







Fast Vision Transformers with HiLo Attention
论文: https://arxiv.org/abs/2205.13213
LITv1:Less is more: Pay less attention in vision transformers
AAAI 2022
https://arxiv.org/abs/2105.14217
由于self-attention在长表示序列上的二次复杂性,特别是对于高分辨率密集预测任务,先前工作中的 Transformer 训练和推理可能非常昂贵。且分层架构中早期阶段的MSA表现更像卷积,仅仅会关注于很小的局部区域,而更深层的结构对全局的依赖性更强。
LIT是一种hierarchical Transformer,在早期阶段使用纯多层感知器 (MLP) 对丰富的局模式进行编码,同时应用自注意力模块来捕获更深层中更长的依赖关系。
同时,引入可变形卷积来改进patch merging层。



Introduction
现实世界的应用程序通常需要模型在有限的计算预算下进行最佳速度和精度权衡,例如无人机和自动驾驶。这激发了朝着高效 ViT 设计的大量工作,例如 PVT、Swin 和 Focal Transformer 等。为了衡量计算复杂度,最近 ViT 设计中广泛采用的度量是浮点运算的数量,即 FLOPs。但是,FLOPs 是一个间接指标,不能直接反映目标平台上的真实速度。例如,Focal-Tiny 在 GPU 上比 Swin-Ti 慢得多,尽管它们的 FLOPs 相当。
一般来说,最近 ViT 中间接指标 (FLOP) 和直接指标 (速度) 之间的差异可归因于2个主要原因。
首先,尽管 self-attention 在低分辨率特征图上很有效,但由于内存访问成本高,内存和时间的二次复杂度使得在高分辨率图像上的速度要慢得多,从片外 DRAM 获取数据可能会加快速度消耗。
其次,ViTs 中的一些高效注意力机制理论上的复杂度保证较低,但实际上在 GPU 上速度很慢,因为特定的操作对硬件不友好或无法并行化,例如多尺度窗口划分、递归和扩张窗口等。
有了这些观察结果,在本文中通过直接度量来评估 ViT,即吞吐量,而不仅仅是 FLOPs。基于此原理引入了 LITv2,这是一种新型高效且准确的Vision Transformer,它在标准基准测试中优于大多数最先进的 ViT,同时在 GPU 上实际上速度更快。
Method
LITv2 是在 LITv1 的基础上构建的,LITv1 是一个简单的 ViT Baseline,它在早期 Stage 移除所有Multi-Head Self-Attention,同时在后期 Stage 应用标准Multi-Head Self-Attention。得益于这种设计,LITv1 比许多现有的 ImageNet 分类工作更快,因为早期的 Multi-Head Self-Attention 没有计算成本,而后来的 Multi-Head Self-Attention 只需要处理下采样的低分辨率特征图。然而,标准的 Multi-Head Self-Attention 在高分辨率图像上仍然存在巨大的计算成本,尤其是对于密集预测任务。

为了解决这个问题,本文提出了一种新的高效注意力机制,称为 HiLo。HiLo 的动机是自然图像包含丰富的频率,其中高/低频在编码图像模式中扮演不同的角色,即分别为局部细节(线条和形状)和全局结构(纹理和颜色)。典型的 MSA 层在所有图像块上强制执行相同的全局注意力,而不考虑不同基础频率的特征。
这促使提出将 MSA 层分成两条路径,其中一条路径通过局部Self-Attention和相对高分辨率的特征图对高频交互进行编码,而另一条路径通过全局注意力和下采样特征对低频交互进行编码,从而大大提高了效率。

