






目录
一.如何制作/获取数据集?数据集的格式?
1.自己制作数据集
按照自己的图像分类任务,依次按类收集图片。(百度平台/自行拍摄……)
2.从网上下载免费数据集
AI Studio平台
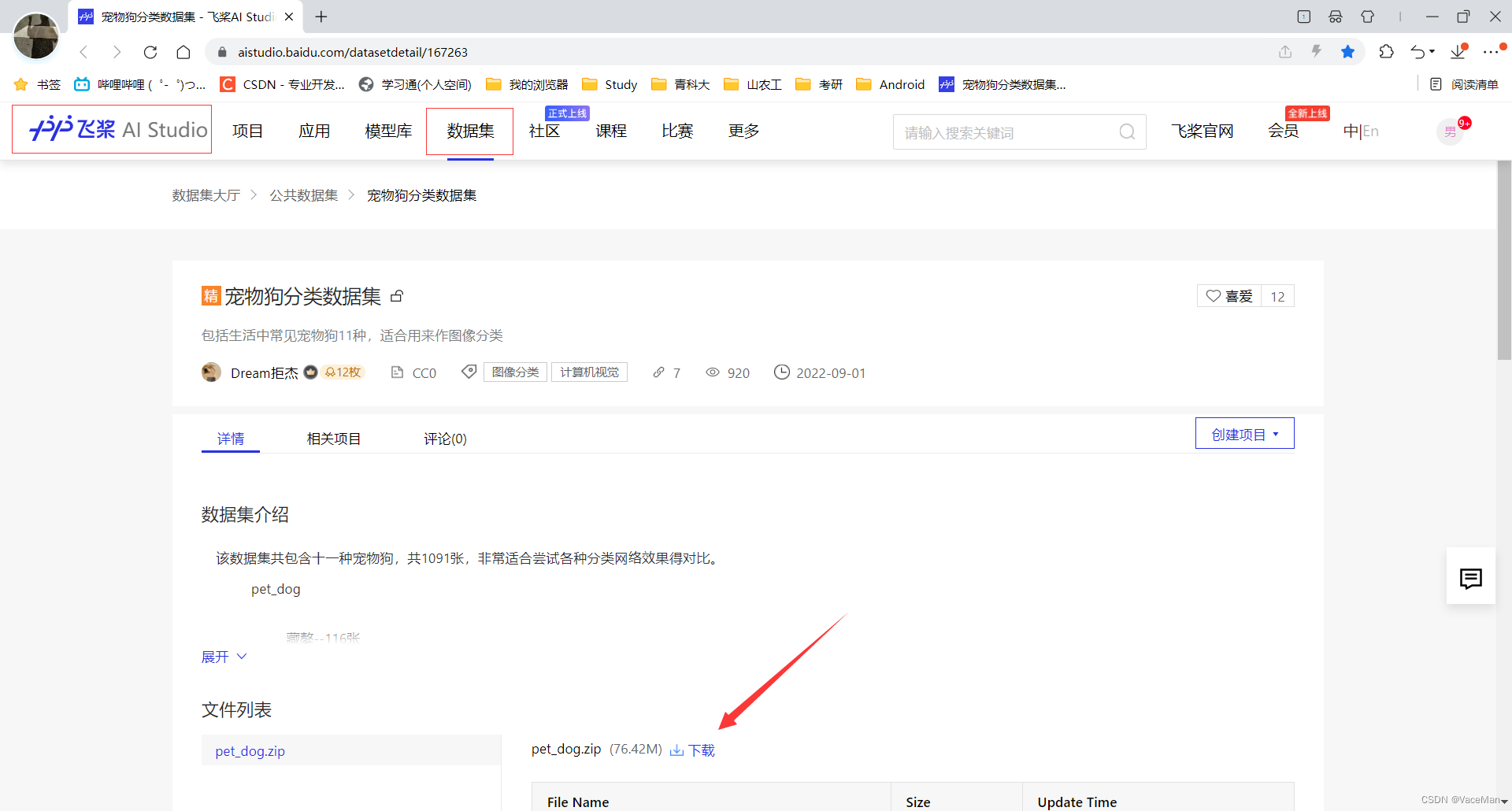
3.数据集的格式?
