






大模型地址
 https://github.com/salesforce/CodeT5
https://github.com/salesforce/CodeT5步骤
本次部署在远程服务器NVIDIA GeForce RTX 3090上进行。
cuda版本为11.3。
创建虚拟环境
设置python版本为3.8。
conda create -n codeT5_py38 python=3.8选取模型
由项目可知,提供了不同大小的模型。由于服务器限制,先尝试部署 codet5p-770m 模型。
- CodeT5+
110Membedding model: codet5p-110m-embedding.🔥- CodeT5+
220Mbimodal model: codet5p-220m-bimodal.🔥- CodeT5+
220Mand770M: codet5p-220m and codet5p-770m.- CodeT5+
220Mand770Mthat are further tuned on Python subset: codet5p-220m-py and codet5p-770m-py.- CodeT5+
2B,6B,16B: codet5p-2b, codet5p-6b, and codet5p-16b.- InstructCodeT5+
16B: instructcodet5p-16b.
安装相应的包
pytorch
经过多次尝试,选择以下版本的pytorch进行安装(版本太高,与cuda不兼容):
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 -f https://download.pytorch.org/whl/torch_stable.html
transformer
- 正常pip安装,在测试大模型时报错:
ValueError: Tokenizer class CodeGenTokenizer does not exist or is not currently imported.
查阅网址后发现,要用pip install git下载最新的transformer4.40.0.dev0:pip install git+https://github.com/huggingface/transformers- 根据github原文,要pip install transformer==4.21.3
部署770M模型
项目中给出的示例代码如下:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import torch
checkpoint = "Salesforce/instructcodet5p-16b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
trust_remote_code=True).to(device)
encoding = tokenizer("def print_hello_world():", return_tensors="pt").to(device)
encoding['decoder_input_ids'] = encoding['input_ids'].clone()
outputs = model.generate(**encoding, max_length=15)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))由于国内网络限制,这样并不能成功连接到Hugging Face。这里提供一个国内的镜像:国内HF
,将该网址设为环境即可实现上述模型部署:
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
import torch
# 测试CodeT5+ 770M
checkpoint = "Salesforce/codet5p-770m" # 定义了一个路径 checkpoint,指向一个预训练模型的本地目录
# checkpoint = "Salesforce/codet5p-2b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
# 从指定的 checkpoint 加载一个自动分词器(tokenizer)。这个分词器会用于将文本转换为模型可以理解的数字表示形式。
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
# 从 checkpoint 加载一个序列到序列的学习模型(AutoModelForSeq2SeqLM)。这个模型是一个自动模型,它可以处理序列到序列的任务,例如机器翻译或代码生成。
model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint,
torch_dtype=torch.float16,
trust_remote_code=True).to(device)
# model = AutoModelForSeq2SeqLM.from_pretrained(checkpoint, trust_remote_code=True).to(device)
encoding = tokenizer("def print_hello_world():", return_tensors="pt").to(device)
encoding['decoder_input_ids'] = encoding['input_ids'].clone()
outputs = model.generate(**encoding, max_length=15)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
注:
- os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"必须放在import transformers之前
-
checkpoint不能写错
-
此时运行会显示:
(codaT5_py38) hadoop@R740:/home/zzzzzsn/code_t5$ python test2.py tokenizer_config.json: 1.34kB [00:00, 97.7kB/s] vocab.json: 511kB [00:00, 1.61MB/s] merges.txt: 294kB [00:00, 1.66MB/s] tokenizer.json: 1.37MB [00:00, 7.42MB/s] added_tokens.json: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 59.0/59.0 [00:00<00:00, 4.99kB/s] special_tokens_map.json: 1.03kB [00:00, 462kB/s]如果出错,可以尝试等待一段时间再下载。
