






OCR,即光学字符识别(Optical Character Recognition),是一种将图像中的文字转换为机器编码文字的技术。这种技术可以识别和转换各种来源的文本,包括扫描文档、照片中的文字、手写笔记等。光学字符识别(OCR)技术在实际应用场景中的作用是多方面的。首先,OCR技术在文档数字化方面扮演着关键角色。通过将纸质文档转换为电子格式,如PDF或Word文档,OCR不仅促进了信息的保存和共享,也极大地提高了数据检索的效率。这一过程对于历史档案的保存尤为重要,同时也在日常办公环境中普遍应用。其次,OCR技术在自动数据录入领域的应用显著提高了工作效率。企业和机构通过OCR技术自动读取和录入发票、表格等文档中的数据,大大减少了手动输入的时间和错误率。这种应用在金融、医疗、法律等行业中尤为重要,其中数据的准确性对业务流程至关重要。此外,OCR技术在辅助视障人士阅读方面也发挥着重要作用。通过将书籍和其他印刷材料转换成电子文本,OCR技术使得这些内容可以通过语音合成软件朗读,从而提高了视障人士的信息获取能力和生活质量。还有,OCR技术在交通和城市管理中也有广泛应用。例如,在交通领域,OCR可用于自动车牌识别,从而支持交通监控和管理系统。在城市管理方面,OCR可用于识别和处理公共空间中的各种标识和指示牌。
PPOCR 服务化部署
PaddleOCR提供2种服务部署方式:
- 基于PaddleHub Serving的部署:代码路径为"
./deploy/hubserving",使用方法参考文档; - 基于PaddleServing的部署:代码路径为"
./deploy/pdserving",按照本教程使用。
基于PaddleServing的服务部署
本文档将介绍如何使用PaddleServing 工具部署PP-OCR动态图模型的pipeline在线服务。
相比较于hubserving部署,PaddleServing具备以下优点:
- 支持客户端和服务端之间高并发和高效通信
- 支持 工业级的服务能力 例如模型管理,在线加载,在线A/B测试等
- 支持 多种编程语言 开发客户端,例如C++, Python和Java
PaddleServing 支持多种语言部署,本例中提供了python pipeline 和 C++ 两种部署方式,两者的对比如下:
| 语言 | 速度 | 二次开发 | 是否需要编译 |
|---|---|---|---|
| C++ | 很快 | 略有难度 | 单模型预测无需编译,多模型串联需要编译 |
| python | 一般 | 容易 | 单模型/多模型 均无需编译 |
更多有关PaddleServing服务化部署框架介绍和使用教程参考文档。
一、安装paddle
1.创建沙盒环境并激活。
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda activate paddle_env
2.安装paddle和paddleocr。
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
pip install "paddleocr>=2.0.1"3.测试
paddleocr --image_dir ./test/1.jpg --use_angle_cls true
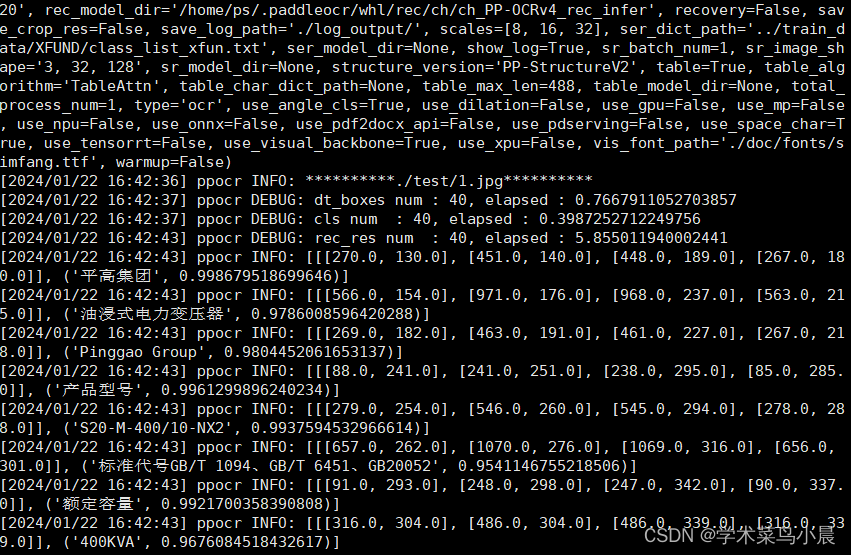
二、服务化部署
下载项目:
