






前言
大模型+大资料
大模型的顿悟时刻
一、大模型的发展趋势
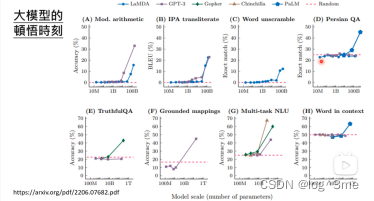
随数据量增加,模型可以从量变达到质变,从某一刻开始突然学会东西。
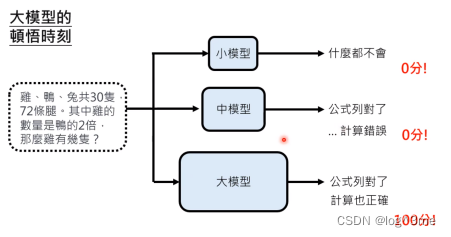
当成为大模型时,分数会从0,0突然变成100,完成“顿悟”.
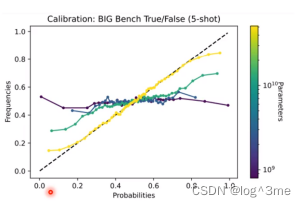
横轴表示分布中产生答案的概率(信心分数),纵轴表示答案正确的概率。可以发现小模型的信心分数跟答案正确的概率关系不大;而对于大模型,信心分数越高,答案正确的概率越大。当模型够大时,才具有calibration的能力。
现在大模型的发展趋势是,不一定要更大的模型,再算力没有跟上之前,也许需要的是更多的训练资料。
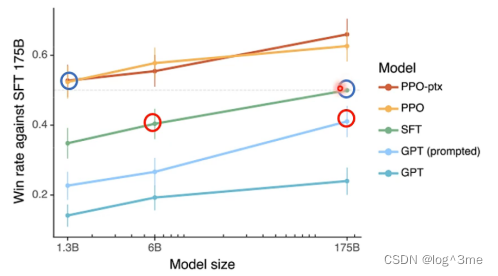
经过微调的小模型是有可能比大模型的效果好的。一个小模型做人类老师的supervised learning,在做更多reinforce learning是可以比大模型好的。如果小模型可以做人类老师给的回馈和reinforce learning是可以比大模型相当的。
Gpt相较于其他大模型成功的原因,可能是这个线上的api,人类不断去玩这个模型,这样openAI知道人类面对一个大型语言模型时会问什么问题。
二、KNN LM
一般的语言模型,实际上就是做一个分类的问题,把下一个字预测出来。
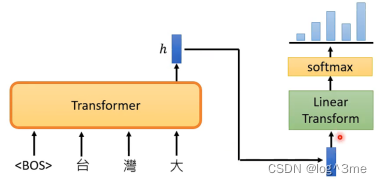
经过transformer,输出一个向量h,根据h做一个分类问题,得到一个概率分布,根据这个分布sample出答案。
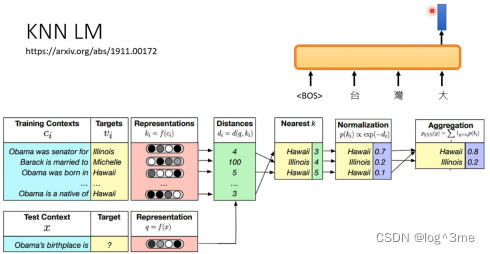
KNN LM训练时,先把所有训练资料的前半句都输入模型,这样会得到一堆representation,还有这些representations应该对应的正确的词汇是什么。计算这两者的相似度(距离),选出距离比较小的k个向量,将这k个向量对应的字找出来,把这几个字转换成一个概率分布,将相同的字合并概率,得出最终的一个概率分布。
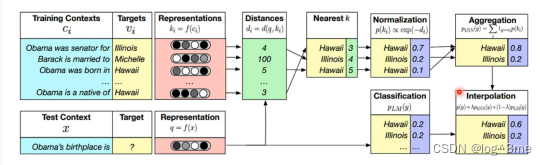
单用KNN LM可能是不够的,还是要用一般的语言模型得到的概率和KNN LM得到的概率做加权平均得到最终的结果。
这样做的好处时,如果模型碰到一些生僻的词汇,它不会把那些生僻词汇当做一个类别。另一个好处是,训练资料可以比一般的语言模型的资料更为巨大,因为放在training contexts里面的资料不一定只是你的训练资料,可以把所有能找到的资料都放进去。
总结
学习视频来源:
1.
https://www.bilibili.com/video/BV1TD4y137mP?p=29&vd_source=3a369b537e1d34ff9ba8f8ab23afedec
2.
https://www.bilibili.com/video/BV1TD4y137mP?p=30&vd_source=3a369b537e1d34ff9ba8f8ab23afedec
3.
https://www.bilibili.com/video/BV1TD4y137mP?p=31&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 434
434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