1、High-frequency attention (Hi-Fi)
直观地说,由于高频对对象的局部细节进行编码,因此在特征图上应用全局注意力可能是冗余且计算成本高的。因此,在图中上面的路径中,将几个Head分配给高频注意力(Hi-Fi),来捕获具有Local Window Self-Attention(例如2 × 2窗口)的细粒度高频,这可以节省大量的计算复杂度。
此外,在 Hi-Fi 中采用了简单的非重叠窗口,与窗口移位或多尺度窗口划分等耗时的操作相比,它对硬件更加友好。
2、Low-frequency attention (Lo-Fi)
最近的研究表明,MSA 中的全局注意力有助于捕获低频。然而,直接将 MSA 应用于高分辨率特征图需要巨大的计算成本。
由于平均是一个低通滤波器,Lo-Fi 首先对每个窗口应用平均池化以获得输入 X 中的低频信号。接下来,平均池化的特征图被投影到Key 和 Vlaue 。Lo-Fi 中的query Q 仍然来自原始特征图 X。然后应用标准注意力来捕获特征图中丰富的低频信息。
由于 K 和 V 的空间缩减,Lo-Fi 同时降低了矩阵运算和Self-Attention的复杂度。
3、Head splitting
一个简单的Head分配解决方案是为 Hi-Fi 和 Lo-Fi 分配与标准 MSA 层相同数量的Head。为了获得更好的效率,HiLo 将 MSA 中相同数量的Head分成2组,分配比为α,其中(1-α)Nh个Head用于 Hi-Fi,其他αNh 个Head用于 Lo-Fi。
