







第一章 Pytorch和神经网络
1.1 Pytorch入门
在pytorch中,数据的基本单位是张量(tensor),张量可以是多维数组,简单的二维矩阵,一维列表,也可以是单值。
pytorch张量比普通Python变量和numpy数组的功能更丰富,一个pytorch张量可以包含以下内容:
- 除原始数值之外的附加信息,比如梯度值。
- 关于它所依赖的其他张量的信息,以及这种依赖的数学表达式。
这种关联张量和自动微分的能力是pytorch最重要的特性,几乎所有的功能都基于这一特性。该自动计算函数的梯度是训练神经网络的关键,为此pytorch需要构建一张计算图,图中包含多个张量以及它们之间的关系。在代码中,该过程在我们以一个张量定义另一个张量时自动完成。
1.2 初试pytorch神经网络
1、获取mnist图像数据集
mnist数据集是一组常见的图像,常用于测评和比较机器学习算法的性能,其中6万幅图像用于训练机器学习模型,另外1万幅用于测试模型。这些大小为28像素*28像素的单色图像没有颜色, 每个像素是0-255的数值,表示该像素的明暗度。
2、数据预览
在使用任何工具和算法处理新数据之前,建议先进行数据探索。
【pandas库】
pandas DataFrame是一个与numpy数组相似的数据结构,具有许多附加功能,包括可为行和列命名,以及提供便利函数对数据求和过滤等。
1.可以使用head()函数查看一个较大DataFrame的前几行
2.可以使用info()函数查看DataFrame的概况

