






前言
李宏毅机器学习视频p3学习日志
一、Piecewise Linear
在机器学习的第一步中通过linear models画出的线永远是一条直线,无法画出一条折线/曲线(红线)。Linear models:y=b+∑wj*xj
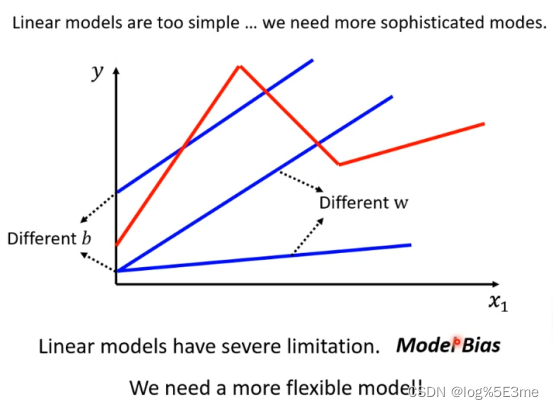
这种来自model的限制叫做Model Bias.
而当x和y的关系很复杂时,为解决linear models,要写一个含有未知参数的函数Piecewise Linear。
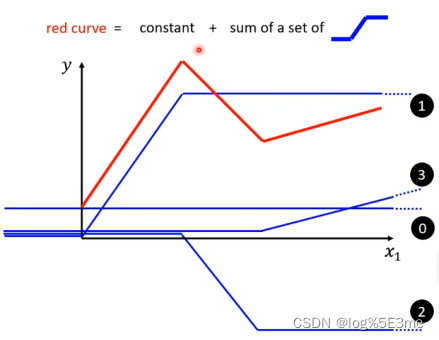
可以把红线看做由一个常量+多个函数组成。
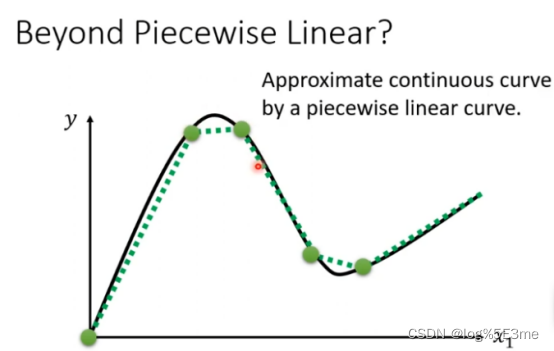
可以用piecewise linear逼近任何有弧度的曲线,只要点取得够多/合适。每一段piecewise linear都可以用足够多的linear组合而成。
如何画出蓝色曲线:把蓝色线 看做sigmoid function不断逼近的一条线。
函数内容:
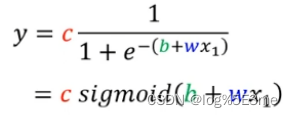
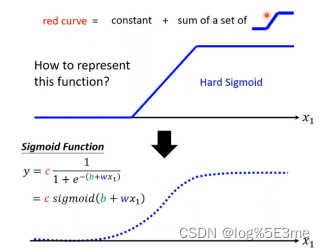
不断调整b、w、c就可以调整出各种样子的sigmoid function。改变w:改变斜率/坡度。改变b:左右移动。改变c:改变高度。
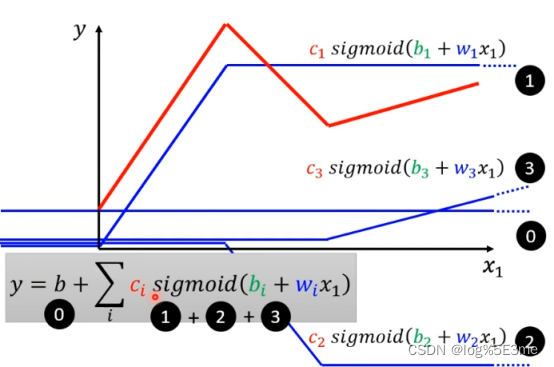
可以通过