将平台上下载下来的数据集解压后,如下所示:
数据集(目标类1/目标类2/……目标类n)
二、划分数据集
数据集划分为训练集和测试集。
训练集用来训练模型,测试集用来评价模型。
划分前: 数据集(目标类1/目标类2/……/目标类n)
划分后:(82分、73分)
(训练集:目标类1 70%/目标类2 70%/……/目标类n 70%)
(测试集:目标类1 30%/目标类2 30%/……/目标类n 30%)
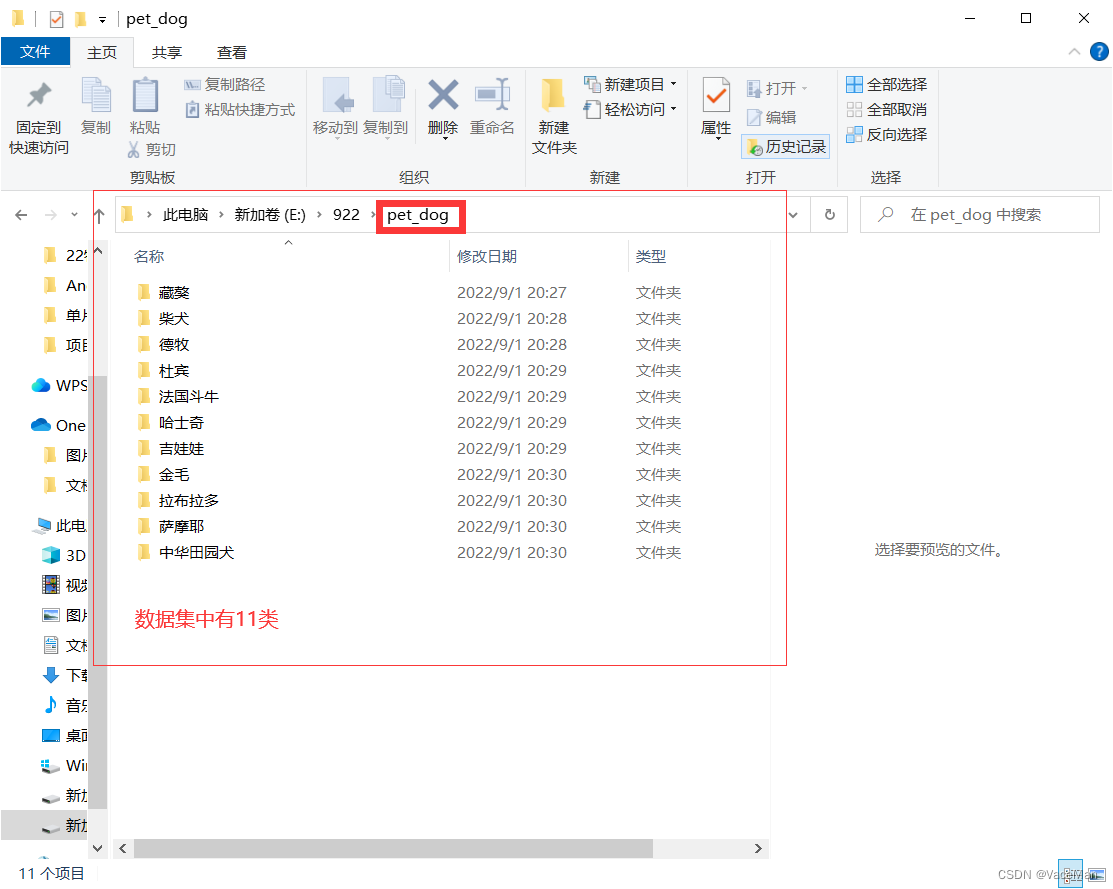
1.选取需要的数据集(以三分类为例)
从11类中选取3类,我想训练一个识别柴犬、拉布拉多和中华田园犬的模型
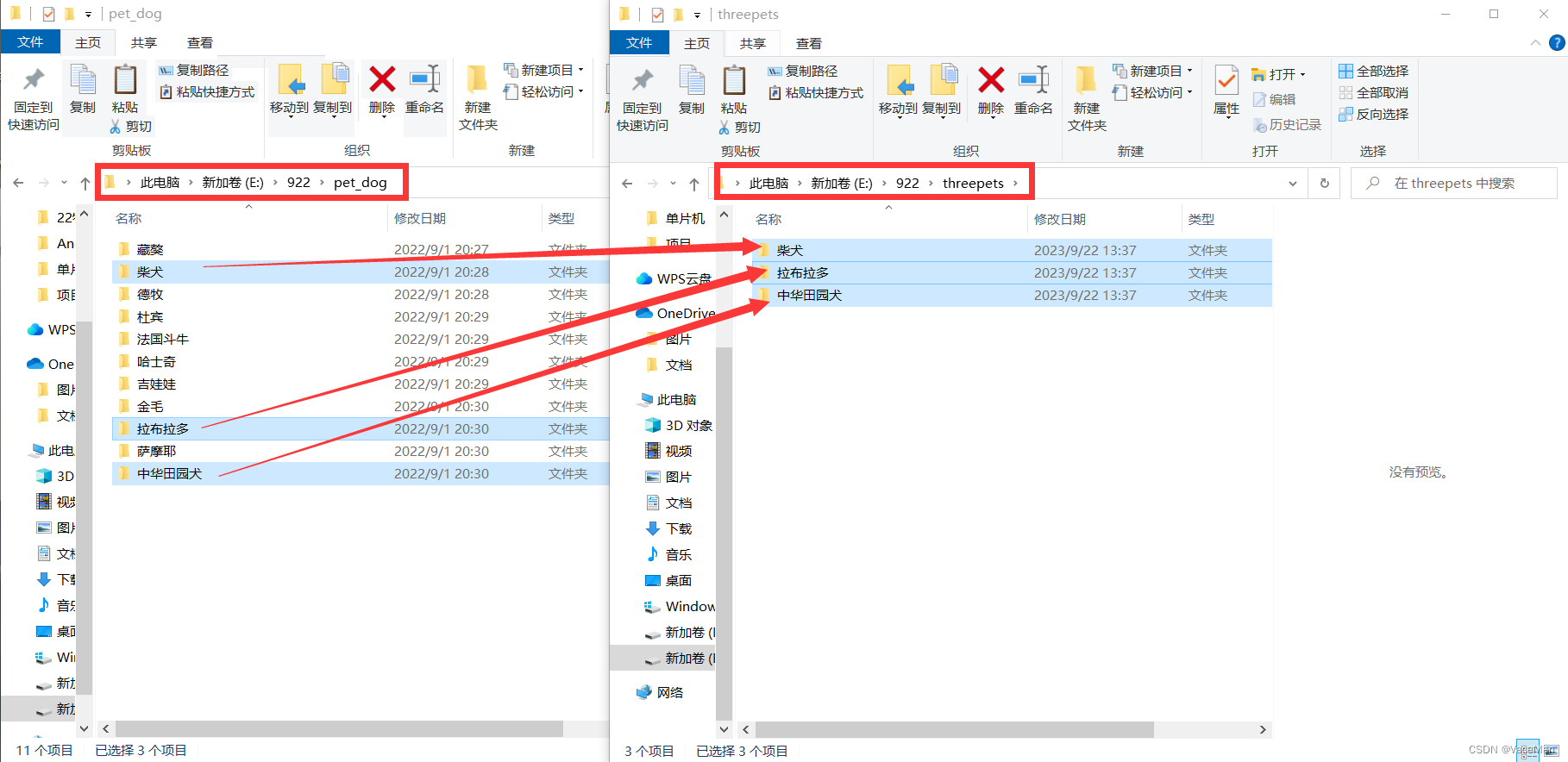
这样,我把解压后的文件夹中的这3个文件夹拿到我待制作的数据集文件夹中,如下图所示:
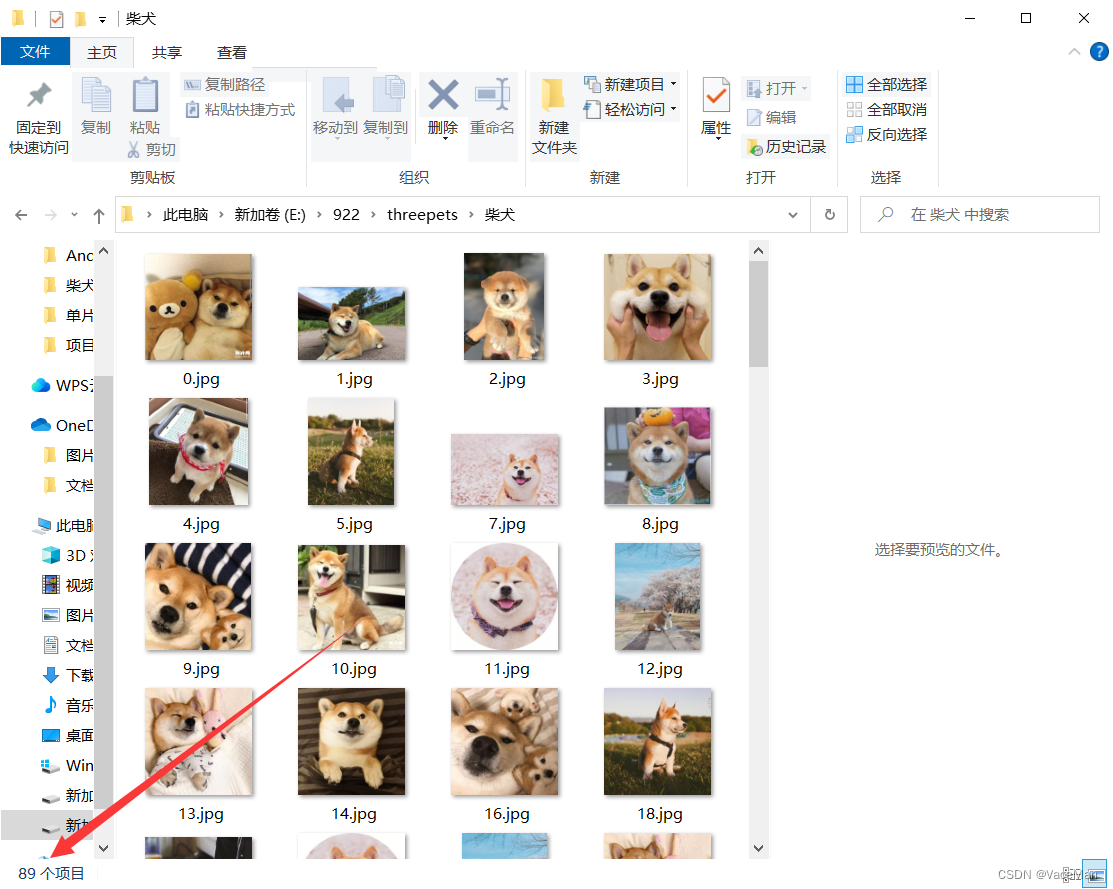
柴犬文件夹照片有89张
2.将数据集划分为训练集和测试集,按照73分
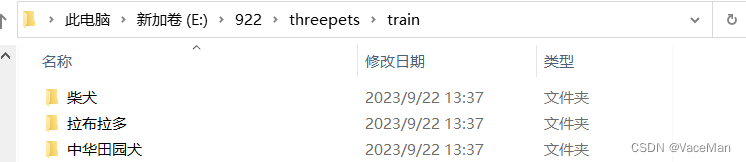
创建train文件夹和test文件夹,将柴犬文件夹、拉布拉多文件夹、中华田园犬文件夹放到train文件夹下。如下图所示:
训练集文件下如下图所示:
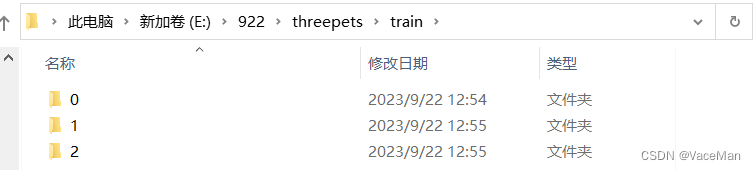
将柴犬文件夹改为0,拉布拉多文件夹改为1,中华田园犬文件夹改为2
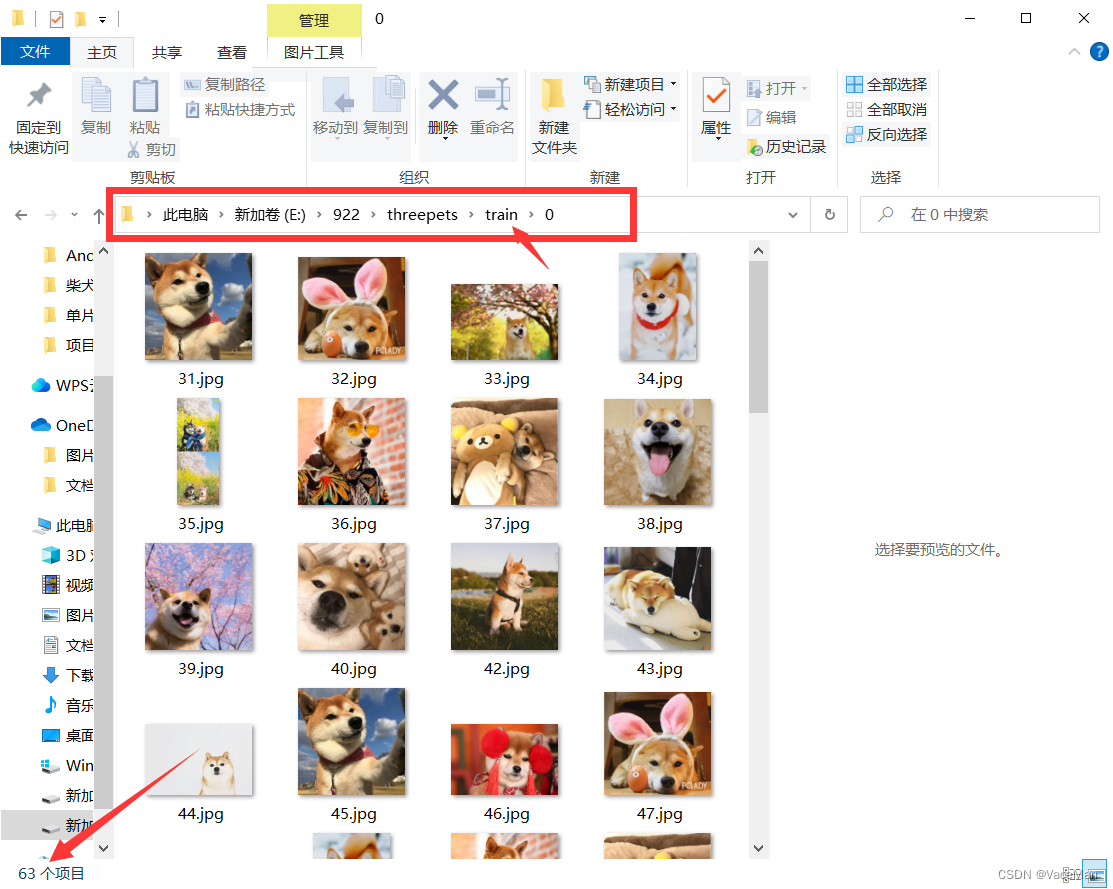
在1中,刚才我们注意到柴犬文件夹有89张,按照73分,训练集:测试集=62.3:26.7
训练集63张,测试集26张