补充:HuggingFace模型下载地址
通过Hugging Face的Transformers库自动下载模型,会先缓存在默认路径:
Linux:
~/.cache/huggingface/hub
Windows :C:\Users\username\.cache\huggingface\hub
在创建的Python虚拟环境中安装,该命令可以查询已经安装的大模型,删除不用或者下载失败的大模型:
pip install huggingface_hub["cli"]执行命令:
huggingface-cli delete-cache #此命令也可以用来查看已经缓存的模型列表。
此时终端可以看见已经下载好的大模型:
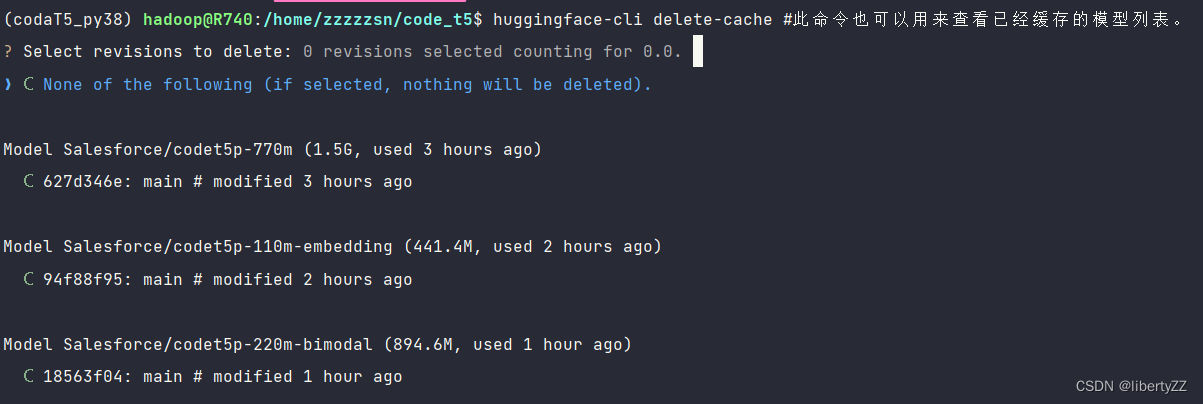
选择想要的操作:
- 按键盘
↑方向键和↓方向键移动光标。 - 按
<space>(空格键)切换(选择/取消选择)项目,可以多选。 - 按
<Enter>(回车)确认选择。 - 要取消操作并退出,按
<ctrl+c>退出 。
部署 CodeT5+ 110M embedding + CodeT5+ 220M bimodal model
同理。
测试
输出成功:

embedding 和 bimodal 输出成功:
指令微调
下载数据库
按照官方手册,使用code_alpaca_20k.json。
指令微调
在终端输入:
MODEL=Salesforce/codet5p-16b
SAVE_DIR=saved_models/instructcodet5p-16b
deepspeed instruct_tune_codet5p.py \
--load $MODEL --save-dir $SAVE_DIR --instruct-data-path code_alpaca_20k.json \
--fp16 --deepspeed deepspeed_config.json几个注意点
-
安装deepspeed:
pip install deepspeed
- 安装datasets:
pip install datasets
- 修改终端指令
- 增加指令(否则报错:[Errno 101] Network is unreachable)
- export HF_ENDPOINT=https://hf-mirror.com
- 修改
- MODEL=Salesforce/codet5p-770m
- SAVE_DIR=saved_models/instructcodet5p-770m
- 修改--instruct-data-path ,改为自己放code_alpaca_20k.json的地址
- 增加指令(否则报错:[Errno 101] Network is unreachable)
- instruct_tune_codet5p.py
-
freeze_decoder_except_xattn_codegen函数,这种调整主要和
T5Stack结构(T5模型结构参考)有关(报错'T5Config' object has no attribute 'n_layer'等):-
num_decoder_layers = model.decoder.config.n_layer改为 model.decoder.config.num_layers
-
each_decoder_layer = model.decoder.transformer.h[i]改为model.decoder.block[i]
-
-
最终在终端输入:
export HF_ENDPOINT=https://hf-mirror.com
MODEL=Salesforce/codet5p-770m
SAVE_DIR=saved_models/instructcodet5p-770m
deepspeed instruct_tune_codet5p.py \
--load $MODEL --save-dir $SAVE_DIR --instruct-data-path code_alpaca_20k.json \
--fp16 --deepspeed deepspeed_config.json成功启动
Loading extension module cpu_adam...
Time to load cpu_adam op: 29.905631065368652 seconds
Loading extension module cpu_adam...
Time to load cpu_adam op: 29.94956922531128 seconds
0%| | 1/1875 [00:07<3:42:44, 7.13s/it]tried to get lr value before scheduler/optimizer started stepping, returning lr=0
结果输出
发现final_checkpoint不完整:
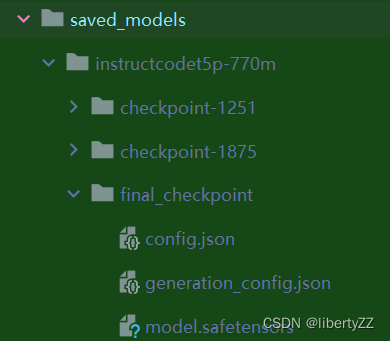
尝试重复上述微调,观察结果。不是不完整,是格式不同。
safetensors 和 bin 的区别
bin 是通用的二进制存储文件,safetensors 是更加安全的文件,专门存储张量数据,这两者都可以存模型的参数。
- 设置保存的时候使用的格式
-
model.save_pretrained() 方法里面的 safe_serialization 设置成 True 的话,就会用 safetensors 格式
-
不同 transformers 版本的该方法的 safe_serialization 的默认值是不同的(较新的版本该值默认为 True,较老的为 False)
-
将 instruct_tune_codet5p中model.save_pretrained(final_checkpoint_dir)改为 model.save_pretrained(final_checkpoint_dir, safe_serialization=False)。
此时成功输出bin文件,但是只保存了generation_config.json、pytorch_model.bin和config.json文件:
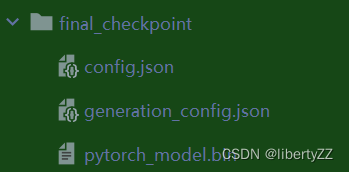
Tokenizer配置
如果checkpoint只保存了config.json、pytorch_model.bin和generation_config.json文件,那么可能没有保存完整的Tokenizer配置。
在这种情况下,需要从原始的预训练模型中获取Tokenizer配置。将原始模型中的Tokenizer配置复制过来:
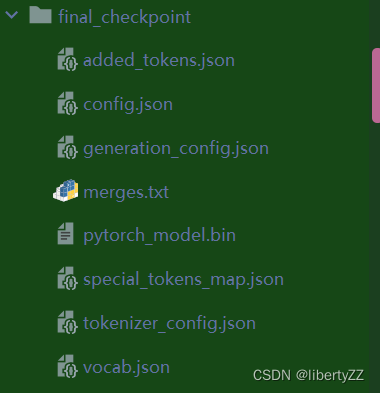
