






知识科普
PaddlePaddle 是什么?
飞桨(PaddlePaddle)以百度多年的深度学习技术研究和业务应用为基础,是中国首个自主研发、功能完备、 开源开放的产业级深度学习平台,集深度学习核心训练和推理框架、基础模型库、端到端开发套件和丰富的工具组件于一体。
PaddleOCR 是什么?
PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。
PaddleOCR提供的2种服务部署方式
基于PaddleHub Serving的部署:代码路径为"./deploy/hubserving",使用方法参考文档;
基于PaddleServing的部署:代码路径为"./deploy/pdserving",按照本教程使用。
相比较于hubserving部署,PaddleServing具备的优点
-
支持客户端和服务端之间高并发和高效通信
-
支持 工业级的服务能力 例如模型管理,在线加载,在线A/B测试等
-
支持 多种编程语言 开发客户端,例如C++, Python和Java
PaddleServing 支持多种语言部署,paddleocr官方提供了python pipeline 和 C++ 两种部署方式,两者的对比如下:
| 语言 | 速度 | 二次开发 | 是否需要编译 |
| C++ | 很快 | 略有难度 | 单模型预测无需编译,多模型串联需要编译 |
| python | 一般 | 容易 | 单模型/多模型 均无需编译 |
安装快速开始
以下是基于python pipeline的安装步骤
-
安装python环境
使用paddlepaddle需要先安装python环境,可以通过anaconda一键安装python环境 anaconda下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
Q: 为啥用anaconda?