将train文件夹中的柴犬文件夹的图片保留63张,剩余移到test文件夹下的柴犬文件夹下。如下图所示。

上面是0(柴犬)划分后的结果,1(拉布拉多)、2(中华田园犬)同理。
三、图像分类万能模板(基于alexnet的预训练模型)
下面代码只需要修改4处(代码中我已用中文标出),即可使用。
(1)"划分后的训练集文件夹绝对路径" 、 "划分后的测试集文件夹绝对路径"
(2)图像分类任务的分类数
(3)训练轮数
(4)训练后的模型保存路径
from random import shuffle
from matplotlib import pyplot as plt
import torch
import torchvision
import copy
#一、数据集
#1.1图片增强定义
from torchvision import transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])
])
test_transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5],std=[0.5,0.5,0.5])
])
#1.2 datasets
train_dir = r"划分后的训练集文件夹绝对路径"
test_dir = r"划分后的测试集文件夹绝对路径"
train_ds = torchvision.datasets.ImageFolder(
train_dir,
transform=train_transform
)
test_ds = torchvision.datasets.ImageFolder(
test_dir,
transform=test_transform
)
#1.3 dataloader
BATCHSIZE = 32
train_dl = torch.utils.data.DataLoader(
train_ds,
batch_size=BATCHSIZE,
shuffle = True
)
test_dl = torch.utils.data.DataLoader(
test_ds,
batch_size=BATCHSIZE
)
#1.4 输出数据集信息
print("训练集数量:",len(train_ds))
print("测试集数量:",len(test_ds))
#二、创建模型
#2.1 加载alexnet预训练模型
from torch import nn
model = torchvision.models.alexnet(pretrained=True)
for p in model.features.parameters():#卷积层梯度更新冻结
p.requires_grad = False
model.classifier[-1].out_features = 图像分类任务的分类数
print(model.classifier[-1].out_features)
#2.2查看模型信息
print(model)
#三、模型训练与测试
#3.1 train函数
def train(dl,model,loss_fn,optimizer):
size = len(dl.dataset) #数据集总个数
num_batches = len(dl) #总批次数
train_loss, correct = 0,0
model.train()
for x,y in dl: #x,y代表每一批次
x,y = x.to(device),y.to(device)
pred = model(x)
loss = loss_fn(pred,y) #一个批次上的损失
