






前言
CNN卷积神经网络
一、Convolutional Neural Network(CNN)
CNN应用于影像上。
假设图片大小相同
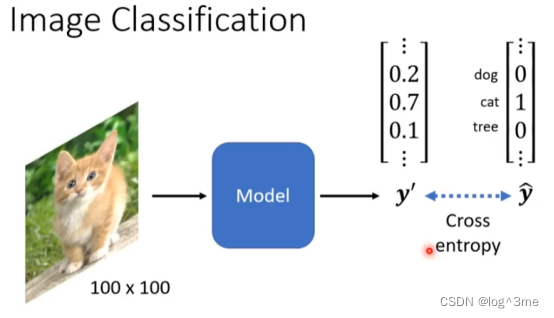
图像分类上模型通过softmax输出y’,希望y’和y~的cross entropy越小越好。
如何将一张影像当做一个模型的输入。对于电脑来说,一张图片是一个三维的张量(tensor),图片的长、宽、和3通道(RGB)。模型的输入都是向量。只要能把图片拉直变成向量,就可以当做模型的输入。
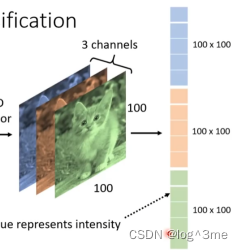
这张图片是1001003的数字所组成的,这些数字就可以组成一个巨大的向量,每一个维度代表某一个位置颜色的强度。
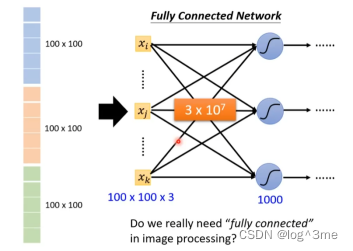
如果第一层neural数目1000个,每一个neural和每一个向量的数值都有一个weight,那么第一层的weight就有3*10000000个。随着参数增加,可以增加模型的弹性,但是也会增加overfitting的风险。
考虑到影像辨识的特性,不一定需要fully connected network,不需要每一个neural都和输入的每一个维度都有一个weight。可能只需要一些特征,就好比人判断一个物体时,也是通过这个物体的一部分特征。
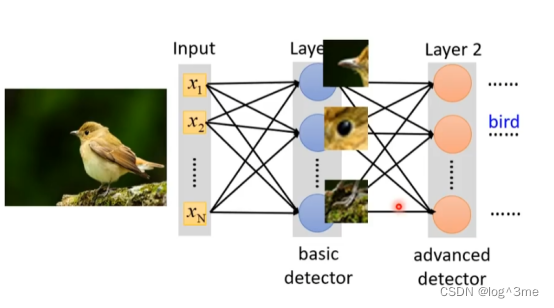
如果只是需要neural判断一个特征是否出现(图片的一小部分),就不需要看一张完整的图片。
基于这个,可以做第一个优化。原来需要每一个neural看图片完整的信息,现在只需要每个neural看每个图片的一小部分。设定一个区域receptive field,每个neural只关注自己的receptive field里面的。
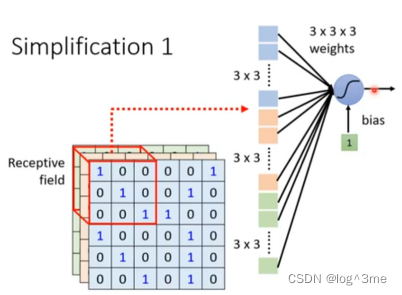
把自己receptive field的数据,变成一个27维的向量,把这个27维度向量当做neural的输入,给每个维度的向量一个weight,再加上bias,输出给下一个neural。
二、划分receptive field
如何划分receptive field,可以多个neural一个receptive field,也可以两个receptive field之间重叠,也可以不同neural不同大小的receptive field,也可以receptive field只包含3个钟的1或2个channels,或者不同形状的receptive field。
最经典的receptive field安排方式
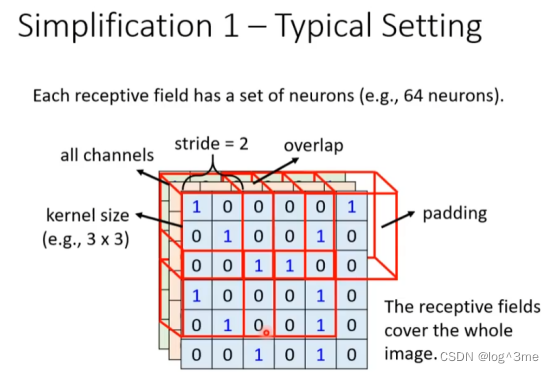
方式1:neural会看所有的channels。所以描述一个receptive field的时候,只用描述宽和高(kernel size),本例的kernel size就是3*3。一个receptive field 一般会有一组neural与之对应。一般会把一个receptive field往右移一点,就会生成一个新的receptive field,移动的量叫做stride(一般是1或者2)。如果一个receptive field在移动后有超出影像范围时,做padding,一般补0或者整张图片的平均值也或者用边边的数字补。
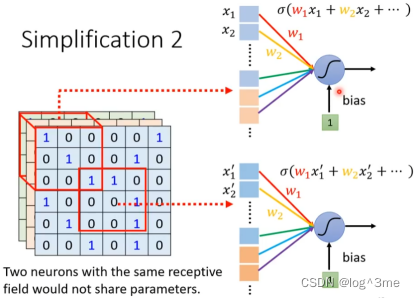
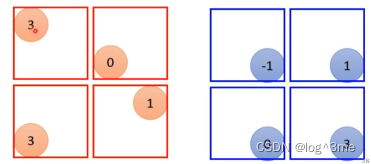
