






文章目录
前言
生成式学习两种策略:各个击破/一次到位
有结构的生成物比如语句、影像、声音等。
一、生成式学习
语句的生成单位:token,在中文中就是一个中文字,在英文中是word piece(比如unbreakable->un break able三个token),比如在gpt中,拆成word piece是可以穷举的,而如果是一个word无法穷举。
影像:像素
声音:16k取样频率,每秒有16000个取样点
二、各个击破和一次到位的对比
1.各个击破(Autoregressive(AR) model)
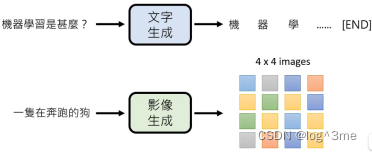
比如gpt,一次生成一个token,图像就一次生成一个像素,最后生成一整个图片。
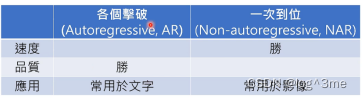
这种方法每一个单位的生成都需要等前面一个单位生成出来,相比于一次到位速度较慢。各个击破的生成品质比一次到位的更好。
2.一次到位(Non-autoregressive(NAR) model)
只要有足够的平信运算能力,就可以很快生成出结果(多用于影像生成)。
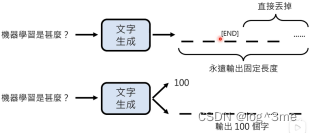
可以固定输出长度,在这个长度内有没有出现结束标志,如果遇到结束标志就结束。也可以先生成一个数字,这个数字表示最终输出的长度。
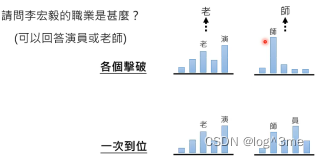
各个击破第一个输出可以使老也可以是演,sample的结果可能是概率高的也可能是概率低的,第二个输出的就相比来说比较稳定。但如果是一次到位,输出的结果可能是“老员”,不是一个正确的答案。这也就是为什么各个击破的质量比较好。
对比:
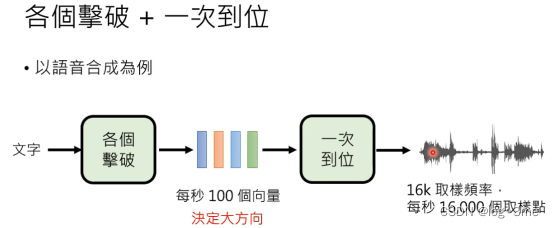
将两者结合起来,先用各个击破生成中间产物,最后用一步到位把结果产生出来。这样可以将两者的优点结合起来。
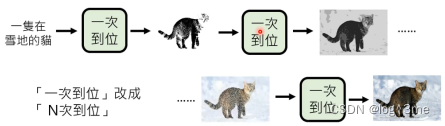
也可以把一次到位改成多次到位,每次的一次到位决定一个大方向,这样就不会出现不知道选哪一个答案,而把两个答案综合起来的问题。(diffusion model)
总结
视频学习地址:https://www.bilibili.com/video/BV1TD4y137mP?p=15&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









