







最近在学习《Deep learning with pytorch》,跟着b站的一个up主敲代码,本篇内容对应视频。
(实验在colab上完成,对此感兴趣的可以看这一篇,有使用介绍。)
实现内容:
使用GAN生成式对抗网络,将图中的马变成斑马。
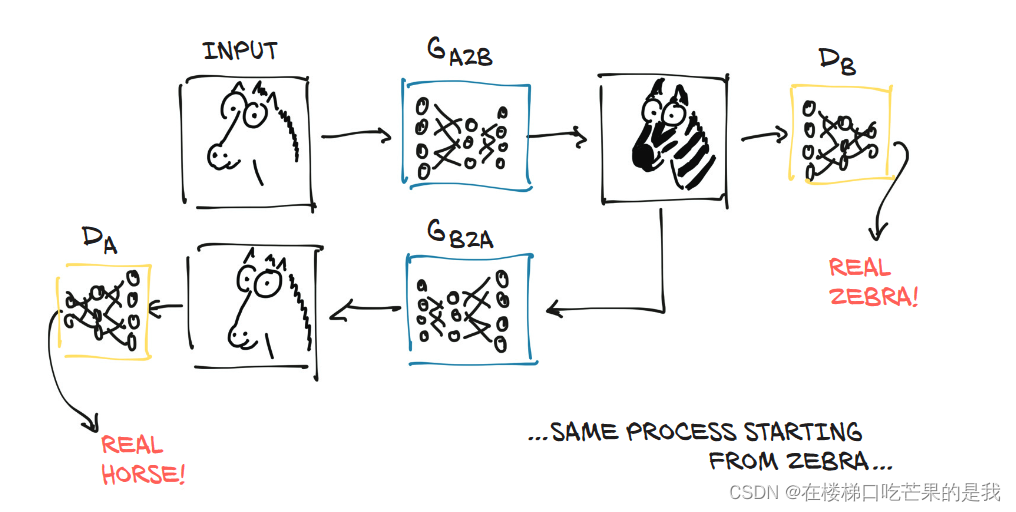
实验准备:
实验所需要的文件可以通过百度网盘获得:
- horse.jpg
- horse2zebra_0.4.0.pth
链接:https://pan.baidu.com/s/1iOSDc00eZjzjwEEGS7ph7Q
提取码:oad1
实验步骤:
第一步:构建模型
import torch
import torch.nn as nn
本章节主要的学习目的是体会这些模型是做什么的,而不是怎么做的,所以这一部分的代码先不用深究,复制粘贴即可。如果你很感兴趣,也可以自己敲一遍。
#本章主要是体会模型可以做什么,暂时不用深究他是怎么实现的
class ResNetBlock(nn.Module): # <1>
def __init__(self, dim):
super(ResNetBlock, self).__init__()
self.conv_block = self.build_conv_block(dim)
def build_conv_block(self, dim):
conv_block = []
conv_block += [nn.ReflectionPad2d(1)]
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=0, bias=True),
nn.InstanceNorm2d(dim),
nn.ReLU(True)]
conv_block += [nn.ReflectionPad2d(1)]
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=0, bias=True),
nn.InstanceNorm2d(dim)]
return nn.Sequential(*conv_block)
def forward(self, x):
out = x + self.conv_block(x) # <2>
return out
class ResNetGenerator(nn.Module):
def __init__(self, input_nc=3, output_nc=3, ngf=64, n_blocks=9): # <3>
assert(n_blocks >= 0)
super(ResNetGenerator, self).__init__()
self.input_nc = input_nc
self.output_nc = output_nc
self.ngf = ngf
model = [nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=True),
nn.InstanceNorm2d(ngf),
nn.ReLU(True)]
n_downsampling = 2
for i in range(n_downsampling):
mult = 2**i
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3,
stride=2, padding=1, bias=True),
nn.InstanceNorm2d(ngf * mult * 2),
nn.ReLU(True)]
mult = 2**n_downsampling
for i in range(n_blocks):
model += [ResNetBlock(ngf * mult)]
for i in range(n_downsampling):
mult = 2**(n_downsampling - i)
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
kernel_size=3, stride=2,
padding=1, output_padding=1,
bias=True),
nn.InstanceNorm2d(int(ngf * mult / 2)),