方法二:同一个特征,可能出现在图片不同的位置,不同receptive field 的neural识别的工作可能是相同的,那不同neural之间如果能共享参数(parameter sharing),就可以减少参数量。
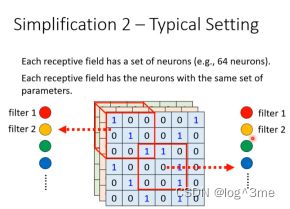
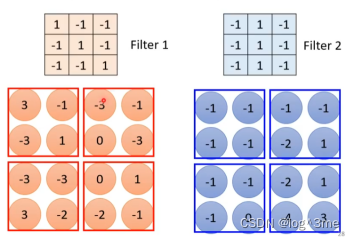
共享参数,两个neural的对应的weight相同。虽然weight一样,但是只要输入不一样,输出就不一样。常见的共享方法,每一个receptive field有一组neural,每个receptive field都只有一组参数,不同receptive field之间,每组的第i个neural公用一样的参数(每一个receptive field都有一组参数,这组参数叫做filter)。
三、卷积层
Receptive field+parameter sharing=convolutional layer(卷积层)
Convolutional layer里面有很多filter,filter大小是33channel(黑白的channel=1,rgb的channel=3)。每个filter去图片抓取一部分。
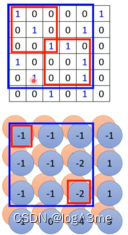
假设channel=1,先把filter放到图片左上角,filter里的9个值和左上角范围内的9各值做相乘,然后往右移一格(stride=1),重复,到filter到右下角。一个filter做完一次这样的运算,会得到一个channels。将这些filter i都扫完图片会得到i群数字,这群数字叫做feature map。
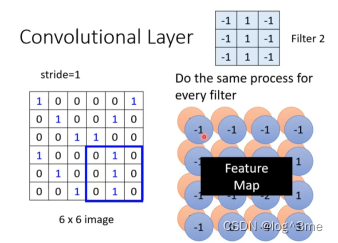
这个feature map可以看做一张新的图片,不过这个图片的channels不在是原始的值了,而是filters的数量。
Convolutional layers可以叠很多层,第二层的filter是33上一层fileters的数量。
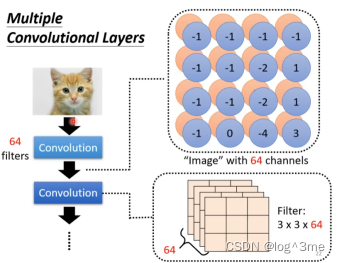
不会出现network看不到大pattern的情况,第二层的convolutional layers上的filter如果设为33,那么对应的是原图的55的范围。neural够深,看到的范围越大。
Pooling(没有要跟数据学任何东西,都是固定好的)
Pooling-max pooling
每个filter产生一堆数字,将这些数字分为多组,如2*2为一组。每个pooling里面选一个代表,max pooling选最大的,mean pooling选平均的。
一般是convolution和pooling交替进行,但pooling可能会对图片造成一定损坏,pooling是可有可无的。
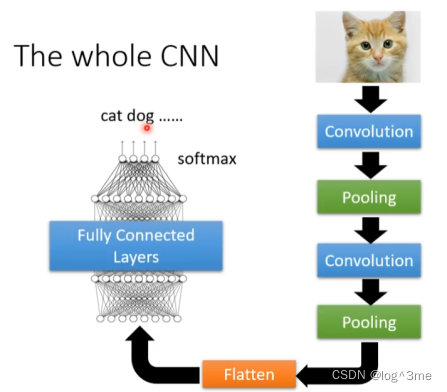
Flatten:把影像里面的东西拉直变为向量。
将向量送入fully connected layers,最后做一个softmax,得出结果。
Pooling不一定适合所有图像处理。
CNN不能处理放大、缩小、旋转后的图像,所以做训练的时候要做data augmentation(数据增强),让cnn看过大小不同、旋转过的pattern。
总结
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7?p=9&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 914
914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