由于每个注意力的复杂度都低于标准的 MSA,HiLo 的整个框架保证了低复杂度并确保了 GPU 上的高吞吐量。
最后,HiLo 的输出是每个注意力输出的concat:
HiLo(X)= [ Hi-Fi(X); Lo-Fi(X) ]
Positional Encoding
在 LITv1 中,MSA 采用与 Swin 相同的相对位置编码 (RPE) 方案。这个与使用绝对位置编码相比,该方法在 ImageNet 上的 Top-1 准确度上显着提高了 0.7%。
然而,在密集预测任务中,必须针对不同的图像分辨率对固定的 RPE 进行插值,这大大减慢了 LITv1 的训练/推理速度。
最近的研究表明,位置信息可以从零填充的卷积中隐式学习,建议在每个 FFN 中采用具有零填充的一层 3×3 深度卷积层来代替耗时的 RPE。
由于消除了早期Stage中的 MSA,LITv1 中的早期Stage Block只剩下 FFN,这导致了 1×1 的微小感受野。为此,作者还在每个 FFN 中采用 3×3 卷积滤波器通过同时扩大早期Stage的感受野来改进 LITv2。
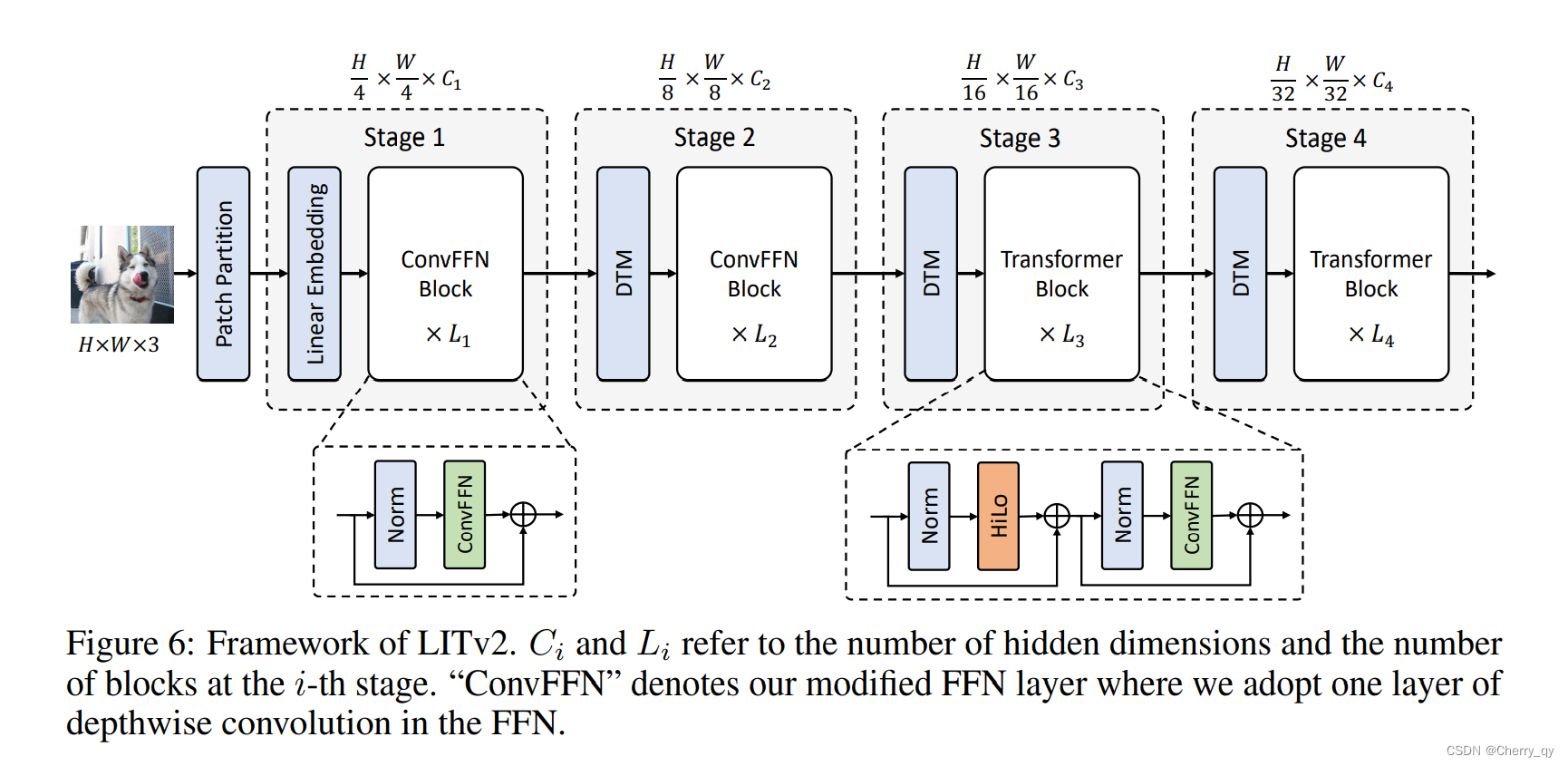
LITv2 具有三个变体:LITv2-S、LITv2-M 和 LITv2-B,分别对应 LITv1 中的Small、medium和base设置。为了公平比较,保持网络宽度和深度与 LITv1 相同。整体修改简单地分为2个步骤:
- 在每个 FFN 中添加一层带有零填充的深度卷积,并删除所有 MSA 中的所有相对位置编码。
- 用建议的 HiLo 注意力替换所有注意力层。