用 anaconda 新建一个虚拟环境(paddlepaddle 和 paddleocr 都有依赖库,以防与之前环境安装库的版本冲突)。
Linux下使用wget下载
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/Anaconda3-2021.11-Linux-x86_64.sh开始anaconda安装python环境
sh Anaconda3-2023.09-0-Linux-x86_64.sh过程中会提示安装位置,yes选择默认,no需要自定义安装位置
手动将conda加入环境变量
vim ~/.bashrc
# 在第一行输入:
export PATH="~/anaconda3/bin:$PATH"
# 刷新环境变量
source ~/.bash_profile验证是否能识别conda命令
conda info --envs显示当前有base环境,则conda已加入环境变量
-
创建conda环境
创建paddle_env的运行环境
# 此处为加速下载,使用清华源
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/激活paddle_env环境
conda activate paddle_env【注意】如果报以下错误就先执行conda init bash命令再重新激活paddle_env环境

-
安装paddle
# 默认安装CPU版本
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple-
安装PaddleOCR whl包
pip install "paddleocr>=2.0.1"=====至此,可以通过命令在服务端测试:
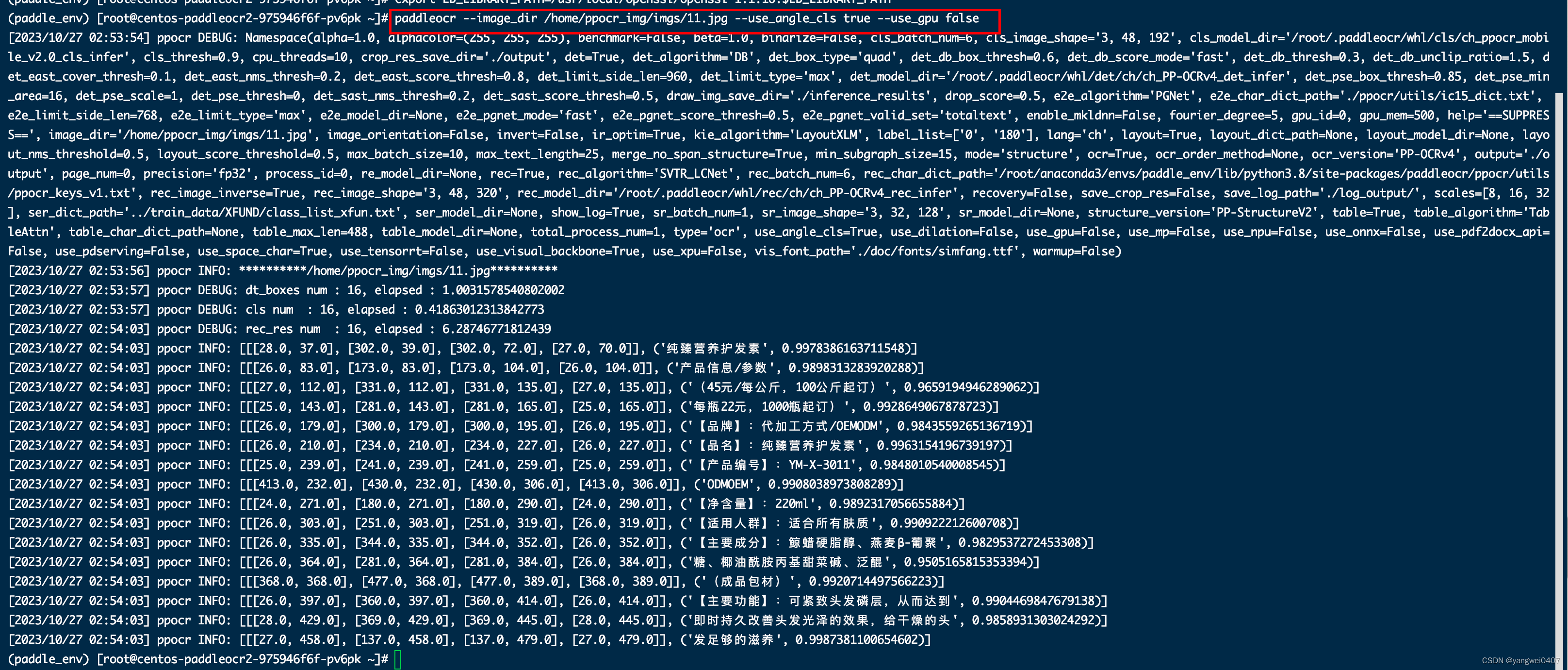
paddleocr --image_dir /home/ppocr_img/imgs/11.jpg --use_angle_cls true--use_gpu false