mnist共有60000行,每一行数据包含785个值。第一个值是图像所表示的数字,其余的784个值是图像(28像素*28像素)的像素值。
3、简单的神经网络
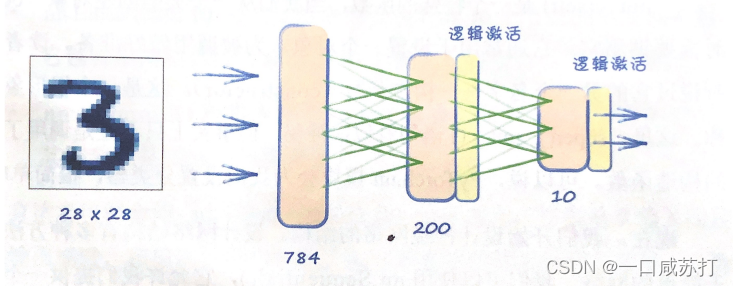
- 输入层为28*28即784个节点
- 输出层需要回答“这是什么数字”的问题,答案是0~9的任意一个数字,也就是10种不同输出,最直接的解决方案是为每一个可能的类别分配一个节点。
- 方便起见,隐藏层选择大小为200的中间层
- 隐藏层和输出层之间的激活函数选用逻辑函数Sigmoid。
1.导入库
同时导入torch和torch.nn,当创建神经网络类时,我们需要继承torch.nn模块,这样一来,新的神经网络就具备了许多pytorch的功能,如自动构建计算图、查看权重以及在训练期间更新权重等。
import torch
import torch.nn as nn2.初始化pytorch父类
class Classifier(nn.Module):
def _init_(self): #构造函数
#初始化pytorch父类
super()._init_() #调用父类的构造函数,也就是说pytorch.nn模块能为我们设置分类器3.定义神经网络层
对于简单的网络可以使用nn.Sequential(),它允许我们提供一个网络模块的列表。模块必须按照我们希望的信息传递顺序添加到容器中。
class Classifier(nn.Module):
def _init_(self):
#初始化pytorch父类
super()._init_()
#定义神经网络层
self.model = nn.Sequential(
nn.Linear(784 , 200),
nn.Sigmoid(),
nn.Linear(200 , 10),
nn.Sigmoid()
)nn.Sequential()中包括以下模块:
- nn.Linear(784 , 200)是一个从784个节点到200个节点的全连接映射。这个模块包含节点之间链接的权重,在训练时会被更新。
- nn.Sigmoid() 将S型逻辑激活函数应用于前一个模块的输出,也就是本例中200个节点的输出
- nn.Linear(200 , 10)是一个从200个节点到10个节点的全连接映射。它包含中间隐藏层与输出层10个节点之间所有链接的权重。
- nn.Sigmoid() 将S型逻辑激活函数应用于前10个节点的输出,其结果就是网络的最终输出。
4.创建损失函数
self.loss_function = nn.MSELoss()误差函数与损失函数?
“误差”单纯指预期输出和实际输出之间的差值,而“损失”是根据误差计算得到的,需要考虑具体需要解决的问题。
我们需要使用误差,更准确地说是是损失,来更新网络的链接权重。
5.创建优化器,使用简单的梯度下降
self.optimiser = torch.optim.SGD(self.parameters() , lr = 0.01)在上面的代码中,我们把所有可学习参数都传递给SGD优化器,这些参数可以通过self.parameters()访问。
6.添加forward()函数,pytorch会通过它将信息传递给网络
def forward(self , inputs):
#直接运行模型
return self.model(inputs)值将输入传递给self.model(),它由nn.Sequential()定义,模型的输出直接返回给forward()的主调函数。
7.创建train()函数
train()既需要网络的输入值,也需要预期的目标值,这样才可以与实际输出进行比较,并计算损失值。
def train(self, inputs, targets):
# 计算网络的输出值
outputs = self.forward(inputs)
# 计算损失值
loss = self.loss_function(outputs, targets)train()函数首先做的是使用forward()函数传递输入值给网络并获得输出值,下一步是使用损失来更新网络的链接权重,我们需要为每个节点计算误差梯度,再更新链接权值。
pytorch简化了这个过程:
- 首先,optimiser.zero_grad() 将计算图中的梯度全部归零
- 其次,loss.backward()从loss函数中计算网络中的梯度
- 最后,optimiser.step()使用这些梯度来更新网络的可学习参数
在每次训练网络之前,我们需要将梯度归零,否则每次loss.backward()计算出来的梯度会累积。我们可以把计算图的最终节点看做损失函数,该函数对每个进入损失的节点计算梯度,这些梯度是损失随着每个可学习参数的变化。优化器利用这些梯度,逐步(step)沿着梯度更新可学习参数。
8.可视化训练
跟踪训练的一种方法是监控损失,在train()中,每完成10个训练样本之后保留一份损失副本。
下面的代码在神经网络类的构造函数中创建一个初始值为0的计数器(counter)以及一个名为progress的空列表。
# 记录训练进展的计数器和列表
self.counter = 0
self.progress = []每隔10个训练样本增加一次计数器的值,并将损失值添加至列表的末尾。这里使用的item()函数只是为了方便展开一个单值张量,获取里面的数字。
# 每隔10个训练样本增加一次计数器的值,并将损失值添加至列表的末尾
self.counter += 1
if (self.counter % 10 == 0):
self.progress.append(loss.item())
pass还可以在每10000次训练后打印计数器的值,这样可以了解训练进展的快慢:
if(self.counter % 1000 == 0):
print("counter = ", self.counter)
pass可以在神经网络类中加一个新函数plot_progress()来将损失值绘成图,以下代码中第一行将损失值列表progress转换为一个pandas DataFrame,这样方便绘图。第二行使用plot()函数的选项,调整图的设计和风格。
def plot_progress(self):
df = pandas.DataFrame(self.progress, columns = ['loss'])
df.plot(ylim = (0, 1.0), figsize = (16, 8), alpha = 0.1, marker = '.',
grid = True, yticks = (0, 0.25, 0.5))
pass9.mnist数据集类
pytorch使用torch.utils.data.DataLoader实现了一些实用的功能,比如自动打乱数据顺序、多个进程并行加载、分批处理等,需要先将数据载入一个torch.utils.data.Dataset对象。
当我们从nn.Module继承一个神经网络类时,需要定义forward()函数,同样地,对于继承自Dataset的数据集,我们需要提供以下两个特殊的函数:
- _len_(),返回数据集中的项目总数
- _getitem_(),返回数据集中的第n项
接下来我们会创建一个MnistDataset类,并提供_len_()方法,允许pytorch通过len(mnist_dataset)获取数据集的大小。同时我们也会提供_getitem_(),允许我们通过索引获取项目,例如使用mnist_dataset[3]访问第4项。
接下去分类器的训练,查询神经网络及性能验证以及优化方法省略...
改良方法总结
- 均方误差损失MSE适用于输出是连续值的回归任务;二元交叉熵损失BCE更适合输出1或0(true or false)的分类任务。
- 传统的S型激活函数在处理较大值时,具有梯度消失的缺点。这在网络训练时会造成反馈信号减弱。ReLU激活函数部分解决了这一问题,保持正值部分良好的梯度值。LeakyReLU进一步改良,在负值部分增加一个很小却不会消失的梯度值。
- Adam优化器使用动量来避免进入局部最小值,并保持每个可学习参数独立的学习率。在许多任务上,使用它的效果优于SGD优化器。
- 标准化可以稳定神经网络的训练。一个网络的初始权重通常需要标准化。在信号通过一个神经网络时,使用LayerNorm标准化信号值可以提升网络性能。















 2358
2358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