https://github.com/PaddlePaddle/PaddleOCR
cd PaddleOCR
pip install -r requirements.txt
cd /deploy/pdserving安装serving,用于启动服务。我的cuda版本是12.0。
参考:
https://github.com/PaddlePaddle/Serving/blob/v0.8.3/doc/Latest_Packages_CN.md
选择自己合适的。
# 安装serving,用于启动服务
wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_server_gpu-0.8.3.post112-py3-none-any.whl
pip install paddle_serving_server_gpu-0.8.3.post112-py3-none-any.whl# 安装client,用于向服务发送请求
# 注意一定要与自己python的版本一致,我用的python版本是3.8,我下载的包就是cp38
wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_client-0.8.3-cp38-none-any.whl
pip install paddle_serving_client-0.8.3-cp38-none-any.whl
# 安装serving-app
wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_app-0.8.3-py3-none-any.whl
pip install paddle_serving_app-0.8.3-py3-none-any.whl
# 下载并解压 OCR 文本检测模型,下载不下来或者没有wget命令就手动上传再解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar -O ch_PP-OCRv3_det_infer.tar && tar -xf ch_PP-OCRv3_det_infer.tar
# 下载并解压 OCR 文本检测模型,下载不下来或者没有wget命令就手动上传再解压
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar -O ch_PP-OCRv3_rec_infer.tar && tar -xf ch_PP-OCRv3_rec_infer.tar
重新安装paddle版本,不安装后面的步骤会报错。
pip install paddlepaddle==2.4.0
# 转换检测模型
python -m paddle_serving_client.convert --dirname ./ch_PP-OCRv3_det_infer/ --model_filename inference.pdmodel --params_filename inference.pdiparams --serving_server ./ppocr_det_v3_serving/ --serving_client ./ppocr_det_v3_client/