--image_dir参数后/home/ppocr_img/imgs/11.jpg: 测试图片路径
--use_angle_cls true设置使用方向分类器识别180度旋转文字
--use_gpu false设置不使用GPU
=====以下操作是paddleocr服务化部署
-
克隆PaddleOCR repo代码,如果没装git命令可以把zip包下下来,然后传到服务器上,再解压
git clone https://github.com/PaddlePaddle/PaddleOCR-
安装第三方库
cd PaddleOCR
pip3 install -r requirements.txt-
准备PaddleServing的运行环境
# 进入到工作目录
cd /home/PaddleOCR/deploy/pdserving
# 安装serving,用于启动服务
wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_server_gpu-0.8.3.post102-py3-none-any.whl
pip3 install paddle_serving_server_gpu-0.8.3.post102-py3-none-any.whl
# 如果是cuda10.1环境,可以使用下面的命令安装paddle-serving-server
# wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_server_gpu-0.8.3.post101-py3-none-any.whl
# pip3 install paddle_serving_server_gpu-0.8.3.post101-py3-none-any.whl
# 安装client,用于向服务发送请求
# 注意一定要与自己python的版本一致,我用的python版本是3.8,我下载的包就是cp38
wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_client-0.8.3-cp38-none-any.whl
pip3 install paddle_serving_client-0.8.3-cp38-none-any.whl
# 安装serving-app
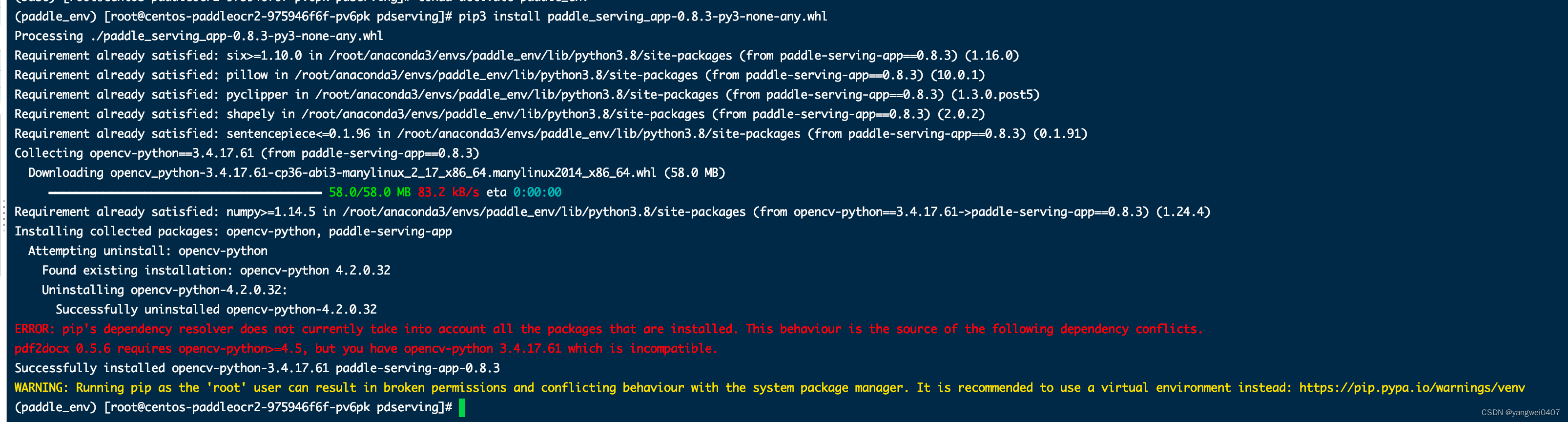
wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_app-0.8.3-py3-none-any.whl
pip3 install paddle_serving_app-0.8.3-py3-none-any.whl
安装serving-app如果报opencv-python的错误不需要管。
-
安装模型
使用PaddleServing做服务化部署时,需要将保存的inference模型转换为serving易于部署的模型
# 进入PaddleOCR
cd PaddleOCR
# 创建inference目录
mkdir inference
# 下载并解压 OCR 文本检测模型,下载不下来或者没有wget命令就手动上传再解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar -O ch_PP-OCRv3_det_infer.tar && tar -xf ch_PP-OCRv3_det_infer.tar
# 下载并解压 OCR 文本检测模型,下载不下来或者没有wget命令就手动上传再解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar -O ch_PP-OCRv3_rec_infer.tar && tar -xf ch_PP-OCRv3_rec_infer.tar
# 转换检测模型
python3 -m paddle_serving_client.convert --dirname ./ch_PP-OCRv3_det_infer/ \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--serving_server ./ppocr_det_v3_serving/ \