nn.ReLU(True)]
model += [nn.ReflectionPad2d(3)]
model += [nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
model += [nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, input): # <3>
return self.model(input)
#生成一个模型实体
netG = ResNetGenerator()
到这一步为止,我们只定义了网络的结构,网络的参数没有被训练。目前,它包含随机权重。所以下一步我们可以加载已经训练好的参数。
第二步:加载预训练所得的参数
我们将运行一个已经在马-斑马数据集上预训练的生成器模型,其训练集分别包含马和斑马的两组1068和1335张图像。文件horse2zebra_0.4.0.pth中包含了预训练好的张量参数,我们将它加载到网络模型中。
#上传 horse2zebra_0.4.0.pth,这个文件里有根据马和斑马数据集已经训练好的参数权重
from google.colab import files
files.upload()
#加载一个预训练的网络的参数
model_path = '/content/horse2zebra_0.4.0.pth'
model_data = torch.load(model_path)
#在Pytorch中构建好一个模型后,一般需要进行预训练权重中加载。
#torch.load_state_dict()函数就是用于将预训练的参数权重加载到新的模型之中,
netG.load_state_dict(model_data)
 至此,netG已经掌握了其在训练中所获得的全部知识。
至此,netG已经掌握了其在训练中所获得的全部知识。
第三步:我们选择一张图片
from PIL import Image
from torchvision import transforms
#然后我们定义了一些输入变换来确保数据以正确的形状和大小进入网络
preprocess = transforms.Compose([transforms.Resize(256),
transforms.ToTensor()])
#上传 horse.jpg
from google.colab import files
files.upload()
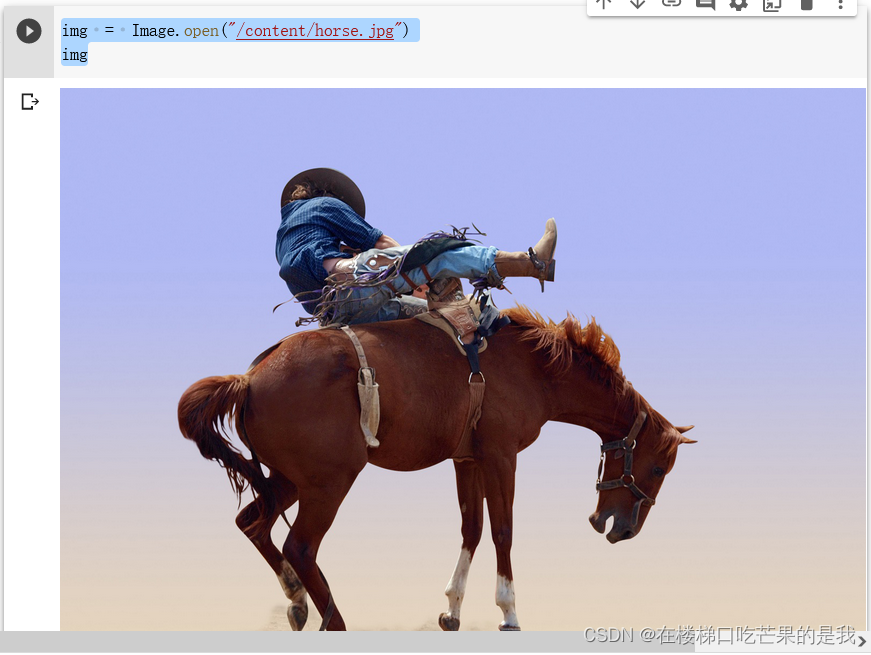
img = Image.open("/content/horse.jpg")
img
可以看到此时分辨率还是比较高的。
第四步:将图片放入模型中
首先将我们的对象转化成张量才能放入模型:
#将图片转化成了张量
img_t = preprocess(img)
#torch.unsqueeze(input,dim),参数dim表示在哪个地方加一个维度,注意dim范围在:[-input.dim()-1,input.dim()+1]之间
#比如输入input是一维,则dim=0时数据为行方向扩,dim=1时为列方向扩
batch_t = torch.unsqueeze(img_t,0)
对比一下升维度的前后变化:
img_t.shape,batch_t.shape

#batch_out为模型输出的结果
batch_out = netG(batch_t)
batch_out.shape

可以看到,对比上一篇文章中给图片分类,输出维度是【1,1000】,这里的输出维度和输入维度是一样的,因为我们需要的也是一张图片,而不是一个分类结果。
#图片是三维的,所以如果想打印出来,要先降为batch_out.data.squeeze()
out_t = (batch_out.data.squeeze()+1.0)/2.0
#将张量转化为图片
out_img = transforms.ToPILImage()(out_t)
out_img
最后来看一下我们的输出结果:
原图中的马已经被改编成了斑马,但是显然这个效果并不是那么逼真,牛仔的衣服、马的鬓毛也有部分变成了斑马纹。

好啦,第二次尝试告一段落~















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









