







波士顿房价预测(回归问题)
预测 20 世纪 70 年代中期波士顿郊区房屋价格的中位数,已知当时郊区的一些数
据点,比如犯罪率、当地房产税率等。它包含的数据点相对较少,只有 506 个,分为 404 个训练样本和 102 个测试样本。输入数据的每个特征(比如犯罪率)都有不同的取值范围。例如,有些特性是比例,取值范围为 0~ 1;有的取值范围为 1~ 12;还有的取值范围为 0~ 100,等等。
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
train_data.shape
(404, 13)
test_data.shape
(102, 13)
13 个数值特征
- Per capita crime rate.人均犯罪率
- Proportion of residential land zoned for lots over 25,000 square feet.超过25,000平方英尺土地的住宅用地比例
- Proportion of non-retail business acres per town.城镇非零售经营面积占比
- Charles River dummy variable (= 1 if tract bounds river; 0 otherwise).查尔斯河虚拟变量(河道边界河流=1,否则0)。
- Nitric oxides concentration (parts per 10 million).一氧化氮浓度(千万分之一)
- Average number of rooms per dwelling.每套住宅的平均房间数
- Proportion of owner-occupied units built prior to 1940.1940年以前建造的自住单位的比例
- Weighted distances to five Boston employment centres.到波士顿五个就业中心的加权距离
- Index of accessibility to radial highways.径向公路可达性指数
- Full-value property-tax rate per $10,000. 每1万美元的全额房产税税率
- Pupil-teacher ratio by town.各镇师生比例
- 1000 * (Bk - 0.63) ** 2 where Bk is the proportion of Black people by town.
1000 * (Bk - 0.63) ** 2其中Bk是按城镇划分的黑人比例 - % lower status of the population.人口地位降低%
# 目标是房屋价格的中位数,单位是千美元。
train_targets
房价大都在 10 000~50 000 美元。如果你觉得这很便宜,不要忘记当时是 20 世纪 70 年代中
期,而且这些价格没有根据通货膨胀进行调整。
1.数据预处理
注意,用于测试数据标准化的均值和标准差都是在训练数据上计算得到的。在工作流程中,
你不能使用在测试数据上计算得到的任何结果,即使是像数据标准化这么简单的事情也不行
# 特征的取值范围差异很大,对每个特征做标准化
mean = train_data.mean(axis=0) # axis=0按列取均值
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
df.mean(axis=0)
2.模型构建
由于样本数量很少,使用一个非常小的网络
from keras import models
from keras import layers
def build_model(): # 因为需要将同一个模型多次实例化,所以用一个函数来构建模型
model = models.Sequential()
# input_shapez指每次输入一个样本,该样本的特征数
model.add(layers.Dense(64, activation='relu',input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1)) # 标量回归:最后一层只有一个单元,没有激活,是一个线性层
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
网络的最后一层只有一个单元,没有激活,是一个线性层。这是标量回归(标量回归是预
测单一连续值的回归)的典型设置。添加激活函数将会限制输出范围。例如,如果向最后一层
添加 sigmoid 激活函数,网络只能学会预测 0~1 范围内的值。这里最后一层是纯线性的,所以
网络可以学会预测任意范围内的值。
注意,编译网络用的是 mse 损失函数,即均方误差(MSE,mean squared error),预测值与
目标值之差的平方。这是回归问题常用的损失函数。
在训练过程中还监控一个新指标:平均绝对误差(MAE,mean absolute error)。它是预测值
与目标值之差的绝对值。比如,如果这个问题的 MAE 等于 0.5,就表示你预测的房价与实际价
格平均相差 500 美元
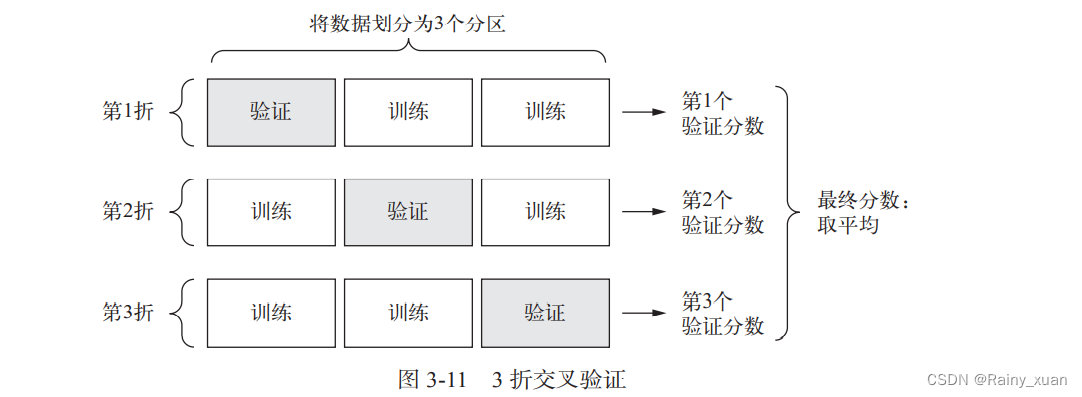
3.K 折交叉验证
数据点很少,验证集会非常小。验证集的划分方式可能会造成验证分数上有很大的方差,这样就无法对模型进行可靠的评估。
最佳做法是使用 K 折交叉验证。这种方法将可用数据划分为 K
个分区(K 通常取 4 或 5),实例化 K 个相同的模型,将每个模型在 K-1 个分区上训练,并在剩
下的一个分区上进行评估。模型的验证分数等于 K 个验证分数的平均值。
import numpy as np
k = 4
num_epochs = 100
num_val_samples = len(train_data) // k # /除,//取整,%取余
all_scores = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples] # 验证数据:第 k 个分区的数据