--serving_client ./ppocr_det_v3_client/
# 转换识别模型
python3 -m paddle_serving_client.convert --dirname ./ch_PP-OCRv3_rec_infer/ \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--serving_server ./ppocr_rec_v3_serving/ \
--serving_client ./ppocr_rec_v3_client/
操作完之后会生成如下四个文件
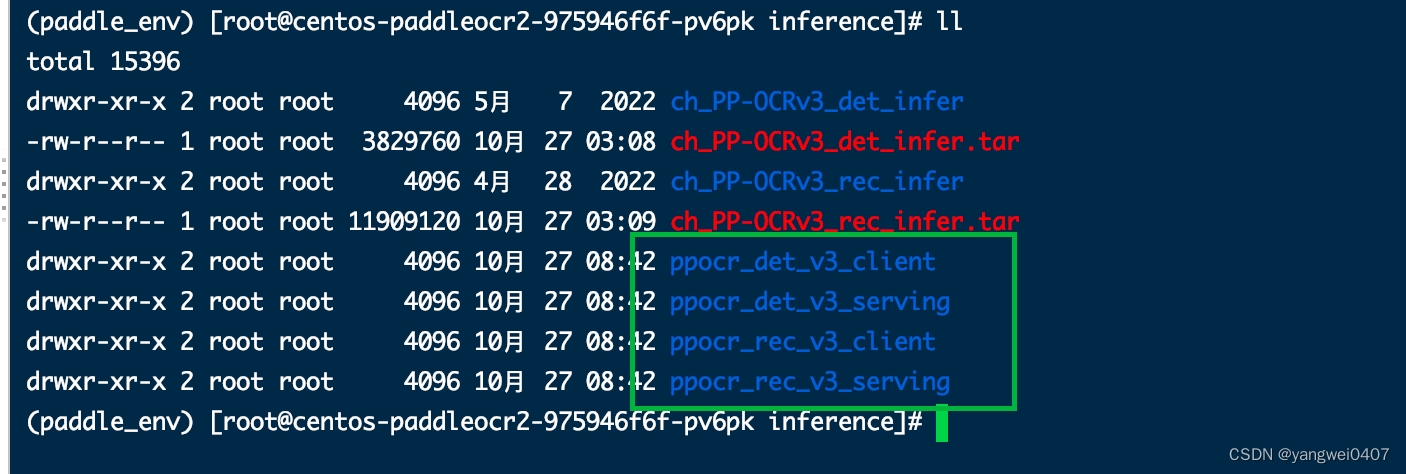
-
启动服务
进入到工作目录
cd PaddleOCR/deploy/pdserving/_ init _.py # 空目录 必须
config.yml # 启动服务的配置文件
ocr_reader.py # OCR模型预处理和后处理的代码实现
pipeline_http_client.py # 发送pipeline预测请求的脚本
web_service.py # 启动pipeline服务端的脚本
修改配置文件中det模型路径和rec模型路径
vim config.yml启动服务
python3 web_service.py --config=config.yml【注意】默认服务端口9998,可以在config.yml中修改
如果启动报以下错误,就是启动服务的时候没有制定配置文件的问题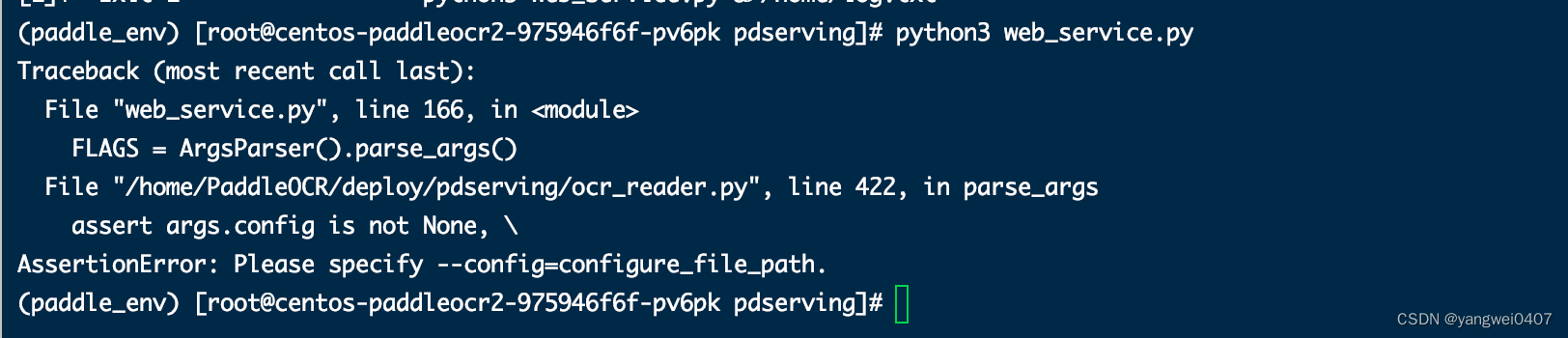
启动成功打印的日志
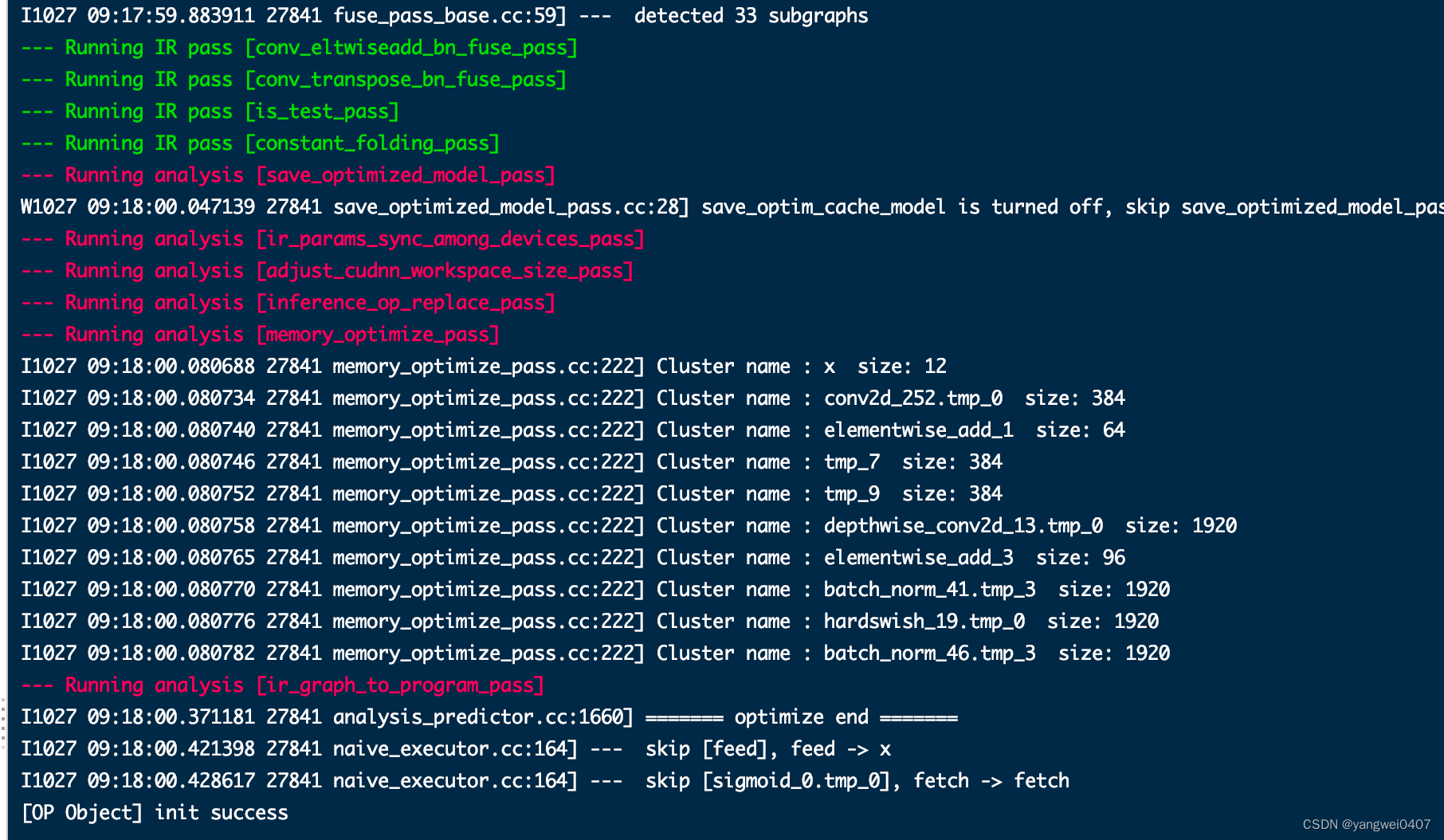
后台启动服务