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
#上下文管理器,不会计算梯度
correct += (pred.argmax(1) == y).type(torch.float).sum().item() #累加每一个batch下的正确个数
train_loss += loss.item() #累加每一个batch的loss
correct /= size
train_loss /= num_batches
return correct,train_loss
#3.2 test函数
def test(test_dl,model,loss_fn):
size = len(test_dl.dataset) #数据集总个数
num_batches = len(test_dl) #总批次数
test_loss, correct = 0,0
model.eval()
with torch.no_grad():
for x,y in test_dl: #x,y代表每一批次
x,y = x.to(device),y.to(device)
pred = model(x)
loss = loss_fn(pred,y) #一个批次上的损失
test_loss += loss.item() #累加每一个batch的loss
correct += (pred.argmax(1) == y).type(torch.float).sum().item() #累加每一个batch下的正确个数
correct /= size
test_loss /= num_batches
return correct,test_loss
#3.3 一些参数设置
if torch.cuda.is_available():
model.to('cuda')
loss_fn = nn.CrossEntropyLoss()
optim = torch.optim.Adam(model.classifier.parameters(),lr=0.0001)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
#训练轮数
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
#训练后的模型保存路径,以,pth结尾
PATH = "./alexnet_pre_first.pth"
best_acc = 0
#3.4 训练和测试循环
#4.开始训练
for epoch in range(epochs):
epoch_acc,epoch_loss = train(train_dl,model,loss_fn,optim)
epoch_test_acc,epoch_test_loss = test(test_dl,model,loss_fn)
if epoch_test_acc > best_acc:
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = epoch_test_acc
torch.save(model, PATH)
# torch.save(model.state_dict(),PATH)
train_acc.append(epoch_acc)
train_loss.append(epoch_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ("epoch:{:2d},train_loss:{:.5f},train_acc:{:.1f},test_loss:{:.5f},test_acc:{:.1f}")