消融实验
1、HiLo与其他注意力机制的比较
基于 LITv2-S,将 HiLo 的性能与 ImageNet-1K 上的其他有效注意力机制进行了比较,包括 PVT 中的空间缩减注意力 (SRA)、Swin 中的基于移位窗口的注意力 (W-MSA) 以及Twins中的交替的局部和全局注意力 (T-MSA)。
在实现中,直接用每个比较方法替换 HiLo。结果如表 4 所示。总的来说,HiLo 减少了更多的 FLOPs,同时实现了更好的性能和更快的速度。
此外,在图 3 中,提供了基于不同图像分辨率的更多注意力机制的综合基准,包括 Focal、QuadTree 和 Performer。由于并行性较弱,它们甚至比在 GPU 上使用标准 MSA 还要慢。与它们相比,HiLo 在 FLOPs、吞吐量和内存消耗方面取得了具有竞争力的结果。

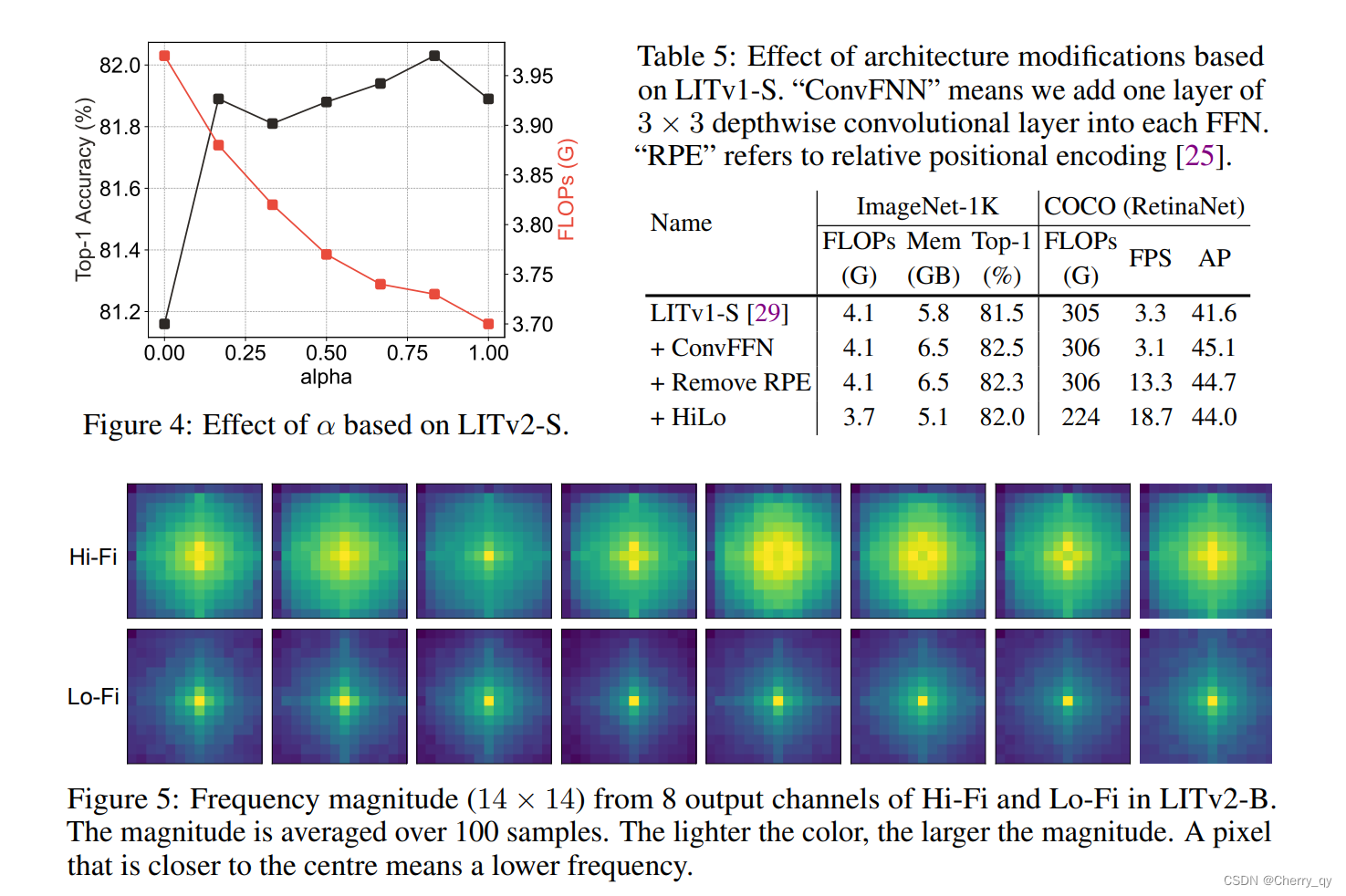
2、α的影响
如图 4 所示,由于在 224 × 224 的分辨率和窗口大小为2的情况下,Lo-Fi 的复杂度低于 Hi-Fi,因此更大的 α 有助于减少更多的 FLOPs,因为将更多的Head分配给 Lo-Fi。
此外,作者发现 HiLo 在 α = 0 时表现不佳,在这种情况下,只剩下 Hi-Fi,HiLo 只关注高频。作者推测低频在自注意力中起着重要作用。对于其他 α 值,作者发现性能差异约为 0.2%,其中 α = 0.9 实现了最佳性能。
3、架构修改的影响
基于 LITv2-S探索架构修改的效果。如表 5 所示,受益于早期扩大的感受野,深度卷积的采用提高了 ImageNet 和 COCO 的性能。接下来,通过去除相对位置编码提高了密集预测任务的 FPS,但在两个数据集上的性能略有下降。
另注意,由于深度卷积通过零填充对位置信息进行了编码,因此与之前的工作相比,RPE 的消除不会导致性能显着下降。最后,得益于 HiLo,在 ImageNet 和 COCO 上都获得了更多的模型效率提升。
4、HiLo光谱分析
在图 5 中,分别可视化了来自 Hi-Fi 和 Lo-Fi 注意力的输出特征图的频率幅度。可视化表明 Hi-Fi 捕获更多的高频,而 Lo-Fi 主要侧重于低频。这与在单个注意力层分离特征图中的高频和低频的目标非常一致。
实验


















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









