







标题:CPR-CLIP:CPR训练中复合错误识别的多模态预训练
源文链接:IEEE Xplore Full-Text PDF:![]() https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10372092
https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=10372092
发表:IEEE SPL(3区)
目录
摘要
医疗技能培训的高昂成本阻碍了医学教育的发展,这引起了智能信号处理领域的广泛关注。为了解决心肺复苏(CPR)培训中的复合错误动作识别问题,本文提出了一种基于提示工程的多模态预训练框架,名为CPR-CLIP。具体而言,我们设计了三种提示,以便在语义层面上自然地融合多种错误,然后通过对比预训练损失来对齐语言和视觉特征。广泛的实验验证了CPR-CLIP的有效性。最终,CPR-CLIP被封装为一个电子助手,并招募了四名医生进行评估。在对比实验中,观察到近四倍的效率提升,这证明了该系统的实用性。我们希望这项工作同时能为智能医疗技能培训和信号处理领域带来新的见解。
关键词——人体动作分析,跨模态交互,动作质量评估,CPR技能培训。
1.简介
总的来说,我们的贡献如下:
- 我们提出了第一个基于提示的预训练框架CPR-CLIP,用于CPR(心肺复苏)培训中的复合错误动作识别;
- 大量的实验结果表明,CPR-CLIP在复合错误识别任务上取得了令人鼓舞的性能;
- 我们将CPR-CLIP模型投入实践以验证其有效性。结果显示,该系统能有效提高医生的工作效率近4倍。
2.提出的方法
CPR-CLIP的结构如图2(a)所示。
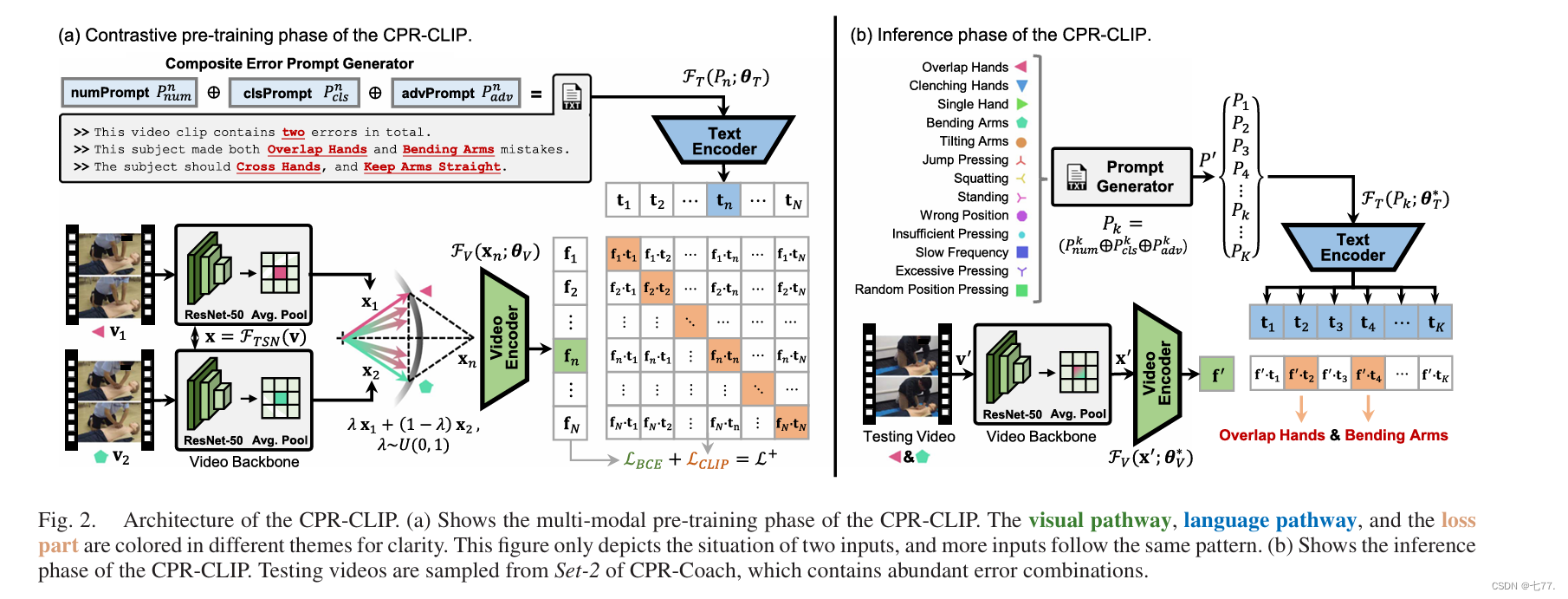
图2。CPR-CLIP的体系结构。(a)显示CPR-CLIP的多模式预训练阶段。视觉通路,语言通路和丢失部分用不同的主题来清晰地表示。该图仅描述了两个输入的情况,更多的输入遵循相同的模式。(b)显示CPR-CLIP的推理阶段。从含有丰富错误组合的CPR-Coach集2中抽取测试视频。
A. 视频特征提取
首先,从数据集中不同类别的单一错误视频类别中采样两个视频(v1, c1)和(v2, c2)。标签c1和c2分别表示视频v1和v2中的错误。注意,采样过程满足c1 ≠ c2。视频v1包含L1帧,视频v2包含L2帧,即。借助如TSN(Temporal Segment Network)[16]这样的视频骨干网络,我们可以将原始视频v映射为视频特征:x = FTSN(v; θTSN),其中x ∈ RT×D,T表示从原始视频x中采样的片段数量,D表示视频特征的维度,θTSN表示视频骨干网络中的参数。
在特征融合阶段,我们采用与[11]相同的配置以进行比较。通过在加权求和中引入随机性λ ∼ U(0, 1)来增强特征组合的多样性后,添加一个时间平均池化操作以获得视频表示:
其中xt1表示视频特征x1的第t行。
最后,通过视频特征编码器FV(·)将融合特征xn转换为最终的视频表示:fn = FV(xn; θV),其中fn ∈ RD,θV表示可训练参数。视觉编码器FV(·)通过一个两层的MLP(多层感知机)网络实现。
“从数据集中不同类别的单一错误视频类别中采样两个视频(v1, c1)和(v2, c2)”:
在训练过程中,通过采样两个不同类别的单一错误视频并进行组合,使得融合的视频特征包含两个类别,才能符合文本特征中“Pnum = “这个视频片段总共包含{cnt}个错误”,训练出一个能够识别和输出多个错误类别的模型。
B. 提示生成与嵌入
人类语言能够自然流畅地表达各种复合信息[28]。受此启发,本文设计了一组用于表达错误动作组合的提示模板。图2(a)详细说明了为“重叠手”和“弯曲手臂”错误生成提示的过程。这组模板从数量、类别和相应建议方面全面描述了特定的错误组合。Number Prompt Pnum、Classes Prompt Pcls和Advice Prompt Padv的详细定义如下:
