






map系列函数:
map_chr(.x, .f): 返回字符型向量 map_lgl(.x, .f): 返回逻辑型向量
map_dbl(.x, .f): 返回实数型向量 map_int(.x, .f): 返回整数型向量
map_dfr(.x, .f): 返回数据框列表,再 bind_rows 按行合并为一个数据框
map_dfc(.x, .f): 返回数据框列表,再 bind_cols 按列合并为一个数据框
.x 是序列中的一个(代表)元素 .f是对一个元素做的操作
map_*(.x, .f, ...): 依次应用一元函数.f 到一个序列.x 的每个 元素,... 可设置.f 的其它参数
map2_*(.x, .y, .f, ...): 依次应用二元函数.f 到两个序 列.x, .y 的每对元素,... 可设置.f 的其它参数
pmap_*(.l, .f, ...): 依次应用多元函数.f 到多个序列.l 的每 层元素,可实现对数据框逐行迭代,... 可设置.f 的其它参数
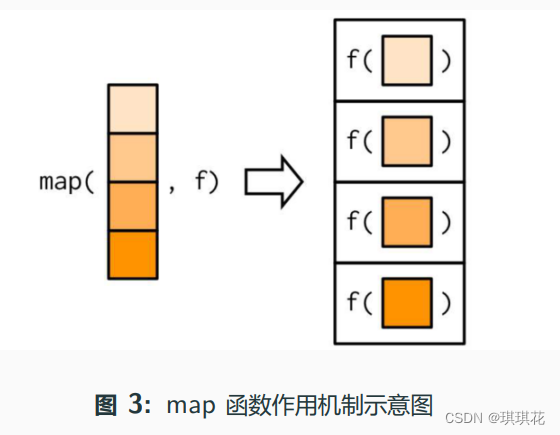
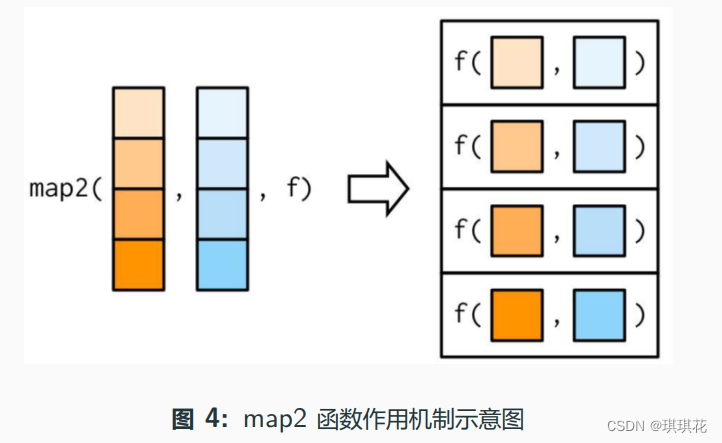
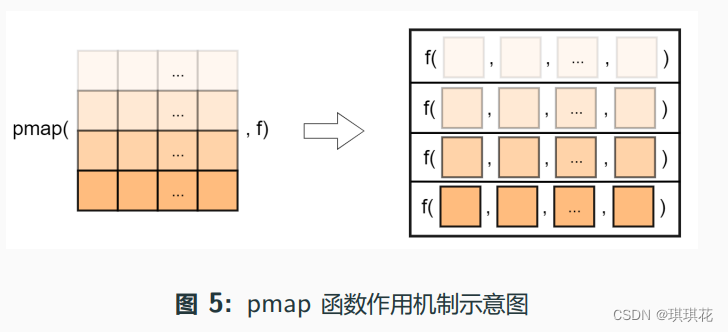
示例:
1 对数据框逐列迭代
df = iris[,1:4]
head(df)
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.1 3.5 1.4 0.2
2 4.9 3.0 1.4 0.2
3 4.7 3.2 1.3 0.2
4 4.6 3.1 1.5 0.2
5 5.0 3.6 1.4 0.2
6 5.4 3.9 1.7 0.4
map_dbl(df, mean) # 求各列均值
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.843333 3.057333 3.758000 1.199333
map_chr(df, mean)
Sepal.Length Sepal.Width Petal.Length Petal.Width
"5.843333" "3.057333" "3.758000" "1.199333"
2 对数据框逐行迭代
df[1:5,]
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.1 3.5 1.4 0.2
2 4.9 3.0 1.4 0.2
3 4.7 3.2 1.3 0.2
4 4.6 3.1 1.5 0.2
5 5.0 3.6 1.4 0.2
pmap_dbl(df[1:5,], ~ mean(c(...))) #逐行平均
2.550 2.375 2.350 2.350 2.550
map_dbl(asplit(df[1:5,], 1), mean)
1 2 3 4 5
2.550 2.375 2.350 2.350 2.550
asplit(df[1:5,],1) #asplit功能展示,其实就是按行分割开来
$`1`
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.1 3.5 1.4 0.2
$`2`
Sepal.Length Sepal.Width Petal.Length Petal.Width
4.9 3.0 1.4 0.2
$`3`
Sepal.Length Sepal.Width Petal.Length Petal.Width
4.7 3.2 1.3 0.2
$`4`
