir(parents=True, exist_ok=True)
state_dict = model.state_dict()
torch.save(state_dict, str(dir_checkpoint / 'checkpoint_epoch{}.pth'.format(epoch)))
logging.info(f'保存检查点 {epoch}!')
def get_args():
parser = argparse.ArgumentParser(description='在图像和目标掩码上训练 U-Net')
parser.add_argument('--epochs', '-e', metavar='E', type=int, default=100, help='迭代次数')
parser.add_argument('--batch-size', '-b', dest='batch_size', metavar='B', type=int, default=1, help='批处理大小')
parser.add_argument('--learning-rate', '-l', metavar='LR', type=float, default=1e-5, help='学习率', dest='lr')
parser.add_argument('--load', '-f', type=str, default=False, help='从 .pth 文件加载模型')
parser.add_argument('--scale', '-s', type=float, default=1, help='图像缩放因子')
parser.add_argument('--validation', '-v', dest='val', type=float, default=1/8, help='用作验证的数据百分比 (0-100)')
parser.add_argument('--amp', action='store_true', default=False, help='使用混合精度')
parser.add_argument('--bilinear', action='store_true', default=False, help='使用双线性上采样')
parser.add_argument('--classes', '-c', type=int, default=2, help='类别数量')
parser.add_argument('--patience', type=int, default=7, help='早停法的耐心值')
return parser.parse_args()
if __name__ == '__main__':
args = get_args()
logging.basicConfig(level=logging.INFO, format='%(levelname)s: %(message)s')
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
logging.info(f'使用设备 {device}')
model = UNet(num_classes=args.classes) # 仅传递 num_classes
model = model.to(device, memory_format=torch.channels_last)
logging.info(f'网络:\n'
f'\t3 输入通道\n'
f'\t{args.classes} 输出通道 (类别)\n'
f'\t{"双线性" if args.bilinear else "反卷积"} 上采样')
if args.load:
state_dict = torch.load(args.load, map_location=device)