python -m paddle_serving_client.convert --dirname ./ch_PP-OCRv3_rec_infer/ --model_filename inference.pdmodel --params_filename inference.pdiparams --serving_server ./ppocr_rec_v3_serving/ --serving_client ./ppocr_rec_v3_client/操作完之后会生成如下四个文件:
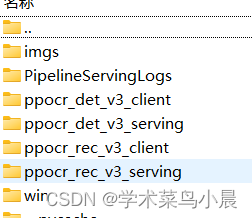
后台程序运行:
# 运行日志保存在log.txt
python web_service.py --config=config.yml &>/home/log.txt &三、服务测试
1.后台测试(服务器上测试)
# 测试 该命令会检测/home/PaddleOCR/doc/imgs下所有图片进行文字识别
python pipeline_http_client.py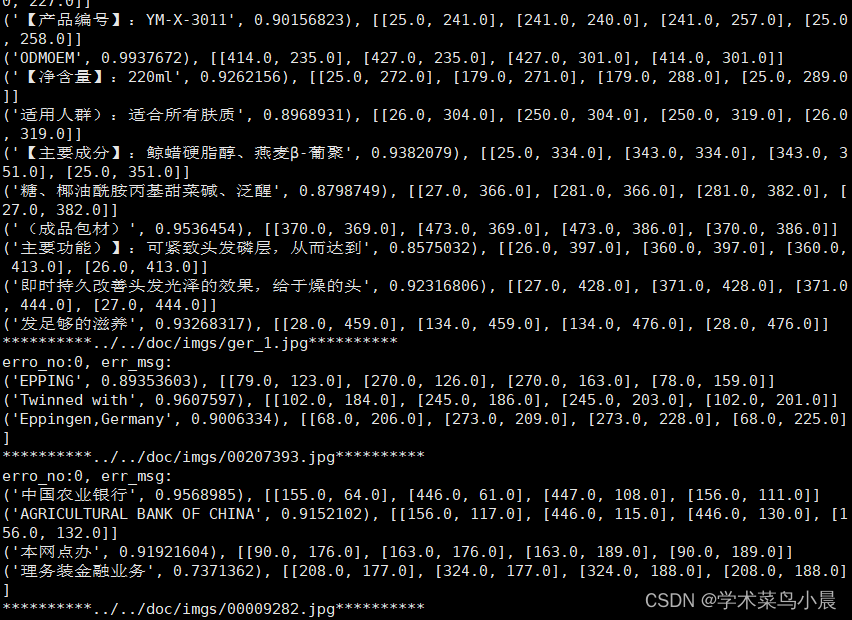
2.http接口测试(本地访问服务器测试)
2.1.python代码测试
注意:xxxx改成你自己服务器的ip
import requests
import base64
import cv2
import json
url = "http://xxxxxxxx:9998/ocr/prediction"
img_file = 'test/1.jpg'
def get_ocr_resultby_http(image):
'''
:param image:
:return:
'''
success,encoded_image = cv2.imencode(".jpg",image)#转成二进制
#将数组转为bytes
byte_data = encoded_image.tobytes()
base64_image = base64.b64encode(byte_data).decode('utf8')
data = {"key": ["image"], "value": [base64_image]}
response = requests.post(url=url,data=json.dumps(data))
ocr_result = eval(response.json()['value'][0])
ocr_result = [[x[1],x[0]] for x in ocr_result]
print(ocr_result)
return ocr_result
image = cv2.imread(img_file)
get_ocr_resultby_http(image )
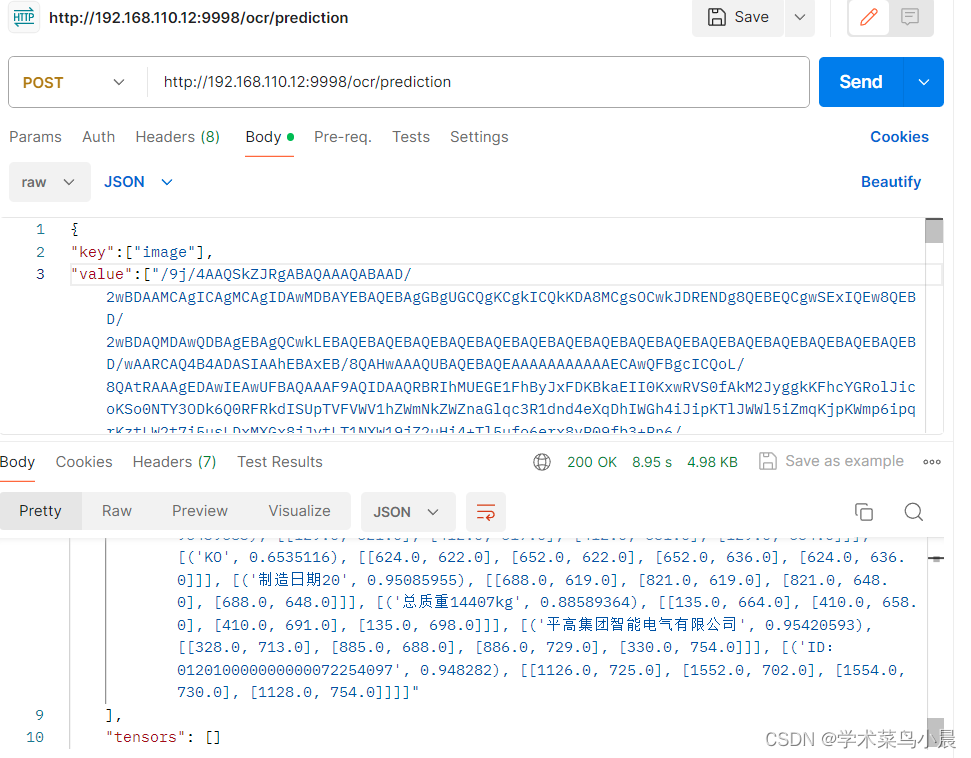
2.2. postman访问测试
1.打开postman。
2.使用 POST 请求。
3.在 Body 中以正确的格式发送数据:
4.选择 raw 并选择 JSON。
JSON 应该如下所示:
{
"key": ["image"],
"value": ["Base64编码的图像"]
}
Base64 编码注意事项:
确保在将图像转换为 Base64 编码时不包含任何前缀(如 data:image/jpeg;base64,)。使用纯粹的 Base64 字符串。



















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