Sepal.Length Sepal.Width Petal.Length Petal.Width
4.6 3.1 1.5 0.2
$`5`
Sepal.Length Sepal.Width Petal.Length Petal.Width
5.0 3.6 1.4 0.2
3 批量读取数据并按行合并
files = list.files("data", pattern = "csv",full.names = TRUE, recursive = TRUE)
files
#> [1] "data/六 1 班学生成绩.csv" "data/六 3 班学生成绩.csv"
#> [3] "data/六 4 班学生成绩.csv" "data/六 5 班学生成绩.csv"
#> [5] "data/新建文件夹/六 2 班学生成绩.csv"
map_dfr(files, read_csv)
#> # A tibble: 20 x 6
#> 班级 姓名 性别 语文 数学 英语
#> <chr> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 六 1 班 何娜 女 87 92 79
#> 2 六 1 班 黄才菊 女 95 77 75
#> 3 六 1 班 陈芳妹 女 79 87 66
#> 4 六 1 班 陈学勤 男 82 79 66
#> 5 六 3 班 江佳欣 女 80 69 75
#> # ... with 15 more rows4 批量绘图并保存图片
以 mtcars 为例,用不同的数值列作为 x 轴,以 mpg 列作为 y 轴,批量 绘制散点图,并保存为以列名命名的 png 文件。
先对一个列名完成绘制散点图
x = "disp"
mtcars %>%
ggplot(aes(.data[[x]], mpg)) + # 管道中列名传参方式
geom_point()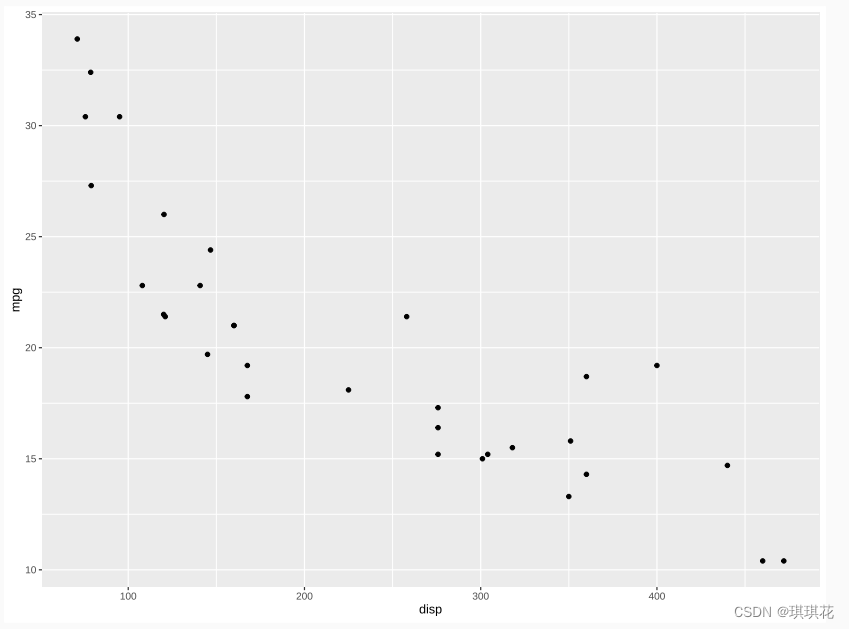
改写为函数
plot_scatter = function(x) {
mtcars %>%
ggplot(aes(.data[[x]], mpg)) +
geom_point()
}
cols = names(mtcars)[2:7] # 要绘制的多个列名
ps = map(cols, plot_scatter) # 批量绘图
files = str_c("images/", cols, ".png") # 准备多个文件路径
walk2(files, ps, ggsave) 
• 其它 purrr 函数
• walk_*() 系列:只循环迭代做事不返回结果,比如批量保存数据/图形 到文件;
• imap_*() 系列:元素与索引一起迭代;
• modify_*() 系列:原地依次修改序列对象;
• reduce()/accumulate(): 可先对序列前两个元素应用函数,再对 结果与第 3 个元素应用函数,再对结果与第 4 个元素应用函数,……前 者只返回最终结果,后者会返回所有中间结果
参考:
GitHub - zhjx19/introR: 这是一本中文 R 语言入门书,基于最新 tidyverse 包。
1 张敬信 《R语言编程:基于tidyverse》(上面的链接是这本书的电子版)
2 (30条消息) 优雅的循环迭代和泛函数编程-purr packages 和 map 函数_purr:map函数_Xiaofei@IDO的博客-CSDN博客















 887
887











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