model.load_state_dict(state_dict)
logging.info(f'从 {args.load} 加载的模型')
model.to(device=device)
try:
train_model(
model=model,
epochs=args.epochs,
batch_size=args.batch_size,
learning_rate=args.lr,
device=device,
img_scale=args.scale,
val_percent=args.val / 100,
amp=args.amp,
patience=args.patience
)
except torch.cuda.OutOfMemoryError:
logging.error('检测到 OutOfMemoryError! '
'启用检查点以减少内存使用,但这会减慢训练速度。 '
'考虑启用 AMP (--amp) 进行快速且高效的训练'
)
torch.cuda.empty_cache()
model.use_checkpointing()
train_model(
model=model,
epochs=args.epochs,
batch_size=args.batch_size,
learning_rate=args.lr,
device=device,
img_scale=args.scale,
val_percent=args.val / 100,
amp=args.amp,
patience=args.patience
)
七、训练结果
以为要跑一晚上,结果只跑了21个epoch就停了,感觉不妙
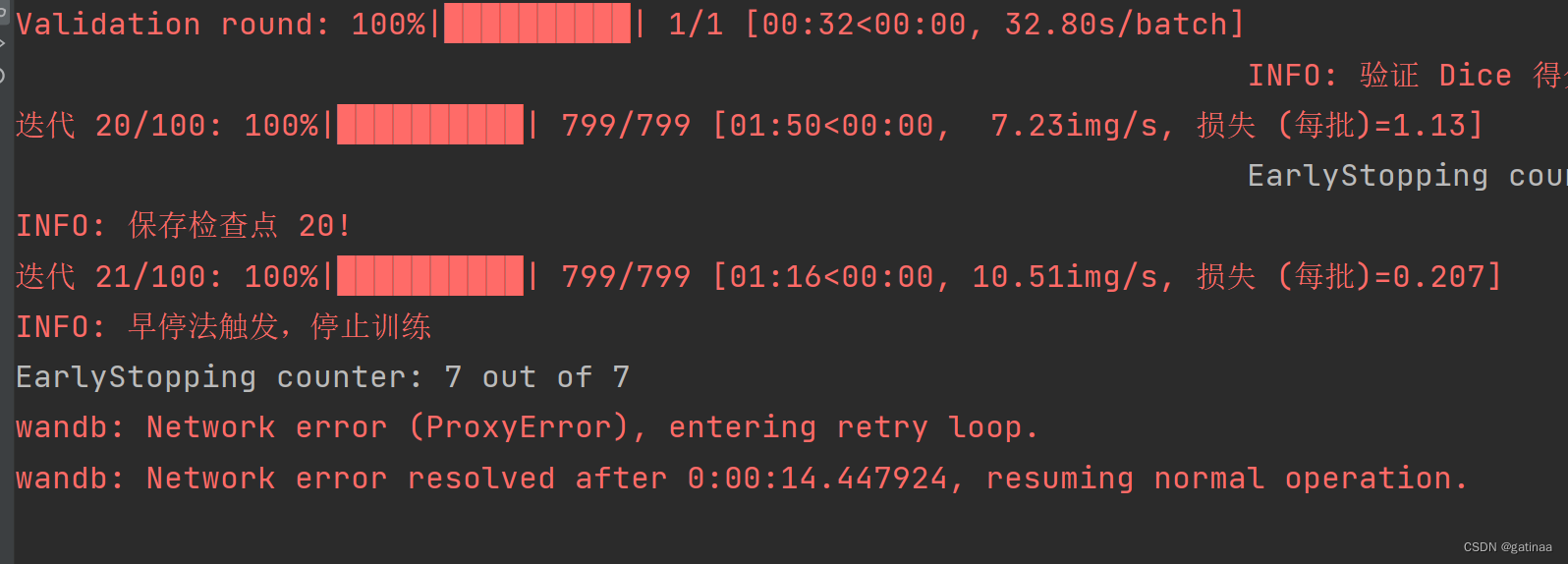
果然,Dice得分有些都快干到0了,
验证一下测试集,可视化测试集的前三张图像,同时计算测试集的平均Dice分数。