Pnum = “这个视频片段总共包含{cnt}个错误。”
Pcls = “这个主体同时犯了{c1}和{c2}两个错误。”
Padv = “这个主体应该{a1},并且{a2}。”
其中,{cnt}表示复合错误的数量,它根据训练阶段复合错误的数量而变化。{c1}和{c2}表示特定的错误类别,而{a1}和{a2}分别表示相应的建议。n表示一批次中的第n个样本。
三种类型的提示Pnum、Pcls和Padv通过字符串连接融合成最终的提示Pn:Pn = Pnum ⊕ Pcls ⊕ Padv,其中⊕表示连接操作。类似于视觉路径中的映射过程,提示Pn通过文本编码器映射为嵌入:tn = FT(Pn; θT),其中tn ∈ RD,θT表示文本编码器FT(·)的可训练参数。FT(·)的结构遵循原始CLIP框架[27]的设置:一个具有512个特征维度和8个注意力头的12层Transformer。
C. 对比预训练损失
CPR-CLIP旨在通过自监督的对比预训练机制将视觉和语言特征对齐到相同的语义表示空间中。我们利用CLIP损失来提高网络的性能和可用性。在一个包含N个样本的批次中,通过视觉和语言路径分别获得视觉特征F = {fn}n=1N和文本特征T = {tn}n=1N。fn和tn之间的余弦相似度定义为:。因此,一个批次中的相似度矩阵可以表示为:
通过对S(F, T)的行和列应用softmax归一化函数,我们可以分别获得基于文本的相似度矩阵ST(F, T)和基于视频的相似度矩阵SV(F, T)。之后,根据一个批次内视觉和语言标签的一致性,创建一个Ground-Truth(GT)矩阵MGT ∈ {0, 1}^N×N。在MGT中,视频特征和语言特征匹配的位置填充为1,其他位置填充为0。
采用Kullback–Leibler(KL)散度作为相似度矩阵和MGT之间的度量。CPR-CLIP的多模态对比预训练损失表示为:
尽管LCLIP在训练过程中提供了监督,但它是不够的,因为它属于自监督范式。因此,我们遵循ImageNet[11]中网络头部的设计,并在CPR-CLIP中添加了二元交叉熵(BCE)损失。这个变体被称为CPR-CLIP+,用于提高判别能力。CPR-CLIP+的损失表示为:L+ = LCLIP + LBCE。
D. CPR-CLIP的推理
图2(b)展示了CPR-CLIP推理阶段的细节。在语言路径中,假设存在K种独立的错误类型,我们可以通过上述的提示模板获得一个提示集P_ = {P_k}{k=1}^K。对于第k类,输入提示是通过以下方式获得的:P_k = P_k_num ⊕ P_k_cls ⊕ P_k_adv。之后,通过预训练的文本编码器,我们可以获得与测试提示集P_对应的嵌入集T = {t_k}{k=1}^K:t_k = F_T(P_k; θ*T),t_k ∈ R^D。在视觉路径中,目标视频v_通过视频骨干网络映射为x,然后视频编码器生成对应的视觉特征f:f_ = F_V(x_; θ*V),f ∈ R^D。
在推理期间,等式(2)中的相似度矩阵退化为针对视频特征f_的K维向量,该向量表示f_和T_之间的相似度分数:。CPR-CLIP还支持视频检索模式。给定一个特定的查询提示嵌入t_和整个视频特征集F_,CPR-CLIP生成一个基于视频的相似度向量:S_T(F_, t_)=[sim(f_1, t_),...,sim(f_M, t_)]^T。CPR-CLIP的这一优势可以用于在大型视频集中实现基于自然语言的快速检索功能。
3.实验
4.结论
在这封信中,我们提出了一个名为CPR-CLIP的对比预训练框架,以解决CPR(心肺复苏术)训练中的复合错误识别问题。通过广泛的实验和实际部署,我们证明了在单类训练与多类测试设置下CPR-CLIP的有效性。本研究仅关注外部心脏按压动作的分析,而非CPR的整个流程。未来,我们将继续探索CPR-CLIP在复杂时序医疗动作分析和检索中的应用。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