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate( # 训练数据:其他所有分区的数据
[train_data[:i * num_val_samples],train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model() # 构建 Keras 模型(已编译)
model.fit(partial_train_data, partial_train_targets, # 训练模型(静默模式verbose=0)
epochs=num_epochs, batch_size=1, verbose=0) # 数据量很小,设置batch_size=1
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0) # 在验证数据上评估模型
all_scores.append(val_mae)
processing fold # 0
processing fold # 1
processing fold # 2
processing fold # 3
all_scores
[2.239992141723633, 2.7303361892700195, 2.727764129638672, 2.8013319969177246]
np.mean(all_scores)
2.624856114387512
让训练时间更长一点,达到 500 个轮次,记录每轮的表现
如果在一个循环中创建许多模型,则此全局状态将随着时间消耗越来越多的内存,需要清除它。调用clear_session()会释放全局状态,这有助于避免旧模型和层造成混乱
from keras import backend as K
K.clear_session() # 重置所有由Keras产生的图层状态
import numpy as np
k = 4
num_epochs = 500
num_val_samples = len(train_data) // k # /除,//取整,%取余
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples] # 验证数据:第 k 个分区的数据
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate( # 训练数据:其他所有分区的数据
[train_data[:i * num_val_samples],train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model() # 构建 Keras 模型(已编译)
history = model.fit(partial_train_data, partial_train_targets, # 训练模型(静默模式verbose=0)
validation_data=(val_data,val_targets),
epochs=num_epochs, batch_size=1, verbose=0) # 数据量很小,设置batch_size=1
mae_history = history.history['val_mae']
all_mae_histories.append(mae_history)
processing fold # 0
processing fold # 1
processing fold # 2
processing fold # 3
# 计算所有轮次中的 K 折验证分数平均值
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
Let’s plot this:
import matplotlib.pyplot as plt
plt.plot(range(1, len(average_mae_history) + 1), average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
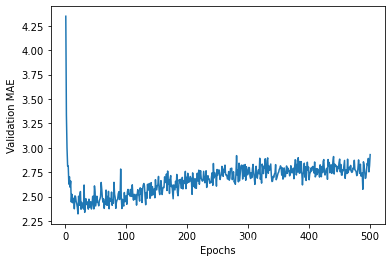
因为纵轴的范围较大,且数据方差相对较大,所以难以看清这张图的规律。
- 删除前 10 个数据点,因为它们的取值范围与曲线上的其他点不同。
- 将每个数据点替换为前面数据点的指数移动平均值,以得到光滑的曲线
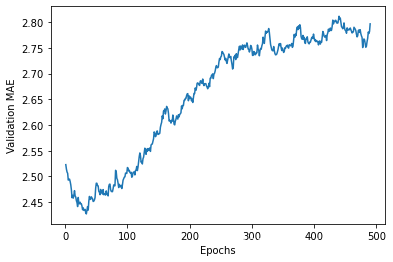
# 验证 MAE 在 80 轮后不再显著降低,之后就开始过拟合
def smooth_curve(points, factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous * factor + point * (1 - factor))
else:
smoothed_points.append(point)
return smoothed_points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1, len(smooth_mae_history) + 1), smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()
# 训练最终模型
model = build_model()
model.fit(train_data, train_targets,
epochs=80, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
4/4 [==============================] - 0s 988us/step - loss: 17.1250 - mae: 2.6952
test_mae_score
2.6951732635498047

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