来写一个linear model。
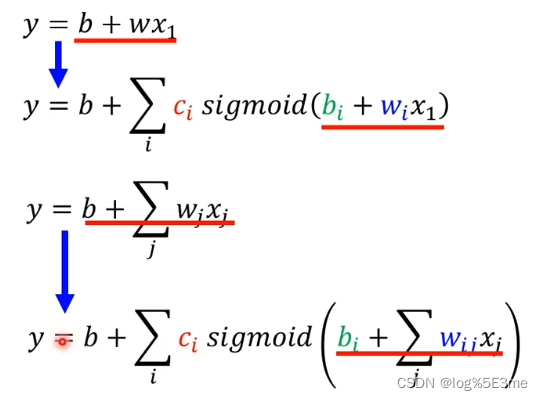
i表示第i个sigmoid function。
也可以看做

向量r=向量b+向量w*向量x。

而未知的所有参数(W,数值b,向量b,c转置)统称为Θ。
二、LOSS
类似上一篇 ,同样都是计算y和label(真正的)y的差值。L=1/N ∑ 差值。
三、找到使L最小的Θ
Θ=[Θ1,Θ2,Θ3…]T,随机选取一个Θ0
 把L对Θi在Θ=Θ0时的微分集合起来叫做gradient,记作g=▽L(Θ0)。把Θ0更新为Θ1、Θ2、Θ3…直到不想做或结束为止。
把L对Θi在Θ=Θ0时的微分集合起来叫做gradient,记作g=▽L(Θ0)。把Θ0更新为Θ1、Θ2、Θ3…直到不想做或结束为止。
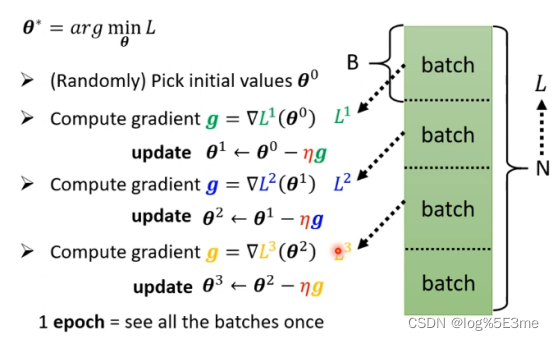
实际上,不是一次性把L对Θ中所有变量梯度下降,而是把L随机分为多个batch(部分),每个部分分别计算▽Li(Θi)。对一部分梯度下降叫做update,完成一次对所有batch的叫做1epoch。
也可以不用soft sigmoid代替hard sigmoid。把他看做c*max(0,b+wx1)。这种线叫做Rectified Linear Unit(ReLU),把两个ReLU叠加就成为hard sigmoid。

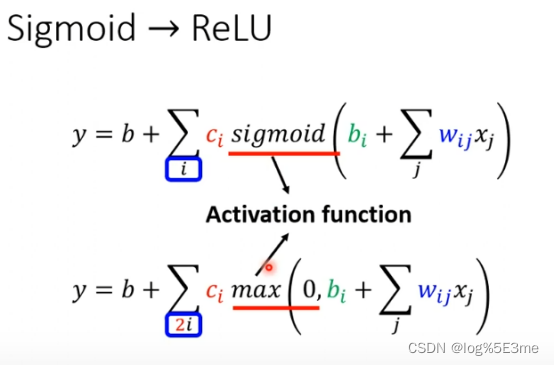
实验结果是ReLU更好,当ReLU个数越多Loss越小。

通过多次,效果更准。
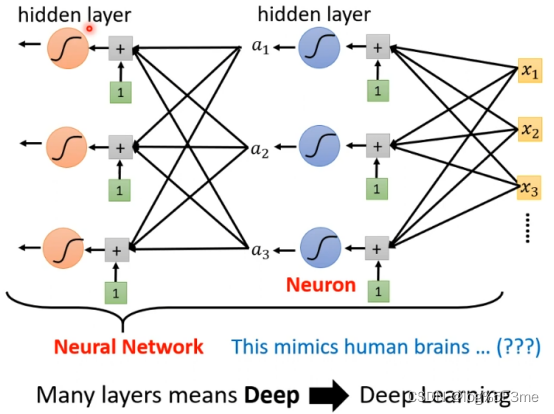
这些segmoid/ReLU叫做Neuron(神经元),这些神经元叫做Neural Network。多个hidden layer叫做deep learning。我们只把layers变深不把他变“胖”。
Overfitting现象:在训练过的资料上效果更好,在没看过的资料上预测效果更差。
学习视频地址:https://www.bilibili.com/video/BV13Z4y1P7D7?p=3&vd_source=3a369b537e1d34ff9ba8f8ab23afedec















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