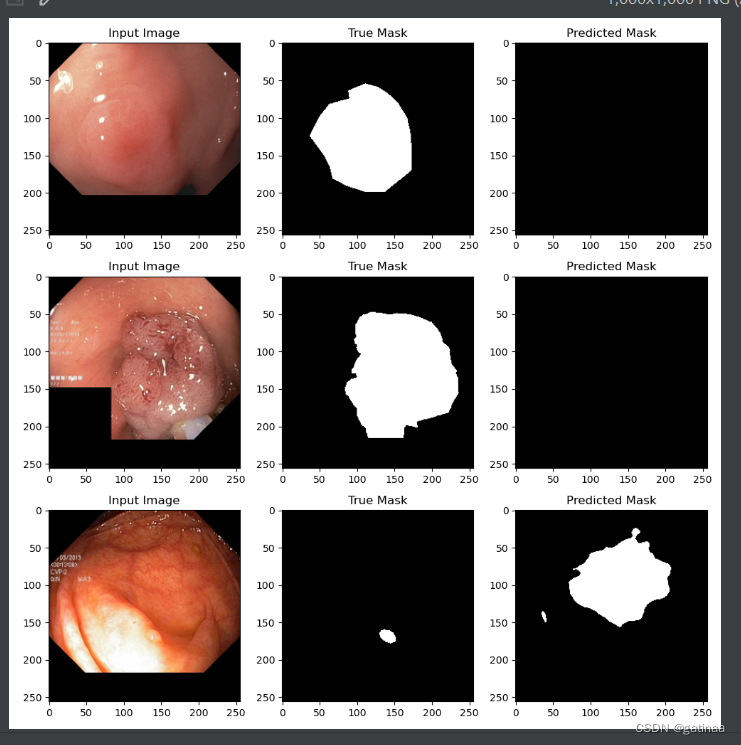

平均得分0.1331,这个结果太差了
这个时候我觉得可能是早停法的容忍度设置小了,7个好像不太够。
——————————————
早停法防止过拟合,但是我这个连收敛都没有,我于是把早停法去掉了,增加了数据集的随即旋转和随机切割,并且在Unet网络加了Res残差模块,本来每层都添加自注意,但是!没想到batch-size设置为1,这都爆显存。于是我只留了中间层的自注意模块,训练了200个epoch
class Res_Block(nn.Module):
def __init__(self, in_channel, out_channel):
super(Res_Block, self).__init__()
self.conv_block = Conv_Block(in_channel, out_channel)
self.shortcut = nn.Conv2d(in_channel, out_channel, kernel_size=1) if in_channel != out_channel else nn.Identity()
def forward(self, x):
residual = self.shortcut(x)
x = self.conv_block(x)
return x + residual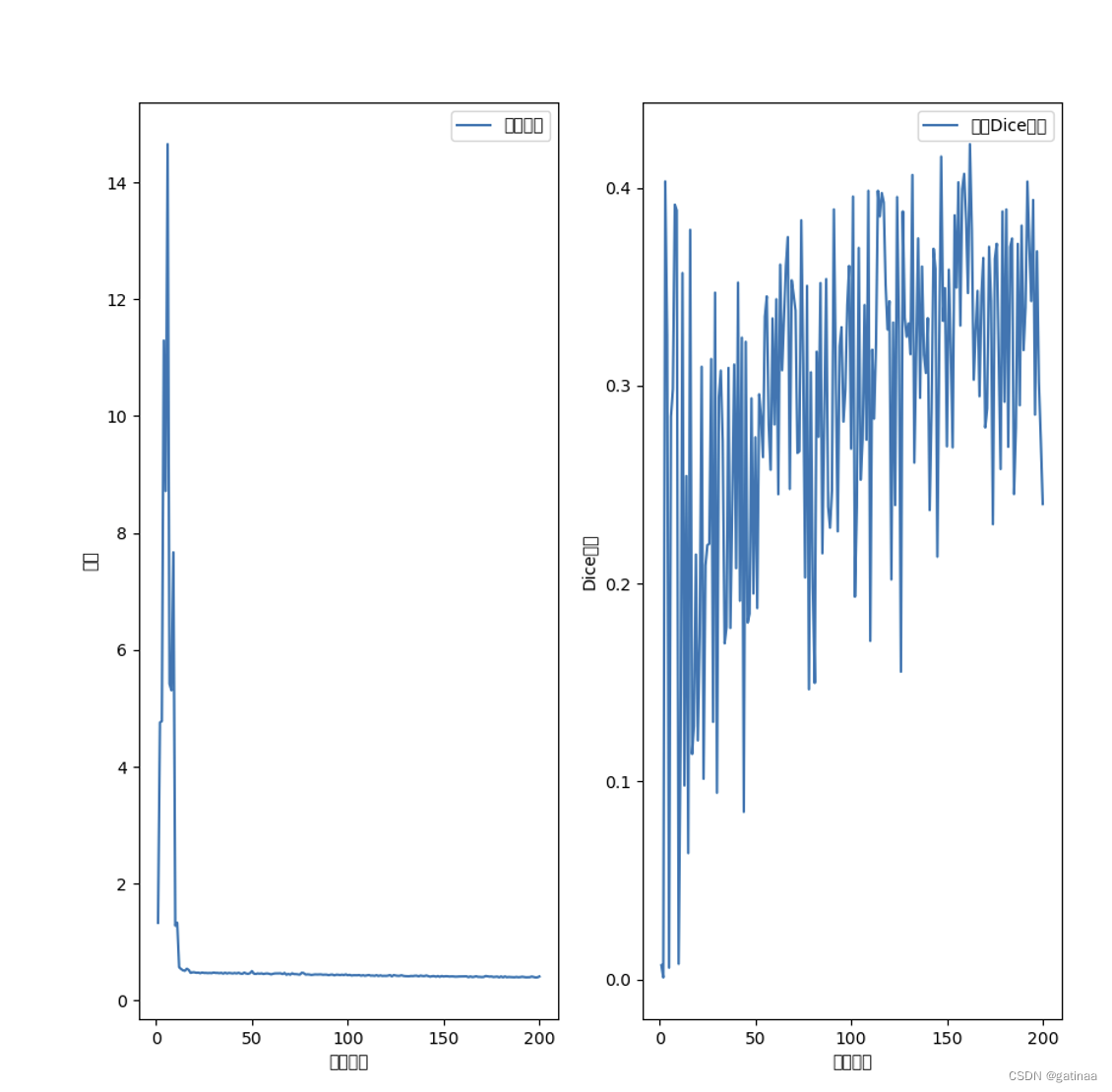
loss到时能收敛了,但是dice得分又太低了
———————————
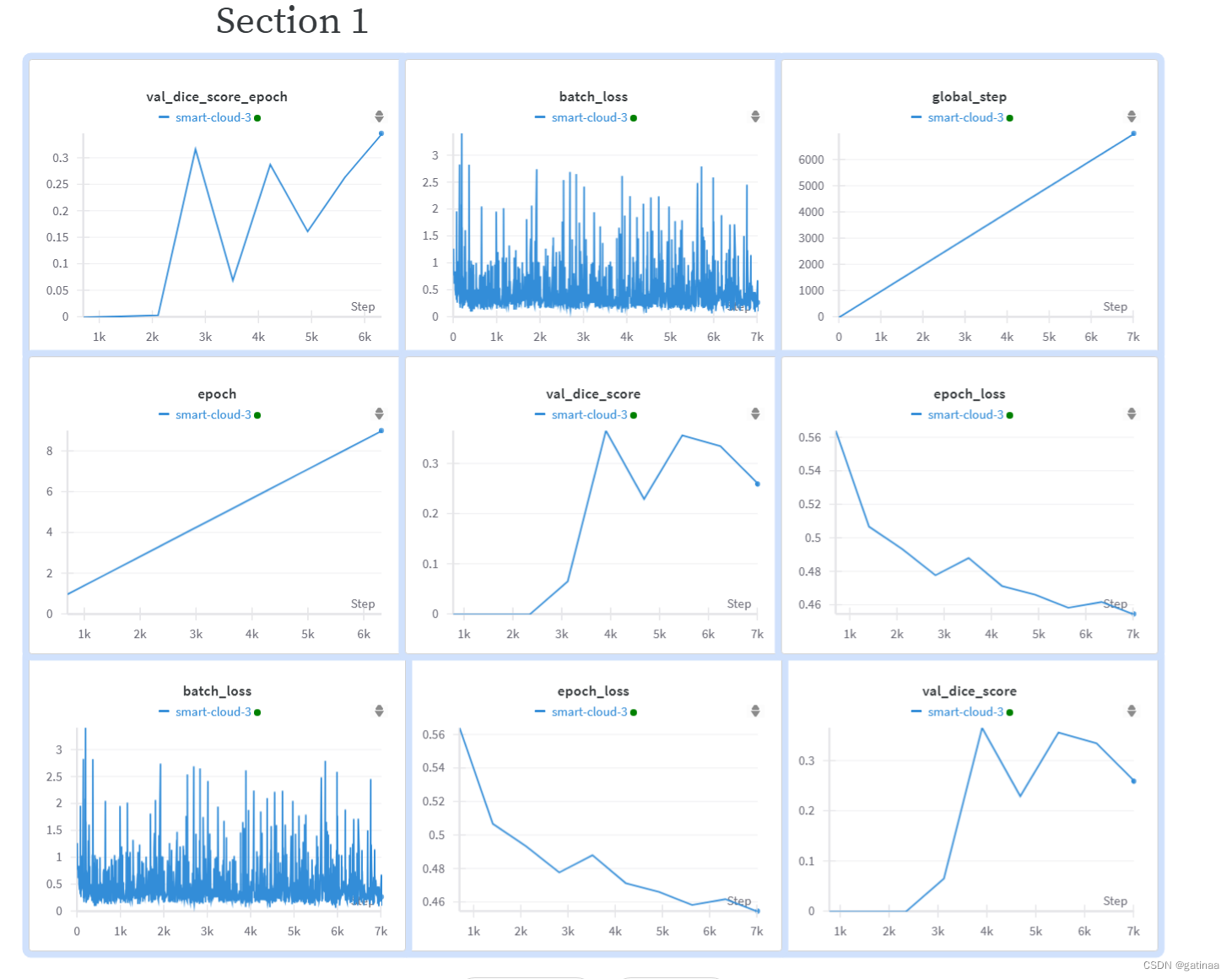
epoch_loss收敛在0.35左右,但是在测试集上表现很差。


















 1574
1574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