# 运行日志保存在log.txt
python3 web_service.py --config=config.yml &>/home/log.txt &-
后台测试
# 进入工作目录
cd /home/PaddleOCR/deploy/pdserving
# 测试 该命令会检测/home/PaddleOCR/doc/imgs下所有图片进行文字识别
python3 pipeline_http_client.py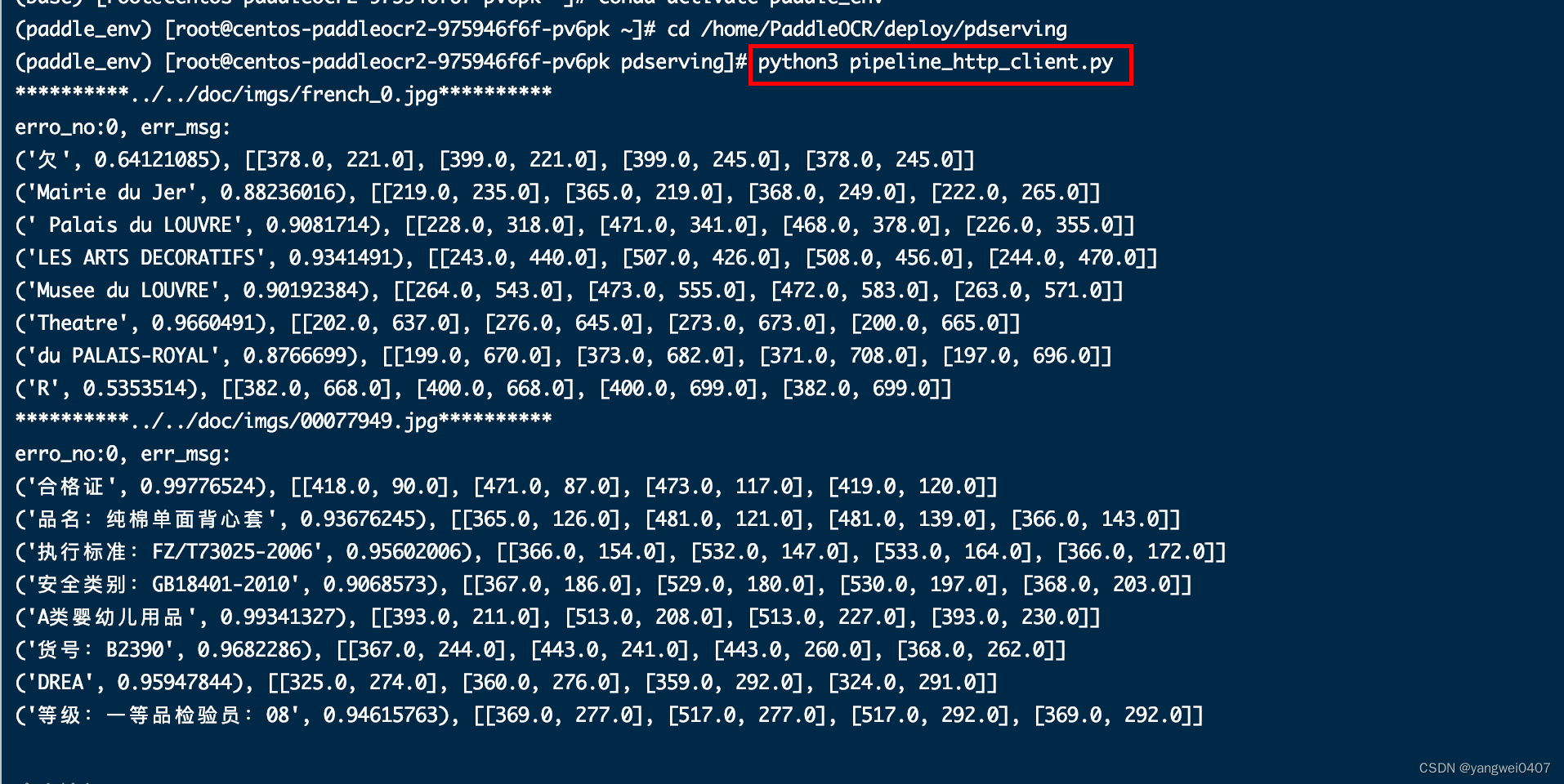
-
http接口测试
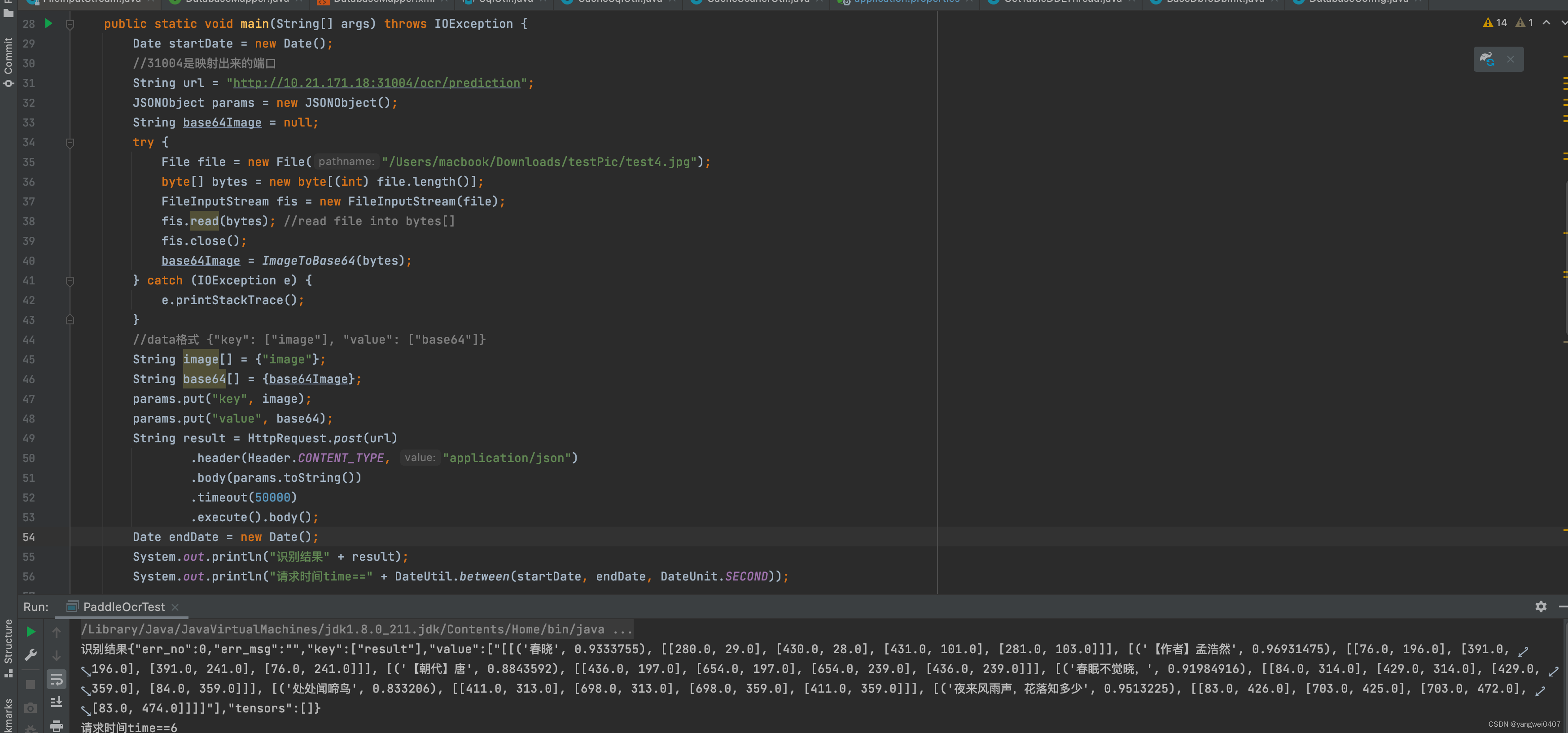
-
参数调整
调整 config.yml 中的并发个数获得最大的QPS, 一般检测和识别的并发数为2:1
det:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 8
...
rec:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 4
...有需要的话可以同时发送多个服务请求
预测性能数据会被自动写入 PipelineServingLogs/pipeline.tracer 文件中。
在200张真实图片上测试,把检测长边限制为960。T4 GPU 上 QPS 均值可达到23左右:
-
安装过程中遇到的问题
报错ImportError: libssl.so.1.1: cannot open shared object file: No such file or directory
解决方案:安装openssl
mkdir /usr/local/openssl
cd /usr/local/openssl
# 上传文件openssl-1.1.1o.tar.gz到该目录下并解压
tar -zxvf openssl-1.1.1o.tar.gz
# 进入解压后的目录
cd openssl-1.1.1o
# 编译安装
./config --prefix=/usr/local/openssl && make && make install安装完后设置环境变量或添加软链接
# 设置环境变量
export LD_LIBRARY_PATH=/usr/local/openssl/openssl-1.1.1o:$LD_LIBRARY_PATH报错ImportError: libXrender.so.1: cannot open shared object file: No such file or directory
# 终端输入以下命令
yum whatprovides libXrender.so.1
# 然后在终端输入以下命令,libXrender-0.9.10-1.el7就是上条命令查到的结果,注意把i686改为x86_64
yum install libXrender-0.9.10-1.el7.x86_64
# 安装完成即可。报错ImportError: libGL.so.1: cannot open shared object file: No such file or directory
# 下载mesa-libGL.x86_64
yum install mesa-libGL.x86_64报错ImportError: libSM.so.6: cannot open shared object file: No such file or directory
# 终端输入以下命令
yum whatprovides libSM.so.6
# 然后在终端输入以下命令,libSM-1.2.2-2.el7就是上条命令查到的结果,注意把i686改为x86_64
yum install libSM-1.2.2-2.el7.x86_64
# 安装完成即可。
















 3885
3885

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