print(template.format(epoch+1,epoch_loss,epoch_acc*100,epoch_test_loss,epoch_test_acc*100))
print("Done")
#3.5训练结果打印输出
print("train_acc",train_acc)
print("train_loss",train_loss)
print("test_acc",test_acc)
print("test_loss",test_loss)#这部分是将训练结果绘制图形
plt.plot(range(训练轮数),train_loss,label='train_loss')
plt.plot(range(训练轮数),test_loss,label='test_loss')
plt.legend()
plt.show()
plt.plot(range(训练轮数),train_acc,label='train_acc')
plt.plot(range(训练轮数),test_acc,label='test_acc')
plt.legend()
plt.show()from PIL import Image
#这部分是使用训练出来的模型去预测其它图片
path = r"要预测的图片路径"
#识别种类
classes = ['分类目标0','分类目标1','分类目标n']
#图片处理
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406],std=[0.229,0.224,0.225])
])
#加载预处理模型
model = torch.load(r"训练好的模型文件路径",map_location='cpu')
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
#对图片进行识别
img = Image.open(path)
img = transform(img)
img = torch.unsqueeze(img,dim=0) #增加batch维度
model.eval()
with torch.no_grad():
img = img.to(device)
pred = model(img)
pre_gailv = torch.softmax(pred,dim=1)
pre_label = torch.argmax(pre_gailv).cpu().numpy().item()
print(classes[pre_label])四、训练过程和训练结果
1.训练过程截图
什么软件都可以,下面分别是jupyter lab 和vs code进行训练时的截图
1.1 jupyter lab
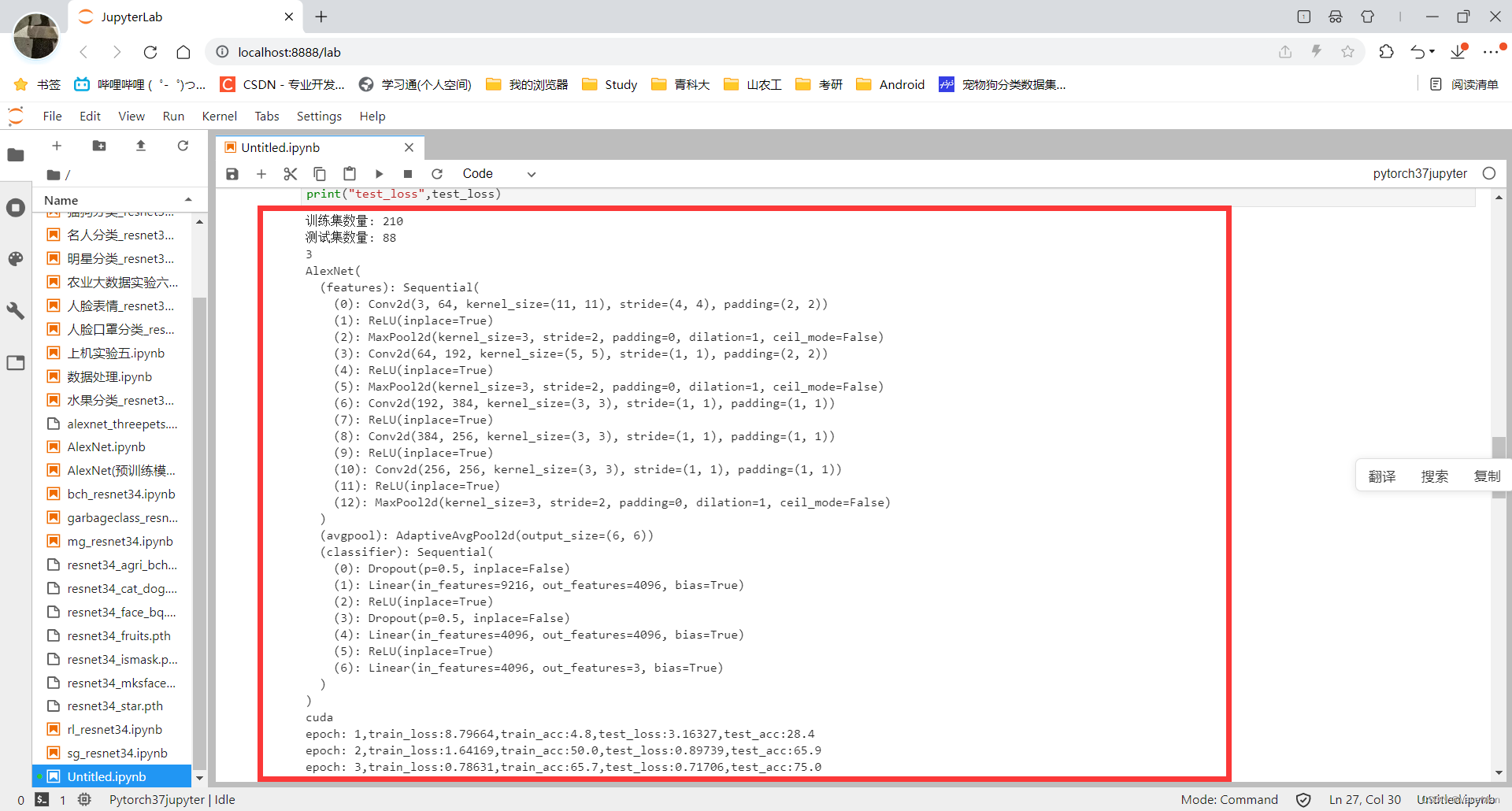
1.2 vs code
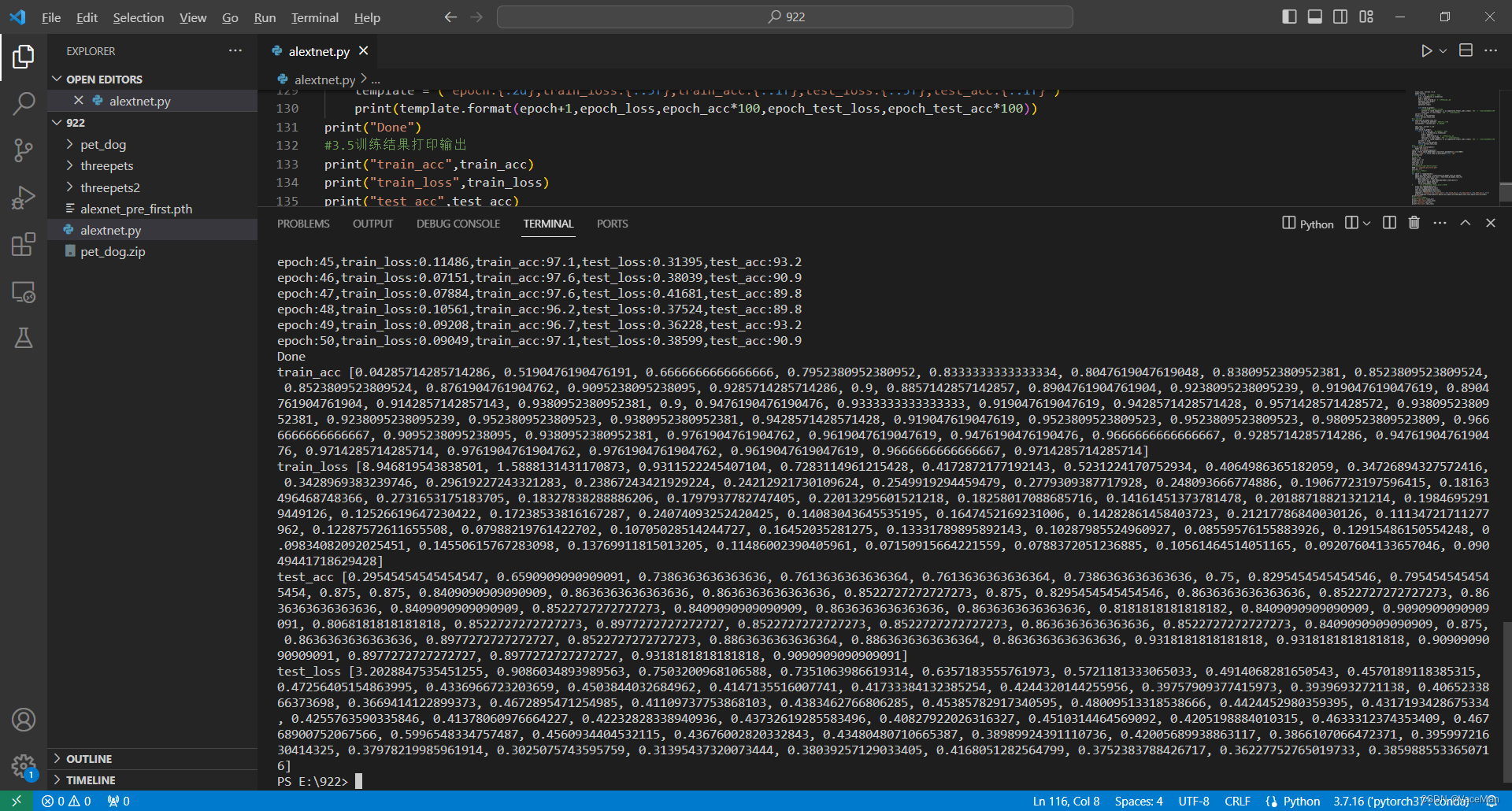
2.训练结果截图
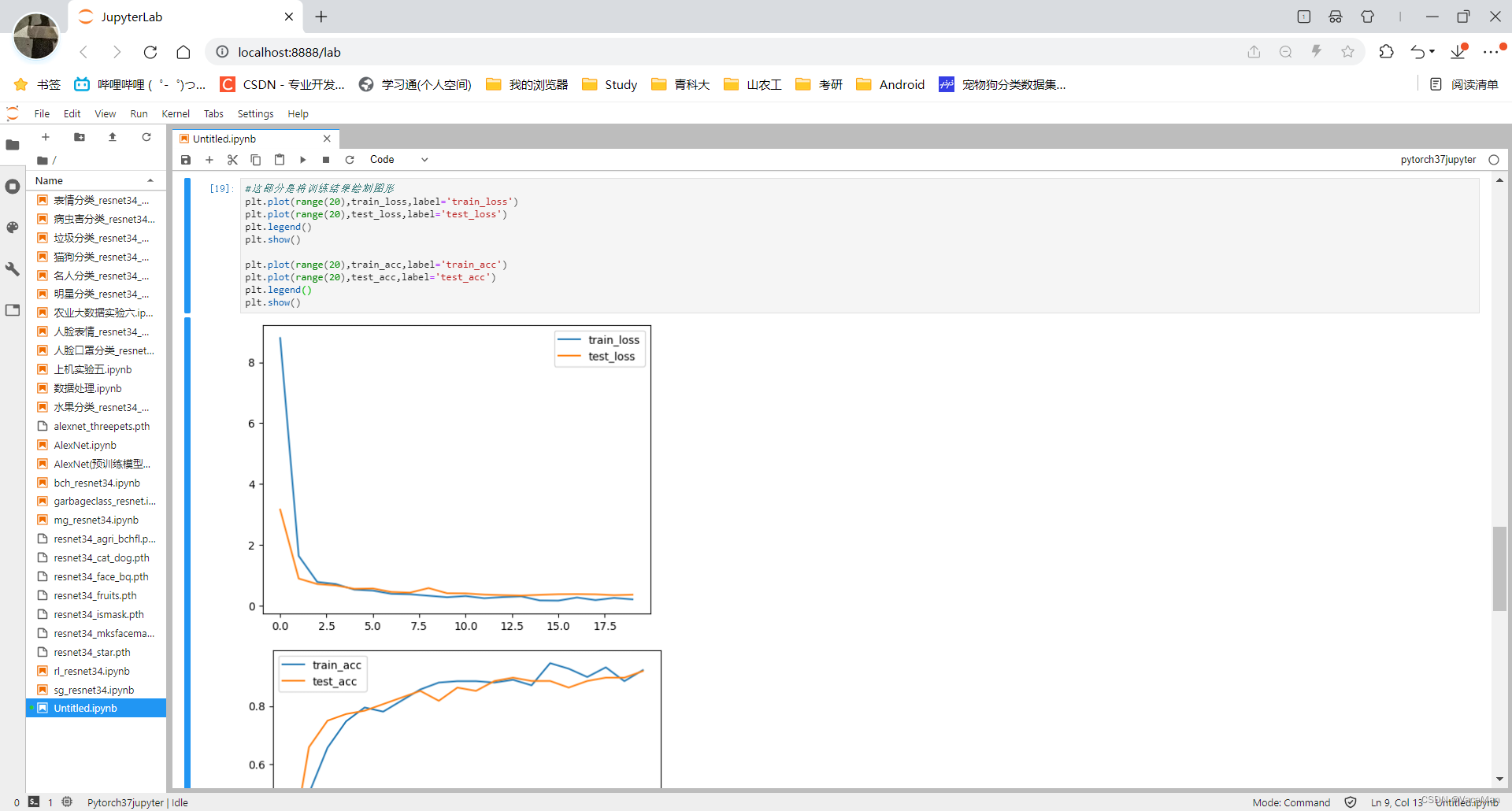
五、用训练出的模型去预测(detect)
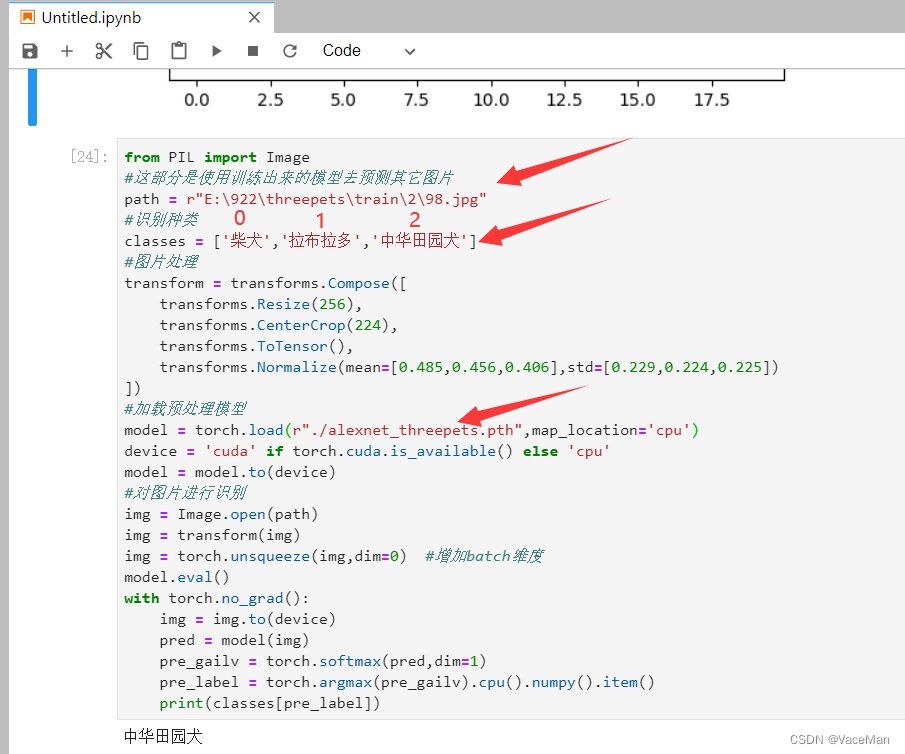















 3317
3317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