HumanEval
- 安装HumanEval repo
过程
原文给的代码:
model=instructcodet5p-16b
temp=0.2
max_len=800
pred_num=200
num_seqs_per_iter=2 # 25 for 350M and 770M, 10 for 2B, 8 for 6B, 2 for 16B on A100-40G
output_path=preds/${model}_T${temp}_N${pred_num}
mkdir -p ${output_path}
echo 'Output path: '$output_path
echo 'Model to eval: '$model
# 164 problems, 21 per GPU if GPU=8
index=0
gpu_num=8
for ((i = 0; i < $gpu_num; i++)); do
start_index=$((i * 21))
end_index=$(((i + 1) * 21))
gpu=$((i))
echo 'Running process #' ${i} 'from' $start_index 'to' $end_index 'on GPU' ${gpu}
((index++))
(
CUDA_VISIBLE_DEVICES=$gpu python generate_codet5p.py --model ${model} \
--start_index ${start_index} --end_index ${end_index} --temperature ${temp} \
--num_seqs_per_iter ${num_seqs_per_iter} --N ${pred_num} --max_len ${max_len} --output_path ${output_path}
) &
if (($index % $gpu_num == 0)); then wait; fi
done根据本机进行修改:
- model=/code_t5/CodeT5+/saved_models1/instructcodet5p-770m/final_checkpoint
- num_seqs_per_iter=25
-
gpu_num=2
-
因为只用2个GPU:
-
for ((i = 0; i < $gpu_num; i++)); do
start_index=$((i * 82))
end_index=$(((i + 1) * 82))
-
-
--model
Salesforce/${model}model=/home/zzzzzsn/code_t5/CodeT5+/saved_models2/instructcodet5p-770m/final_checkpoint temp=0.2 max_len=800 pred_num=200 num_seqs_per_iter=25 # 25 for 350M and 770M, 10 for 2B, 8 for 6B, 2 for 16B on A100-40G output_path=${model}_T${temp}_N${pred_num} mkdir -p ${output_path} echo 'Output path: '$output_path echo 'Model to eval: '$model # 164 problems, 21 per GPU if GPU=8 index=0 gpu_num=2 for ((i = 0; i < $gpu_num; i++)); do start_index=$((i * 82)) end_index=$(((i + 1) * 82)) gpu=$((i)) echo 'Running process #' ${i} 'from' $start_index 'to' $end_index 'on GPU' ${gpu} ((index++)) ( CUDA_VISIBLE_DEVICES=$gpu python generate_codet5p.py --model ${model} \ --start_index ${start_index} --end_index ${end_index} --temperature ${temp} \ --num_seqs_per_iter ${num_seqs_per_iter} --N ${pred_num} --max_len ${max_len} --output_path ${output_path} ) & if (($index % $gpu_num == 0)); then wait; fi done
修改完执行,成功:
100% 21/21 [1:52:31<00:00, 321.51s/it]
[1]- Done ( CUDA_VISIBLE_DEVICES=$gpu python generate_codet5p.py --model ${model} --start_index ${start_index} --end_index ${end_index} --temperature ${temp} --num_seqs_per_iter ${num_seqs_per_iter} --N ${pred_num} --max_len ${max_len} --output_path ${output_path} )
[2]+ Done ( CUDA_VISIBLE_DEVICES=$gpu python generate_codet5p.py --model ${model} --start_index ${start_index} --end_index ${end_index} --temperature ${temp} --num_seqs_per_iter ${num_seqs_per_iter} --N ${pred_num} --max_len ${max_len} --output_path ${output_path} )
生成164个json文件(数量和使用GPU个数有关)。
Pass@k
output_path=preds/instructcodet5p-16b_T0.2_N200
echo 'Output path: '$output_path
python process_preds.py --path ${output_path} --out_path ${output_path}.jsonl
evaluate_functional_correctness ${output_path}.jsonl- output_path改为 生成164个json文件 对应位置
运行成功:



















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









